BGE
前言
- Foundation Model有两个代表,一个是 Large Language Model,另一个是 Embedding Model。
- 前者聚焦文本空间,其形式化功能为text -> text;后者聚焦向量空间,其功能为text -> embedding。转为向量能做些什么呢?比较常见的使用场景包括retrieval(如检索知识库、检索Tool)、clustering(聚类)、classification(分类)等。
- 在中文世界,智源研究院的 BGE 是比较有名的开源 embedding model
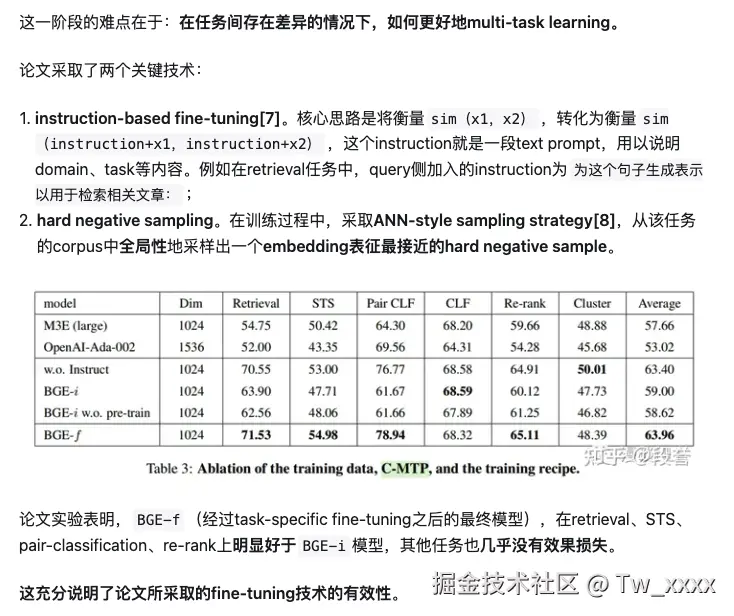
方法论
- BGE从两个方面来达成这个目标:
- 数据方面,兼顾scale、diversity、quality这三个维度,这是通用embedding模型能训练出来的前提;
- 训练策略方面,论文使用3阶段训练策略,从pre-training 到 general-purpose fine-tuning 再到 task-specific fine-tuning;前两个阶段是保证通用性的基石,最后一个阶段则在保持通用的基础上,进一步精进下游任务的效果。
