

Intro
开发框架
-
-
整个框架分为三部分
-
数据源
- 非结构化数据
- 结构化数据
-
LLM应用
-
用户层 -- Client or Browser
-
核心实现机制:
5步核心流程如下:
-
- Loading(加载) 首先,需要将文档加载到系统中。文档可能来自各种来源,例如URL、PDF文件、数据库等。LangChain提供了多种加载器(Loader)可以处理不同格式的文档,将它们转化为模型能够处理的格式。此步骤的目标是收集并读取所有相关文档,并将它们转换为标准化的文本格式,便于后续处理。
-
- Splitting(切分) 在这一阶段,系统会将加载的文档进行切分。通常,文档会被分成更小的片段(称为“文档块”或“文档切片”)。切分的粒度取决于具体应用需求,可以是段落、句子,甚至是更小的文本块。分割的目的是为了便于后续的向量化处理,同时在检索时可以更精准地找到与查询相关的小段文本。
-
- Storage(存储) 将分割好的文档切片转换为向量(Embedding)并存储到向量数据库(Vector DB)中。向量化的过程是将每个切片用模型转化为一个高维向量,表示该文本的语义信息。通过存储向量表示,可以为后续的检索步骤提供支持,以实现高效的相似度查询。
-
- Retrieval(检索) 当用户输入查询(Query)后,系统会在向量数据库中检索与查询最相似的文档切片。检索是通过计算查询向量与存储向量之间的相似度(如余弦相似度或欧氏距离)来实现的。找到与查询最相关的切片后,系统将这些切片作为上下文,提供给语言模型,用以生成回答。
-
- Output(输出) 在最后一步,系统将用户的问题和检索到的相关文档切片作为提示(Prompt),输入到大型语言模型(LLM)中。LLM结合这些上下文信息生成回答,并输出给用户。这样,系统能够给出一个与查询相关的、基于文档信息的回答。
Token and Character
在 NLP 领域,字符(character) 和 token(标记) 是两个不同的概念,尤其在大型语言模型(LLM)中,理解它们的区别非常重要。
-
字符(Character)
- 定义:字符是文本的最小组成单位,例如字母、数字、符号等。在英文中,像
a、b、c、1、@等都是字符;在中文中,每个汉字(如 "你"、"好")都是一个字符。 - 使用:字符的计算通常用于一些基础的文本操作(如限制字符长度)和编码操作(如 Unicode)。在许多文本分割工具中,参数
chunk_size使用的是字符数。
- 定义:字符是文本的最小组成单位,例如字母、数字、符号等。在英文中,像
-
Token(标记)
- 定义:Token 是 NLP 模型在处理文本时的基本单位。根据分词方法的不同,一个 Token 可以是一个单词、一个词根、甚至是部分单词或字符的组合。 比如在英文中,
hello是一个 Token,但在一些模型中,它也可能被分为多个部分(如he和llo),尤其是使用 BPE(Byte-Pair Encoding)或 WordPiece 分词技术的模型。在中文中,每个汉字也常常被视为一个独立的 Token。 - 在 LLM 中的使用:大型语言模型(如 GPT-3)在处理文本时会将文本转化为 Token 序列。模型的输入限制通常是 Token 数,而不是字符数。例如,GPT-3 的输入限制是 4096 Tokens,而不是 4096 字符。
字符和 Token 的区别
-
数量关系:
- 在英文中,Token 通常比字符少,因为一个单词可以包含多个字符,但可能是一个 Token。
- 在中文中,由于每个汉字通常是一个 Token,因此字符数和 Token 数大致相同,但仍有例外,特别是在处理混合语言时(如中英文混合文本)。
-
模型的输入限制:
- 语言模型通常限制的是 Token 数,而不是字符数。比如,假设一个模型的最大输入限制是 2000 Tokens,那么无论字符数如何,只要不超过 2000 个 Token 都可以作为输入。
