一.首先讲了课程安排
二.然后去AI练中学运行配好的代码,体验为主
1.首先在AI练中学,阅读Readme文件
a.学习了AI练中学IDE怎么用
因为项目中已经安装好了课程依赖的软件环境并预置了10k限额的免费豆包API,所以课程代码可以点击运行一键执行,不用进行任何更改.
b.在火山引擎平台注册了账号,领取了50w的模型免费调用额度.
- 先创建了账号(手机号登录)
- 然后创建了API Key
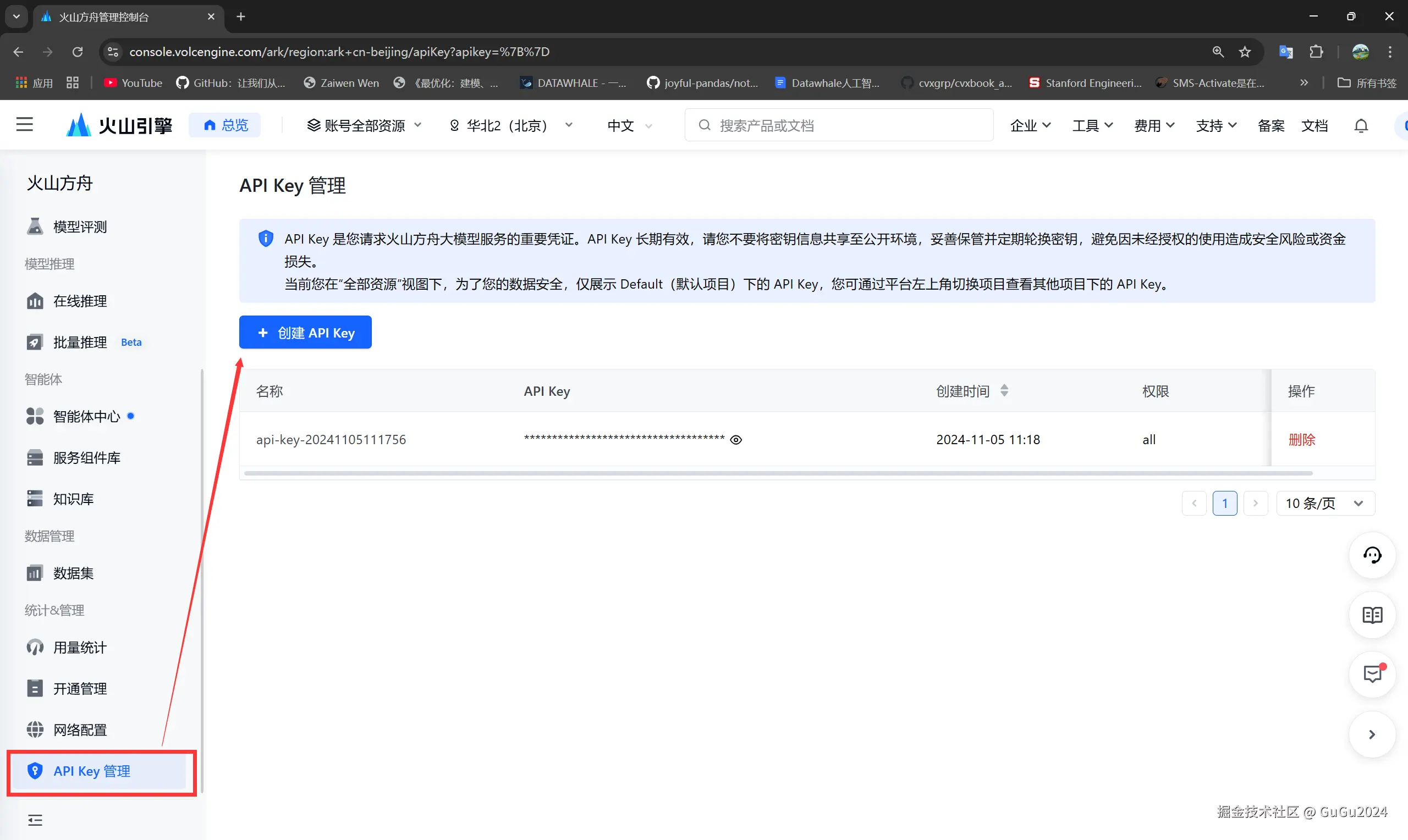
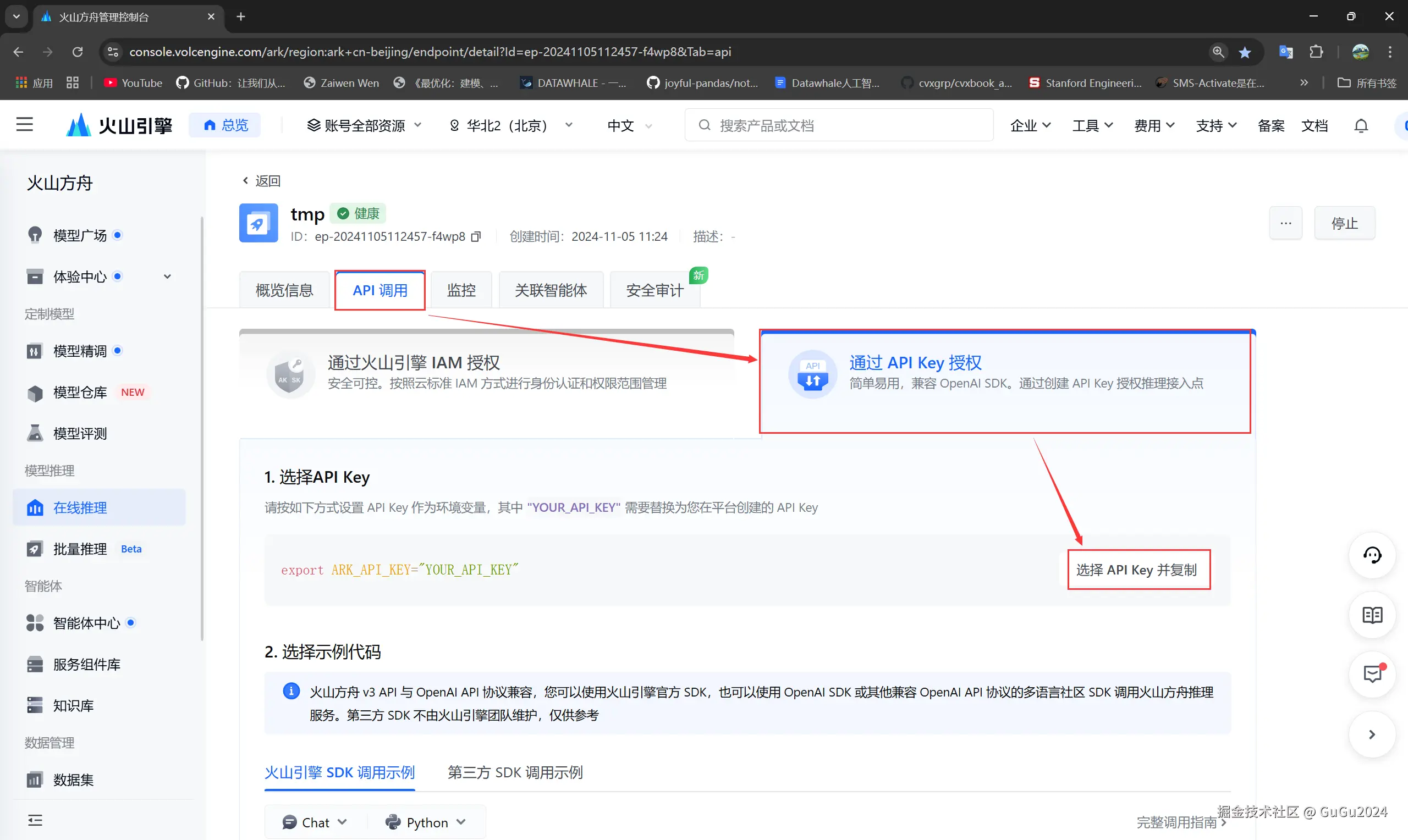
- 之后在在线推理页面中创建推理接入点,名称是随便输的,模型选的性能最好的doubao-pro-32k作为主力模型
