长文本解决方法
论文链接
概述
- 尽管LLMs在推动人工智能方向上取得了显著成就,但在处理长文本方面仍面临资源限制和效率问题。
- 提出了一系列针对长文本优化的Transformer架构改进方法,包括高效的注意力机制、长期记忆处理、外推位置编码(PEs)和上下文处理策略。
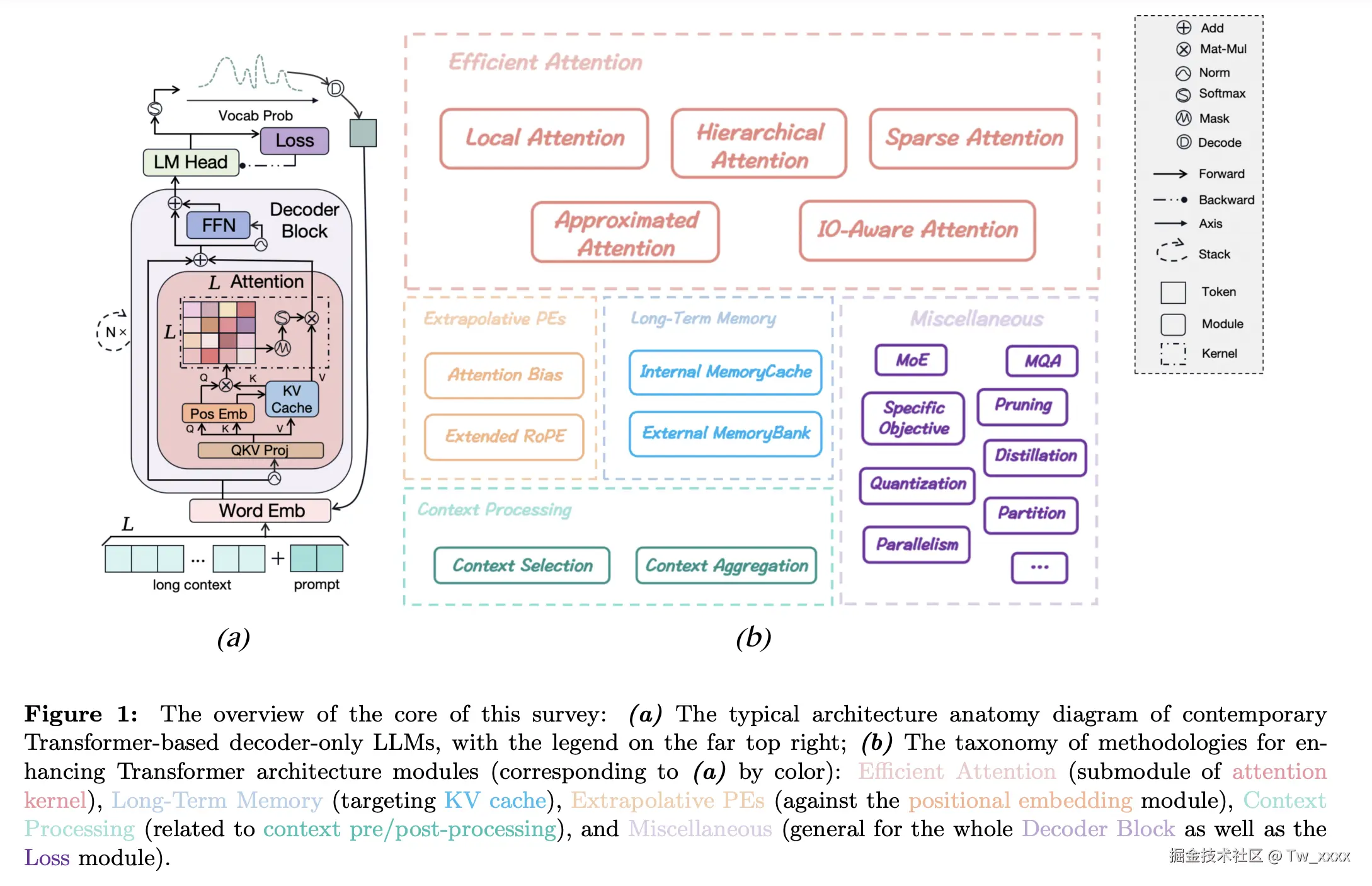
方法
高效注意力机制 (Efficient Attention)
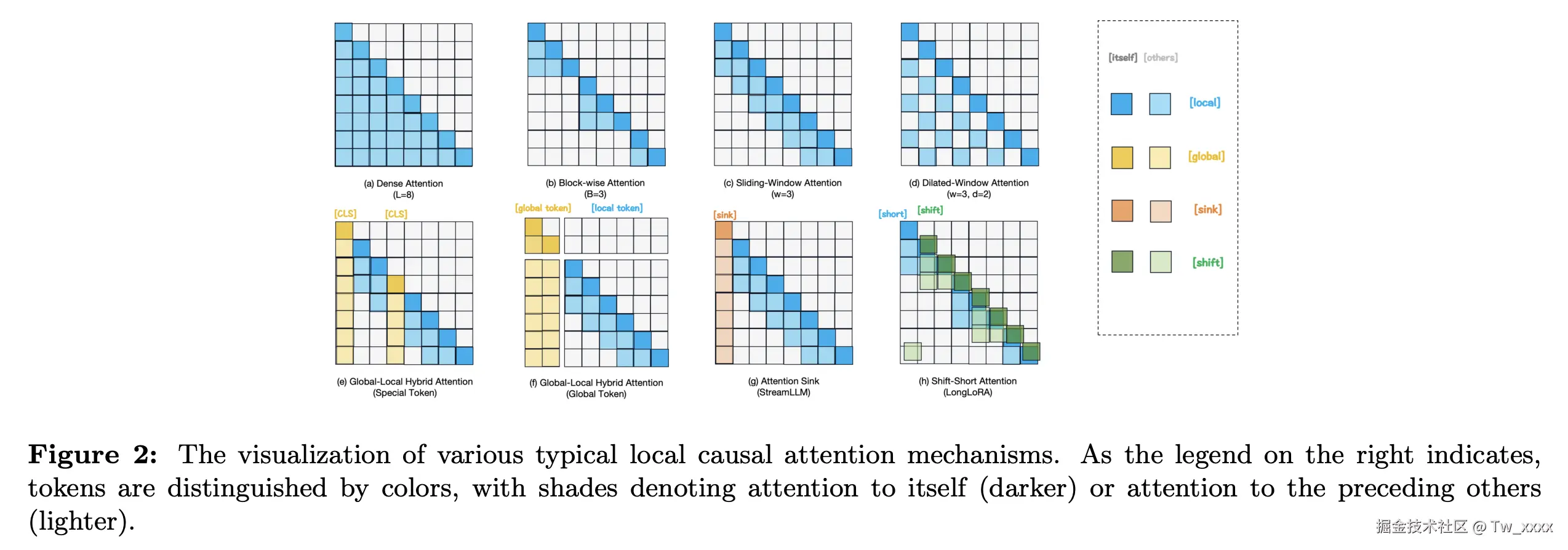
- 局部注意力 (Local Attention):讨论了如何通过聚焦局部信息来提高处理效率。例如:Block-wise Attention、Sliding Window Attention、Global-Local Hybrid Attention、LSH Attention。
- 层次化注意力 (Hierarchical Attention):介绍了通过构建层次结构来有效管理长文本信息的方法。例如:Two-Level Hierarchy、Multi-Level Hierarchy。
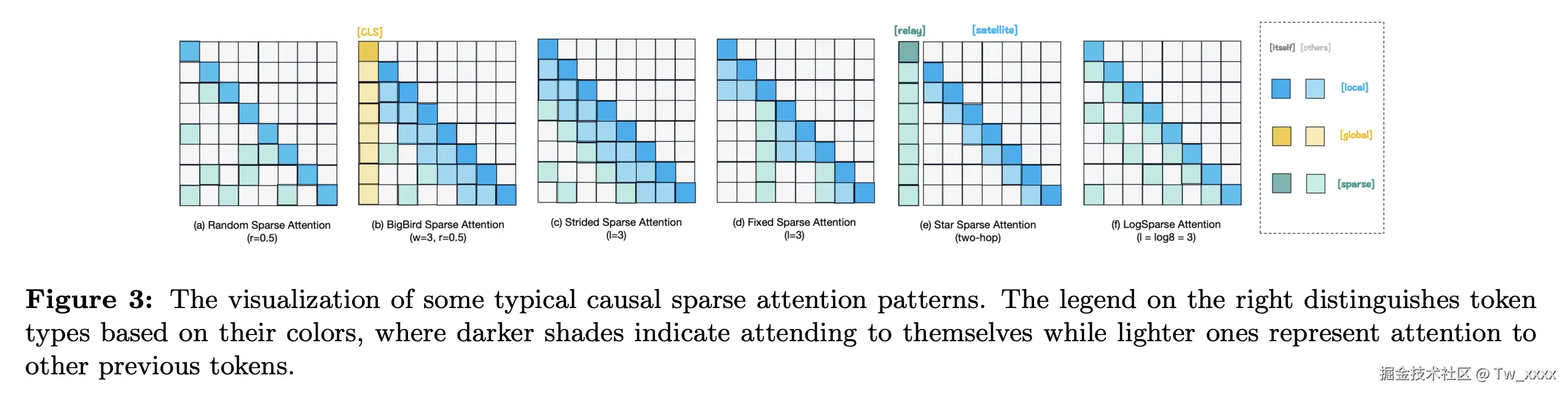
- 稀疏注意力 (Sparse Attention):探讨了如何通过减少计算需求来处理更长的序列。例如:Fixed Sparsity Patterns、Adaptive Sparsity Patterns、Graph Sparsification。
- 近似注意力 (Approximated Attention):分析了通过近似计算来降低复杂度的策略。例如:Low-Rank Approximation、Nested Attention、
Kernelized Approximation、Sparse-Kernelized Hybrid。