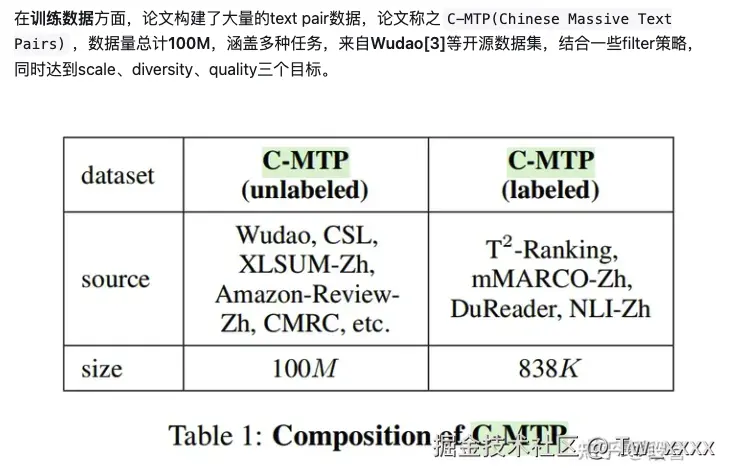
数据方面
模型方面
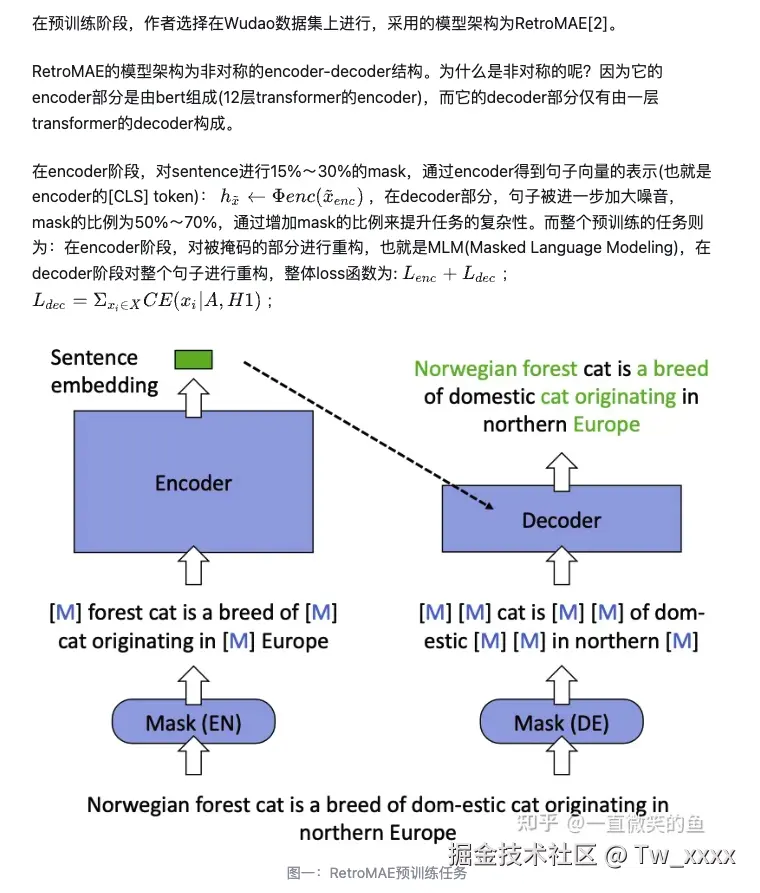

训练方面
- pre-training 阶段在 Wudao Corpora上进行,此阶段未在任何pair数据上训练,其目标是训练出更适合embedding任务的pre-trained model。

- general-purpose fine-tuning阶段在C-MTP(unlabeled)上进行,该阶段在100M的text pairs上训练,可以视作一种大规模的弱监督学习过程,可初步学习出通用embedding model。
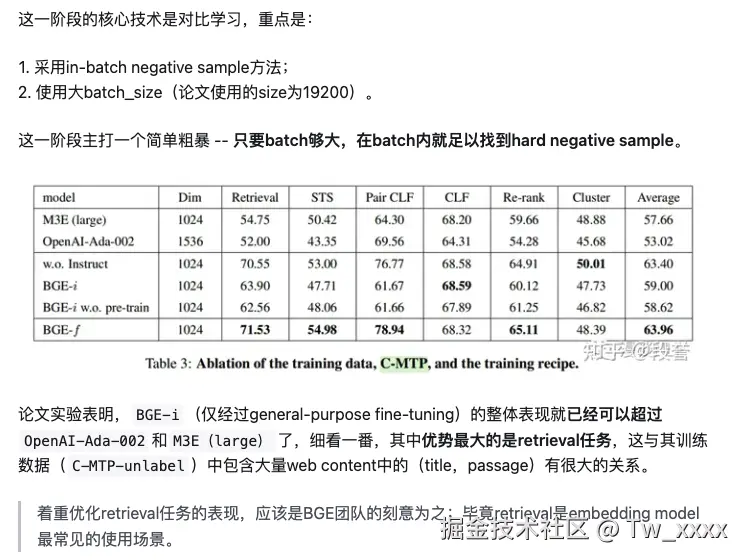
- task-specific fine-tuning阶段,在C-MTP(labeled)上进行,通过在少而精的下游任务labeled data上微调,在保证通用性的同时,强化模型在具体任务上的表现。