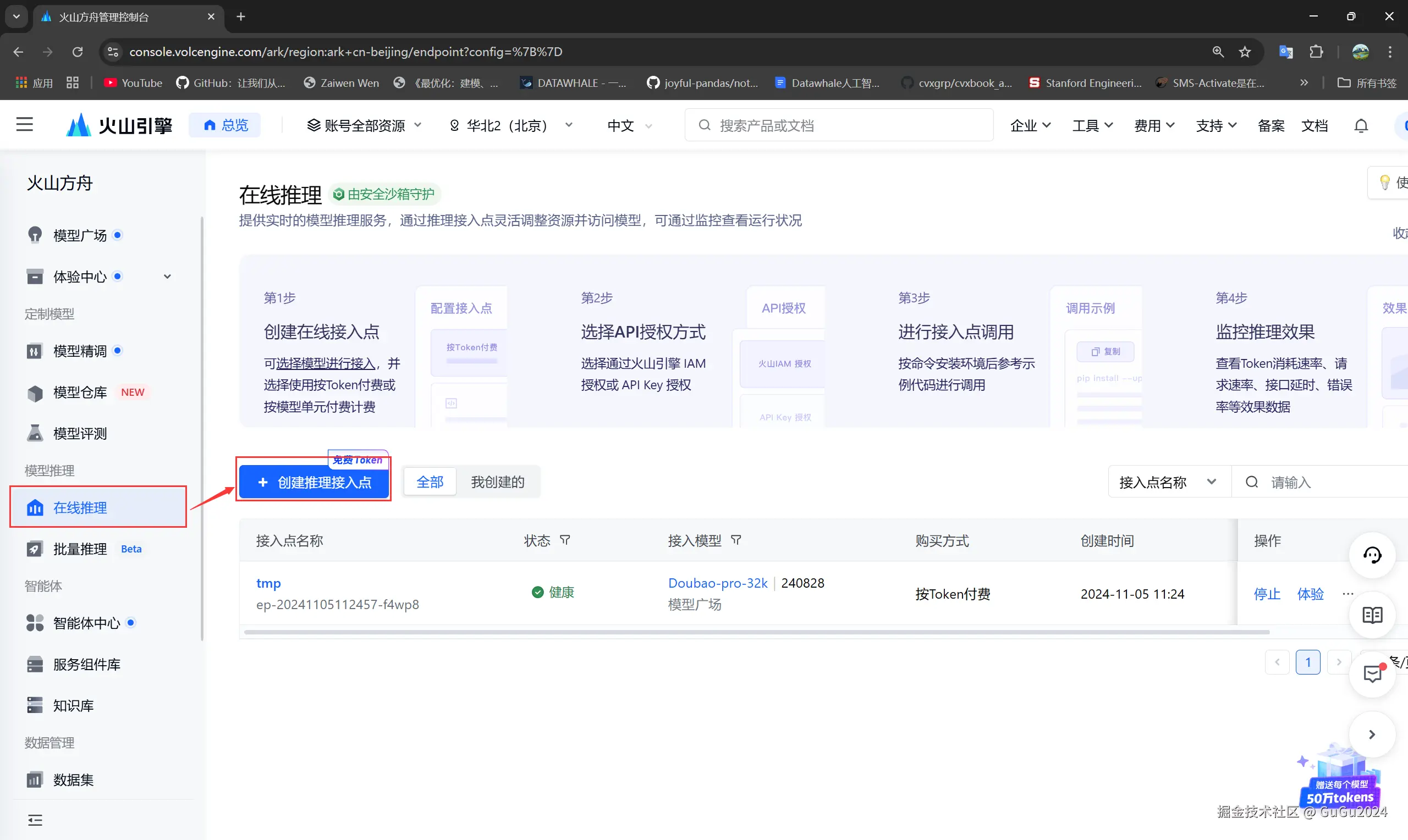
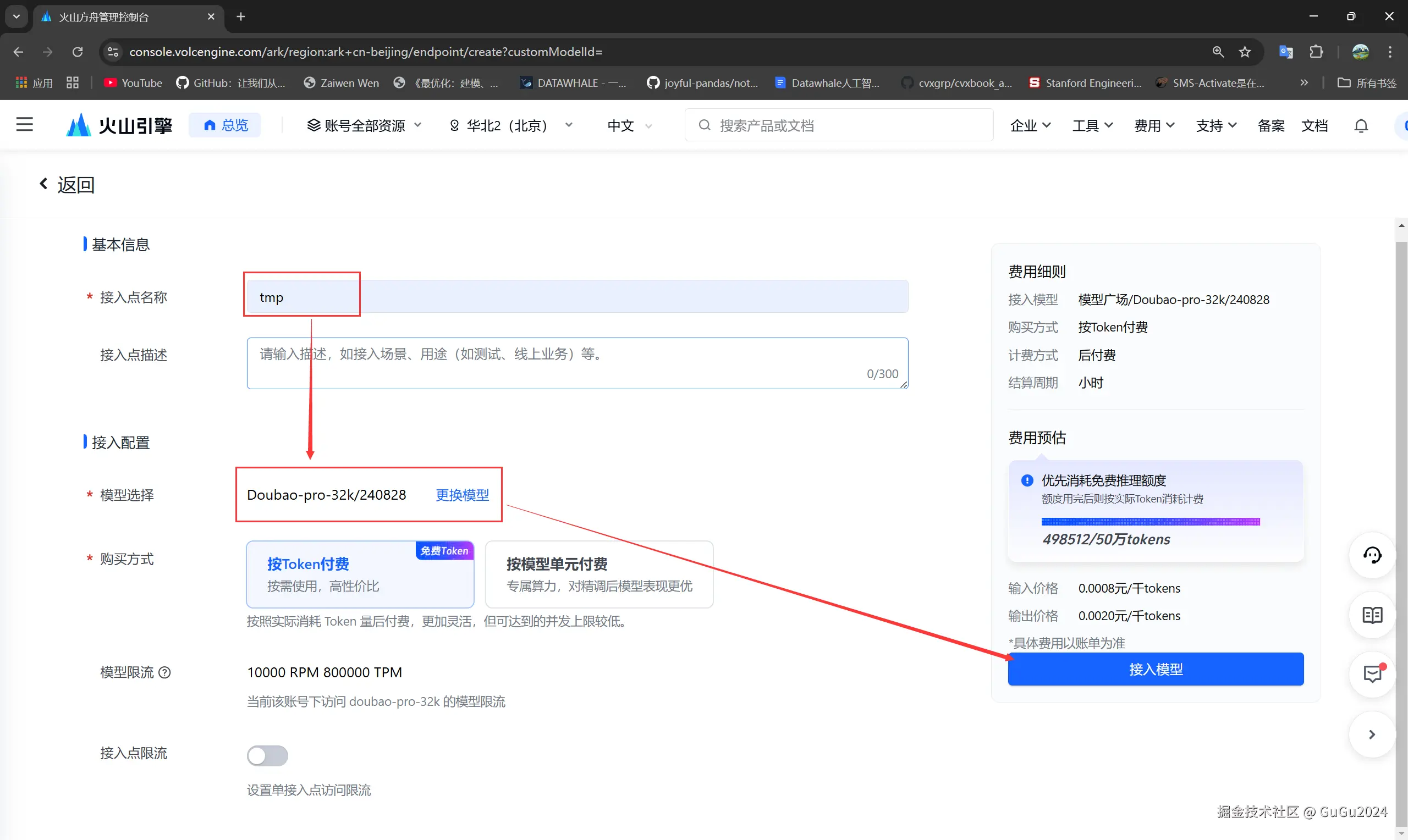
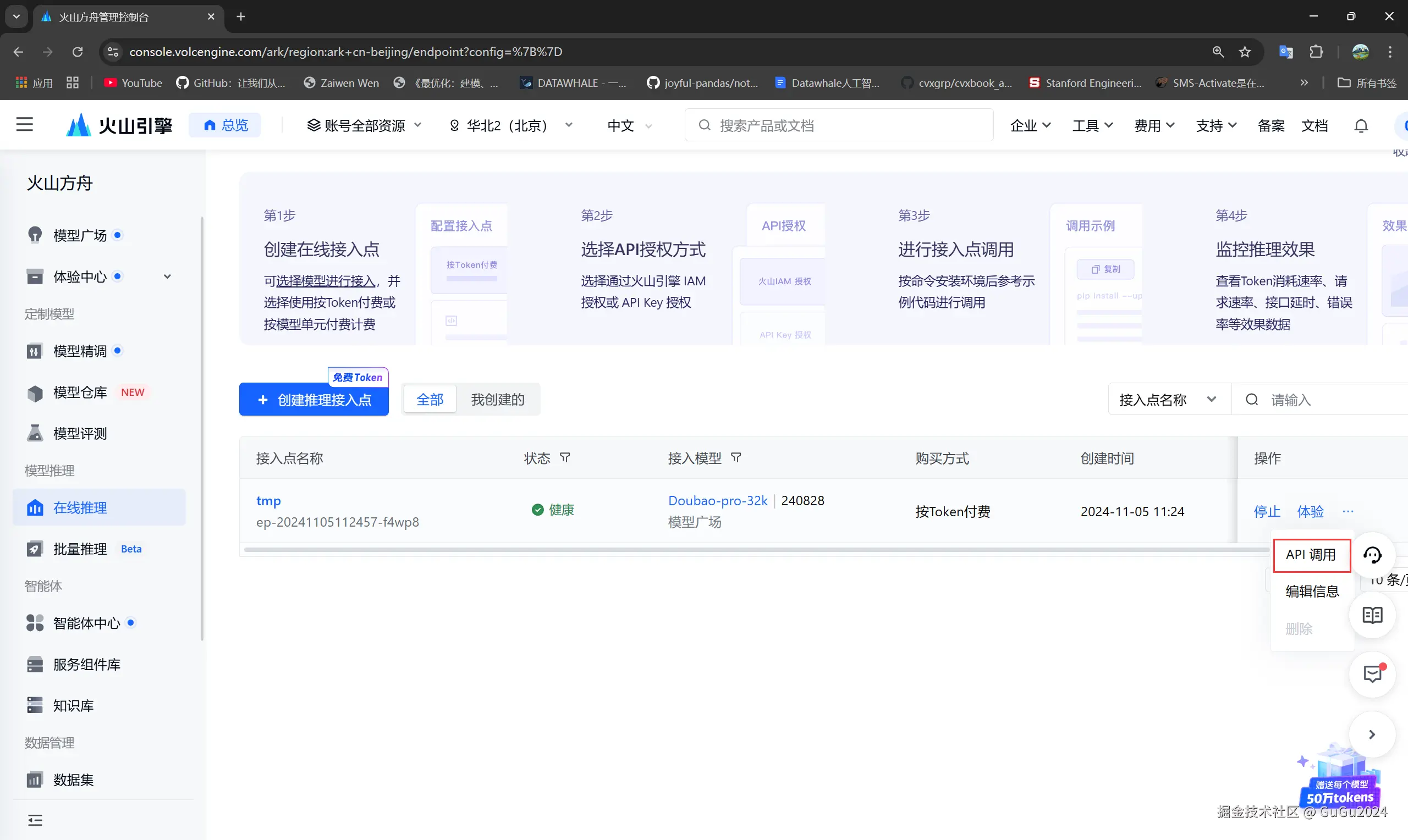
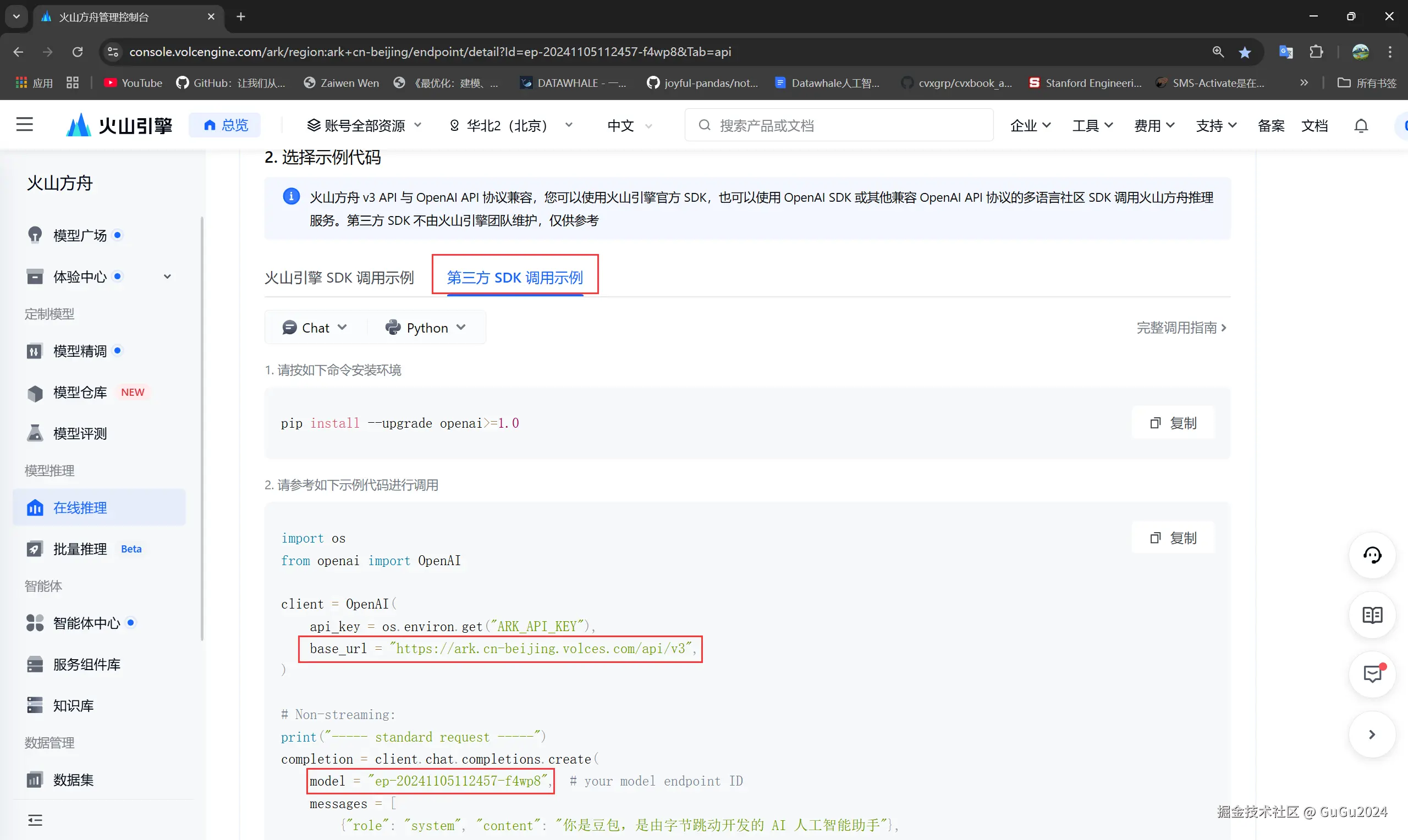
- 现在获得了模型的base_url和model_endpoint,通过