-
分词方式的差异:
- 不同的模型和分词方式会对 Token 的定义有所不同。例如,GPT-3 使用 BPE 分词,因此一些常见词会作为一个 Token,但不常见的词会被分成多个 Token。
- 字符是固定的,分词与字符数无关。
举例说明
假设句子为 "Hello, 你好",可以看到字符数和 Token 数的差异:
- 字符数:
Hello5 个字符,逗号 1 个字符,空格 1 个字符,你好2 个字符,总共 9 个字符。 - Token 数(假设使用 BPE 分词):在 GPT-3 中,
Hello可能是一个 Token,而你好中每个汉字是一个 Token,总共 4 个 Token。
在 LLM 中,字符和 Token 的区别在于:
- 字符是文本的最小单位,而Token是模型分词后的基本处理单元。
- 模型的输入限制基于 Token 数,而不是字符数,因此在使用模型时,我们通常需要关注 Token 数,而不是字符数。
Example
1 Load
- 从 langchain_community.document_loaders 中导入对应文档格式的Loader
- 再创建以 对应文档的Loader对象
- 最后通过 Loader对象 进行加载, 加载的是以page为单位的列表
import os
# 1.Load 导入Document Loaders
from langchain_community.document_loaders import PyPDFLoader
from langchain_community.document_loaders import Docx2txtLoader
from langchain_community.document_loaders import TextLoader
# 加载Documents
base_dir = r'./oneFlower' # 文档的存放目录
documents = []
for file in os.listdir(base_dir):
# 构建完整的文件路径
file_path = os.path.join(base_dir, file)
if file.endswith('.pdf'):
loader = PyPDFLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.docx'):
loader = Docx2txtLoader(file_path)
documents.extend(loader.load())
elif file.endswith('.txt'):
loader = TextLoader(file_path)
documents.extend(loader.load())
print(documents[1].page_content[10:])
-
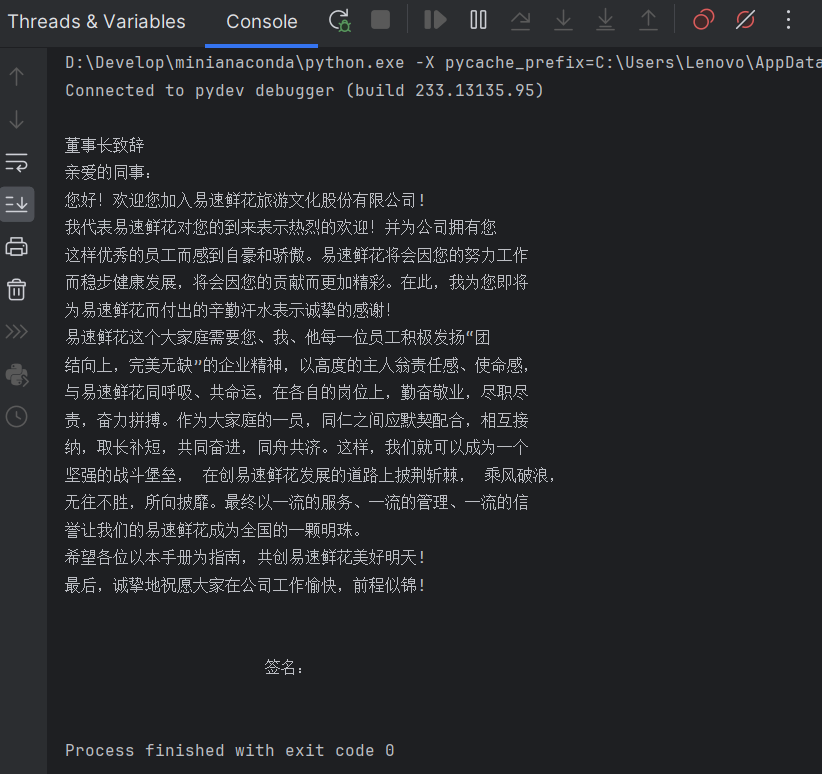
Result
-
-
以 page 为单位存储
- 例如,”员工手册.pdf“的页数为32,那么就有32个page_content
-
-
2 Split
RecursiveCharacterTextSplitter 是 LangChain 中用于将文本分割成更小块的工具,便于后续的嵌入(Embedding)和向量存储。以下是对这个函数的详细解释,包括其作用、参数和分块的原理。
作用
在许多自然语言处理(NLP)任务中,处理较长的文档会超出模型的输入限制,因此需要将文档拆分成更小的文本块。RecursiveCharacterTextSplitter 的作用就是将文本递归地分割成小块,以确保每个文本块的长度不超过指定的大小,同时保留一定的上下文信息(通过块之间的重叠)以便后续的查询匹配更准确。
分块原理