- 输入输出感知注意力 (IO-Aware Attention):讨论了根据输入和输出的特性调整注意力机制的方法。例如:Memory-Efficient Attention、Flash Attention、SCFA、Paged Attention。
长期记忆 (Long-Term Memory)
- 内部记忆缓存 (Internal MemoryCache):探讨了如何在模型内部存储和访问长期信息。例如:Segment-Level Recurrence、Retrospective Recurrence、Continuous-Signal Memory、Alternate Cache Designs。
- 外部记忆库 (External MemoryBank):分析了利用外部存储来扩展模型记忆能力的方法。例如:Cosine-Based Retrieval Criteria、Heuristic Retrieval Criteria、Learnable Retrieval Criteria。
外推位置编码 (Extrapolative PEs)
- 增强理解 (Enhancing Understanding):讨论了位置编码在提高模型对长文本理解的重要性。
- 注意力偏置 (Attention Bias):分析了位置编码如何影响模型的注意力分配。
- 扩展RoPE (Extended RoPE):介绍了一种新的位置编码方法,用于更好地处理长距离依赖。
上下文处理 (Context Processing):
- 上下文选择 (Context Selection):探讨了如何从长文本中选择相关信息的策略。
- 上下文聚合 (Context Aggregation):分析了如何综合长文本中的信息以提高模型的理解能力。