在线推理-->选择相应接入点的操作-->API调用-->第三方SDK调用示例来找到.
- 打开项目中的 /home/cloudide/.cloudiderc 文件,按之前注册获得的信息填写:
export OPENAI_API_KEY=<YOUR_API_KEY>
export OPENAI_BASE_URL=<YOUR_MODEL_BASE_URL>
export LLM_MODELEND=<YOUR_MODEL_ENDPOINT>
- 最后 Ctrl + Shift + ` 打开IDE终端,输入
source ~/.cloudiderc执行.
2.遇到的问题
a.在执行完(1.b)后出现个问题,那就是
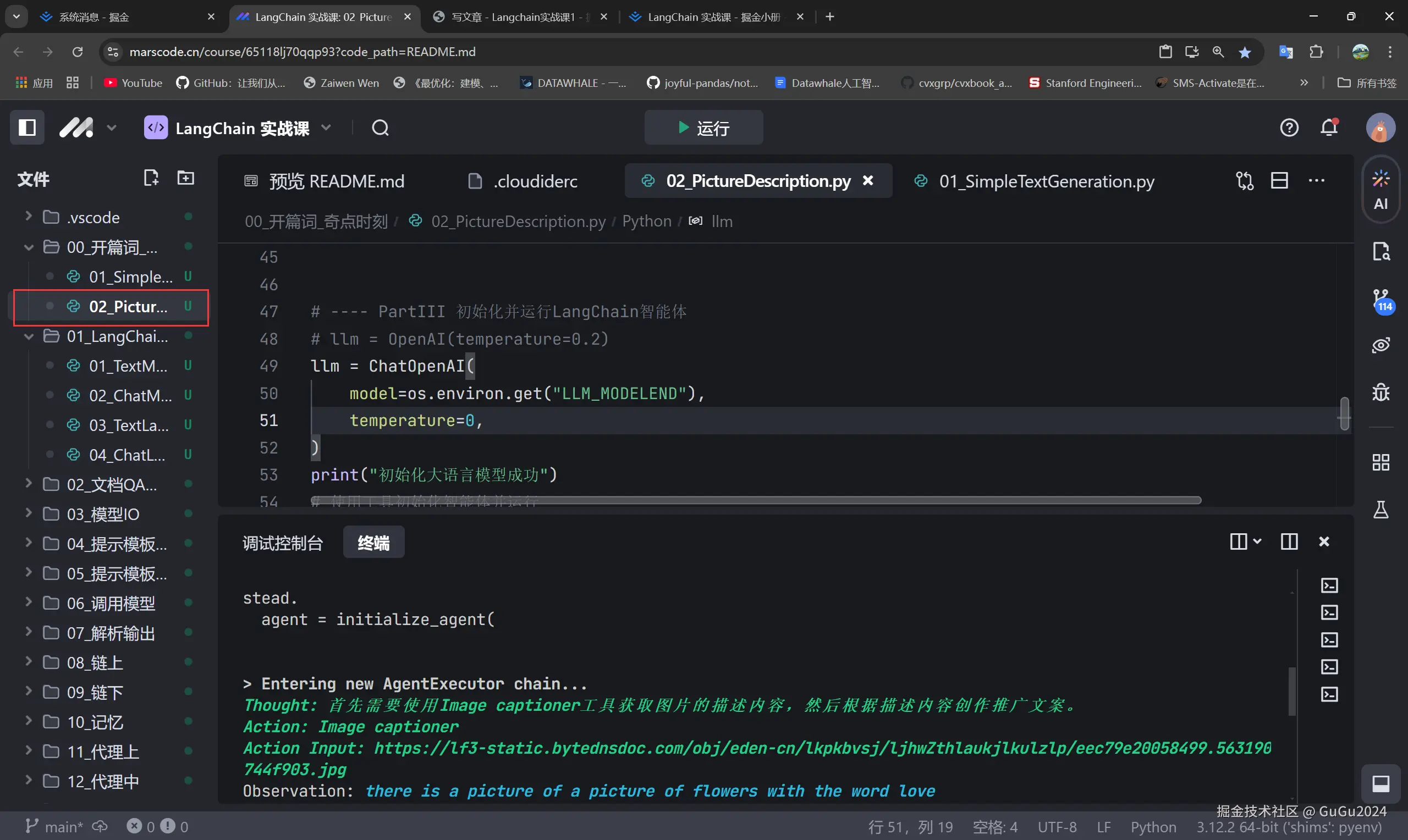