RecursiveCharacterTextSplitter 通过递归方式来分割文本。它会首先尝试按照自然的分隔符(如段落、句子等)进行分割。如果一个段落或句子超过了指定的 chunk_size,则会进一步分割,直到符合长度要求。这种递归的分割方式使得文本块尽可能保持语义连贯,有助于提高问答系统的准确性。
参数
RecursiveCharacterTextSplitter 的初始化包含一些关键参数:
-
chunk_size:- 含义:指定每个分块的最大字符数。
- 作用:定义了分块的目标大小,保证每个分块不会过长,从而避免模型输入超长的问题。
- 示例:如果
chunk_size=200,每个分块的字符数会尽量接近 200,但不会超过 200。
-
chunk_overlap:- 含义:指定相邻文本块之间的重叠字符数。
- 作用:提供上下文信息。通过使相邻的块部分重叠,模型可以更好地理解文本之间的联系。特别是在分块过程中,如果一块的内容在下一块中部分重复,那么查询时可以获得更连贯的答案。
- 示例:如果
chunk_overlap=10,则每个块的最后 10 个字符会出现在下一个块的开头。
使用示例
text_splitter = RecursiveCharacterTextSplitter(chunk_size=200, chunk_overlap=10)
chunked_documents = text_splitter.split_documents(documents)
-
text_splitter.split_documents(documents):split_documents方法用于分割传入的文档列表documents。每个文档会被分割成多个小块,并存储在chunked_documents中。- 返回值
chunked_documents是一个分块后的文档列表,每个元素都是一个独立的文本块,符合chunk_size和chunk_overlap的要求。
Result
-
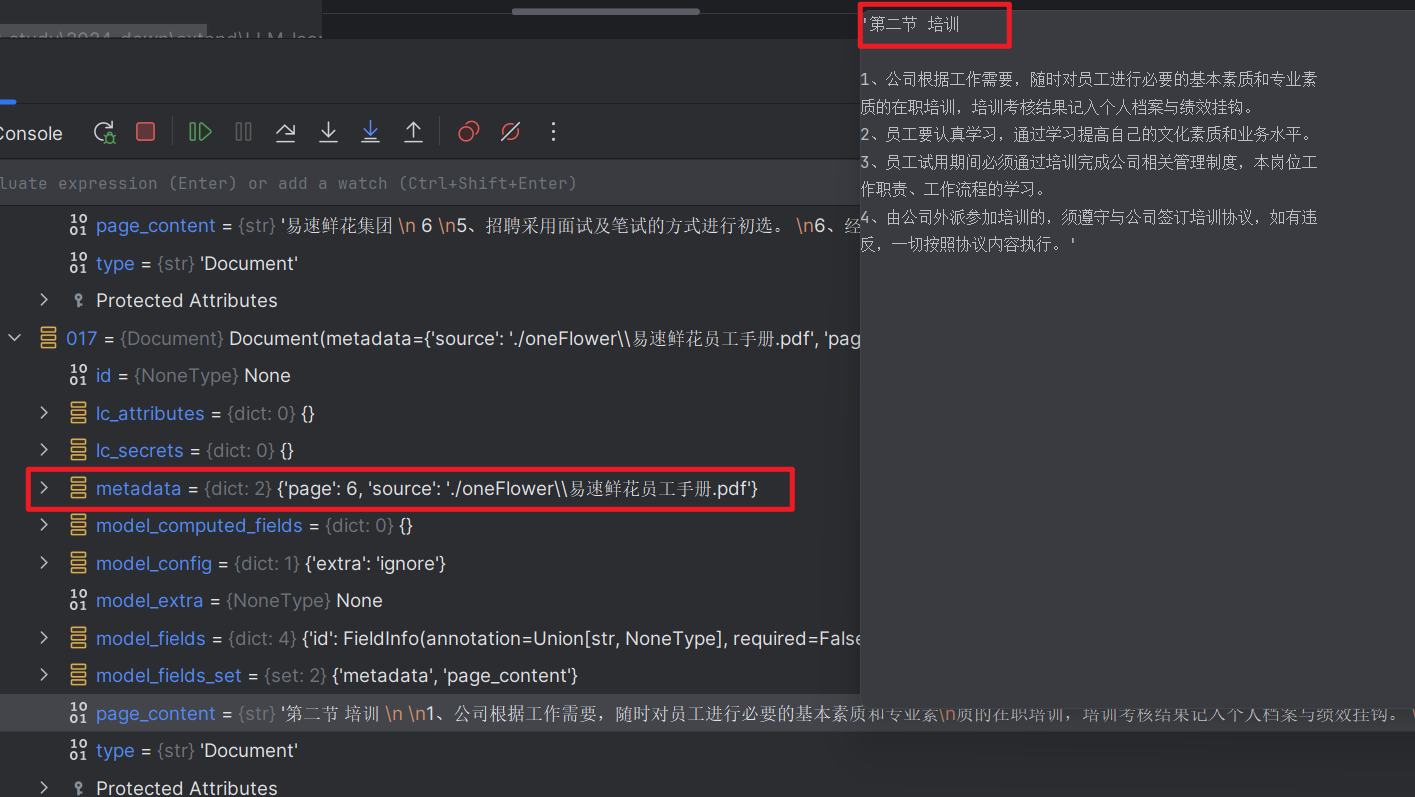
- 同一个 page 被split为多个chunk。 同时,某些上下文chunk会有部分overlap
3 Storage
- pip 相应的SDK
- Embedding使用相应的 Embedding 模型,而不是Chat模型
# 3.Store 将分割嵌入并存储在矢量数据库Qdrant中
from langchain_community.vectorstores import Qdrant
from typing import Dict, List, Any
from langchain.embeddings.base import Embeddings
# from langchain.pydantic_v1 import BaseModel
from pydantic import BaseModel
from volcenginesdkarkruntime import Ark
class DoubaoEmbeddings(BaseModel, Embeddings):
client: Ark = None
api_key: str = 'xxx',
model: str ='xxxx'
def __init__(self, **data: Any):
super().__init__(**data)
self.client = Ark(
base_url='xxx',
api_key='xxx'
)
def embed_query(self, text: str) -> List[float]:
"""
生成输入文本的 embedding.
Args:
texts (str): 要生成 embedding 的文本.
Return:
embeddings (List[float]): 输入文本的 embedding,一个浮点数值列表.
"""
embeddings = self.client.embeddings.create(model=self.model, input=text)