BERT长文本的的常用解决方案
- Clipping(截断法):简单粗暴,但是容易丢失序列信息。一般使用在文本不是特别长的场景。
- head截断:从文本开头直到限制的字数;
- tail截断:从结尾开始往前截断;
- head + tail 截断:开头和结尾各保留一部分,比例参数是一个可以调节超参数;
- Pooling(池化法):性能较差,原来截断法需要encode一次,Pooling法需要encode多次,篇章越长,速度越慢。segment之间的联系丢失,可能会出badcase。
- 对于长文档用 sliding window 切片,独立放进去 BERT 得到 cls 的表示,所有cls再进行池化融合。
- 划窗法:主要用于阅读理解任务。不能在任务上微调 BERT,因为损失是不可微的;即使存在重叠,也会错过每个段之间的一些共享信息。
- 切分:将原始样本以固定窗口大小的滑动窗口进行采样构造得到多个子样本;
- 训练模型:然后将这些子样本作为训练集来训练模型;
- 推理:在推理阶段通过 BERT 运行每个段,以获得分类 logits;
- 通过组合(每段一个),我们可以得到一个平均值,我们将其作为最终分类。
- 压缩法:选取“精华”,去除“糟粕”。断句之后整个篇章分割成segment,通过规则或者训练一个小模型,将无意义的segment进行剔除。
- RNN(循环法):BERT之所以会有最大长度的限制,是因为其在进行预训练的时候就规定了最大的输入长度,而对于类RNN的网络来讲则不会有句子长度的限制。但RNN相较于 Transformer 来讲最大问题就在于效果不好;
- 对数据进行有重叠的分割. 这样分割后的每句句子之间仍然保留了一定的关联信息
- 利用 Bert 做 特征提取得到 embedding
- 利用 LSTM + FC 做分类