这个程序运行报错了,原因在于这时候因为我们前面设置了模型,所以我们要将我们的模型端点写入,也就是这个参数
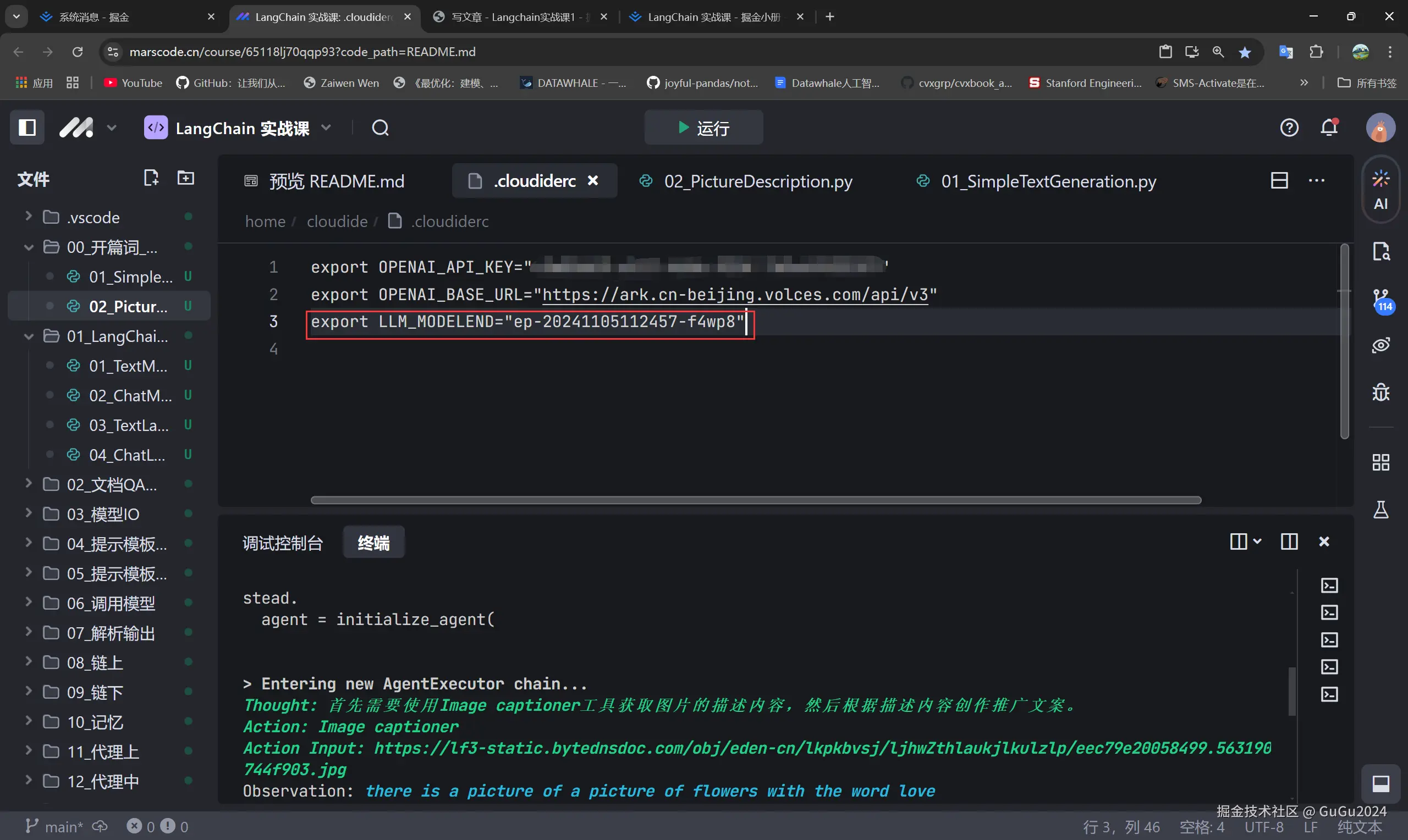
要将02中的参数名换为我们设置的那个参数的名字
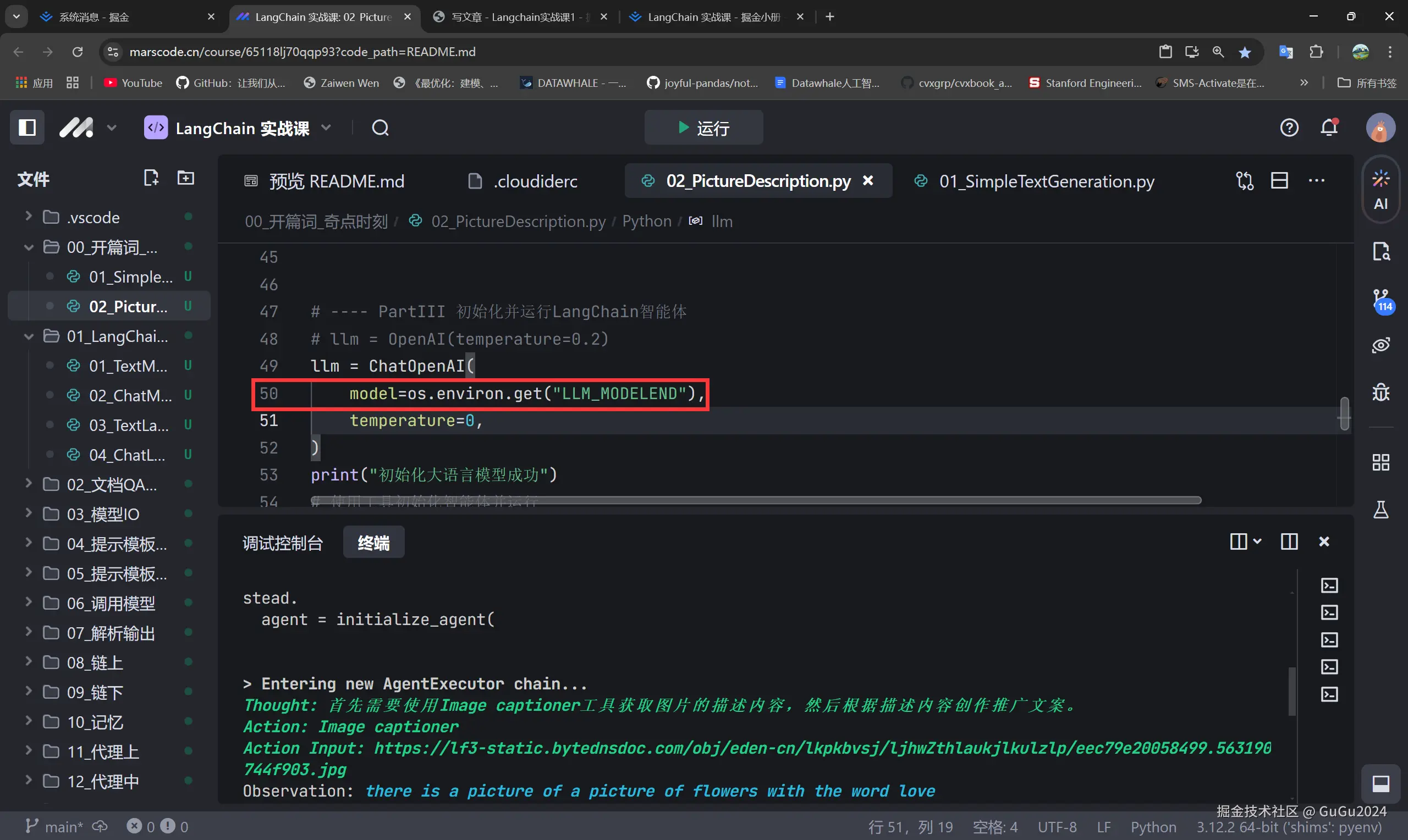
这样就可以正常运行啦!