return embeddings.data[0].embedding
def embed_documents(self, texts: List[str]) -> List[List[float]]:
return [self.embed_query(text) for text in texts]
class Config:
arbitrary_types_allowed = True
vectorstore = Qdrant.from_documents(
documents=chunked_documents, # 以分块的文档
embedding=DoubaoEmbeddings(
),
location=":memory:", # in-memory 存储
collection_name="my_documents",
) # 指定collection_name
4 检索
-
多询问检索器
MultiQueryRetriever -
检索QA
RetrievalQA -
检索器和QA链都需要大模型的辅助
- 检索器可利用大模型 生成多个问题变体,提高检索结果的相关性
- QA链利用 检索器检索到的上下文, 与问题一同输入LLM,模型会基于context和Problem进行回答
from langchain_openai import ChatOpenAI
from langchain.retrievers.multi_query import MultiQueryRetriever # MultiQueryRetriever工具
from langchain.chains import RetrievalQA # RetrievalQA链
# 实例化一个MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm)
# 实例化一个RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
# 实例化一个大模型工具 - OpenAI的GPT-3.5
llm = ChatOpenAI(
api_key='xxxx',
model='xxx',
base_url='xxx')
# 实例化一个MultiQueryRetriever
retriever_from_llm = MultiQueryRetriever.from_llm(retriever=vectorstore.as_retriever(), llm=llm)
# 实例化一个RetrievalQA链
qa_chain = RetrievalQA.from_chain_type(llm,retriever=retriever_from_llm)
# 5. Output 问答系统的UI实现
question = "袜子要求?"
# RetrievalQA链 - 读入问题,生成答案
result = qa_chain.invoke({"query": question})
print(result.result)
logging:用于设置日志输出,以便监控和调试程序执行的状态。
ChatOpenAI:这是 LangChain 提供的接口,用于调用 OpenAI 的聊天模型(如 gpt-3.5-turbo)。
MultiQueryRetriever:这是一个多查询检索器,可以基于多个不同的问题格式对向量数据库执行检索,以获取更相关的内容。
RetrievalQA:LangChain 提供的问答链,它通过指定检索器和语言模型,构建一个用于问答的完整链条。
MultiQueryRetriever.from_llm(...) :使用语言模型生成多个不同的问题变体,并基于这些变体执行多次检索。这样可以提高检索结果的相关性,确保返回的内容更符合查询意图。
RetrievalQA.from_chain_type(...) :创建一个问答链,将检索器和语言模型组合在一起。