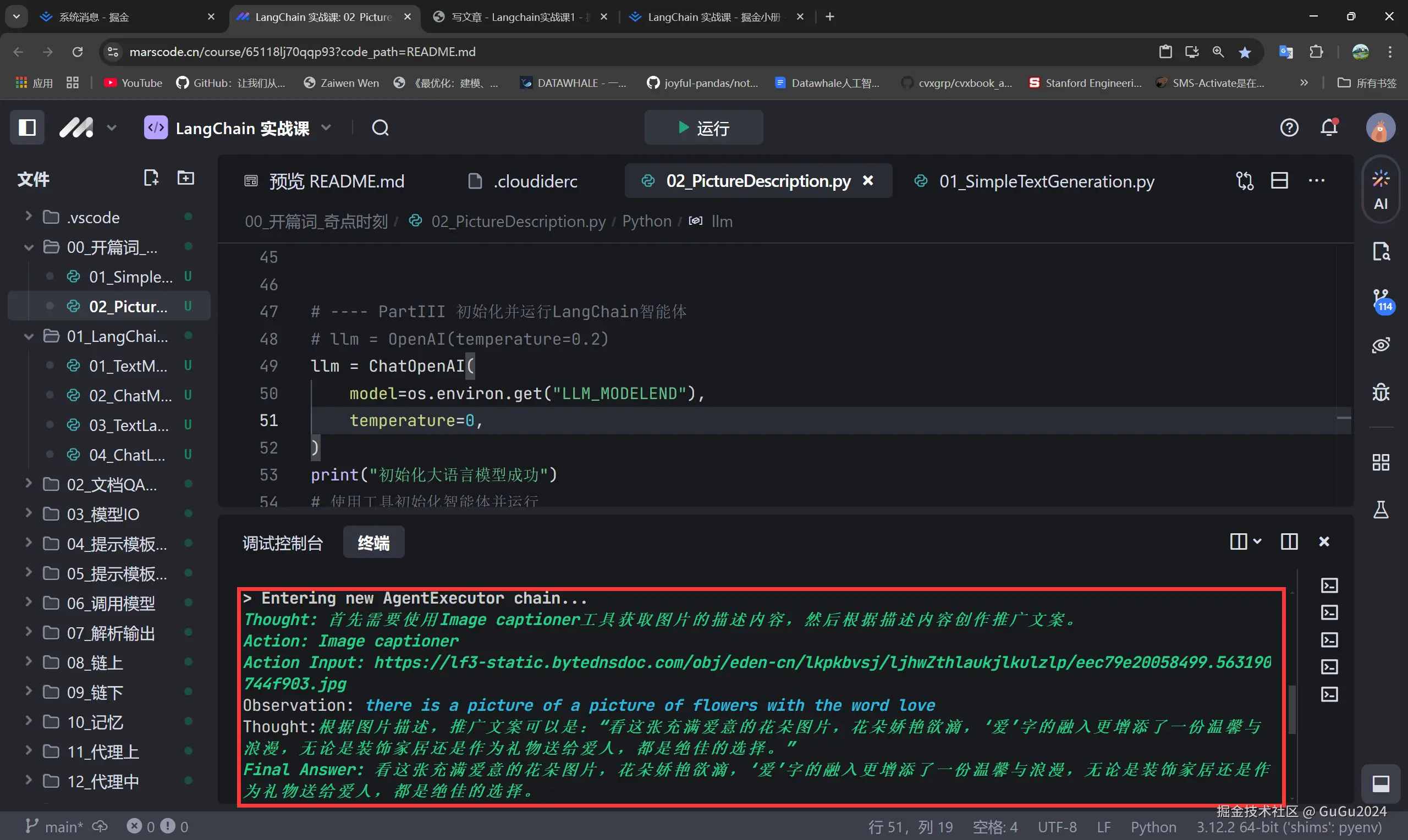
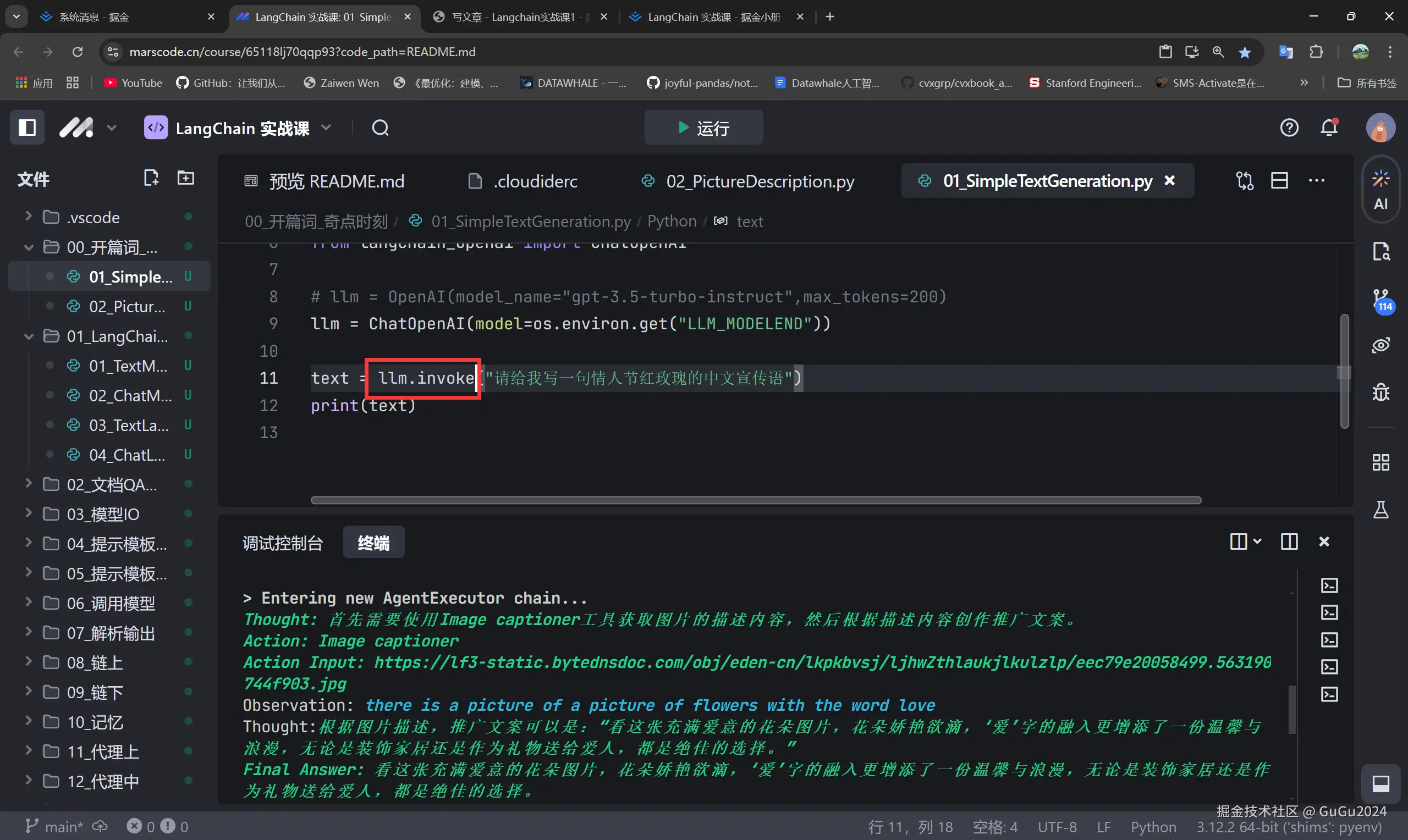
b.01程序运行完有警告
LangChainDeprecationWarning:
The method `BaseChatModel.predict` was deprecated in langchain-core 0.1.7 and will be removed in 1.0. Use invoke instead.
这是因为BaseChatModel.predict方法已经在langchain-core 0.1.7版本中被弃用,将在1.0版本中删除。因此建议你用invoke方法替代 predict方法。
所以这样改就可以了:
输出如下:
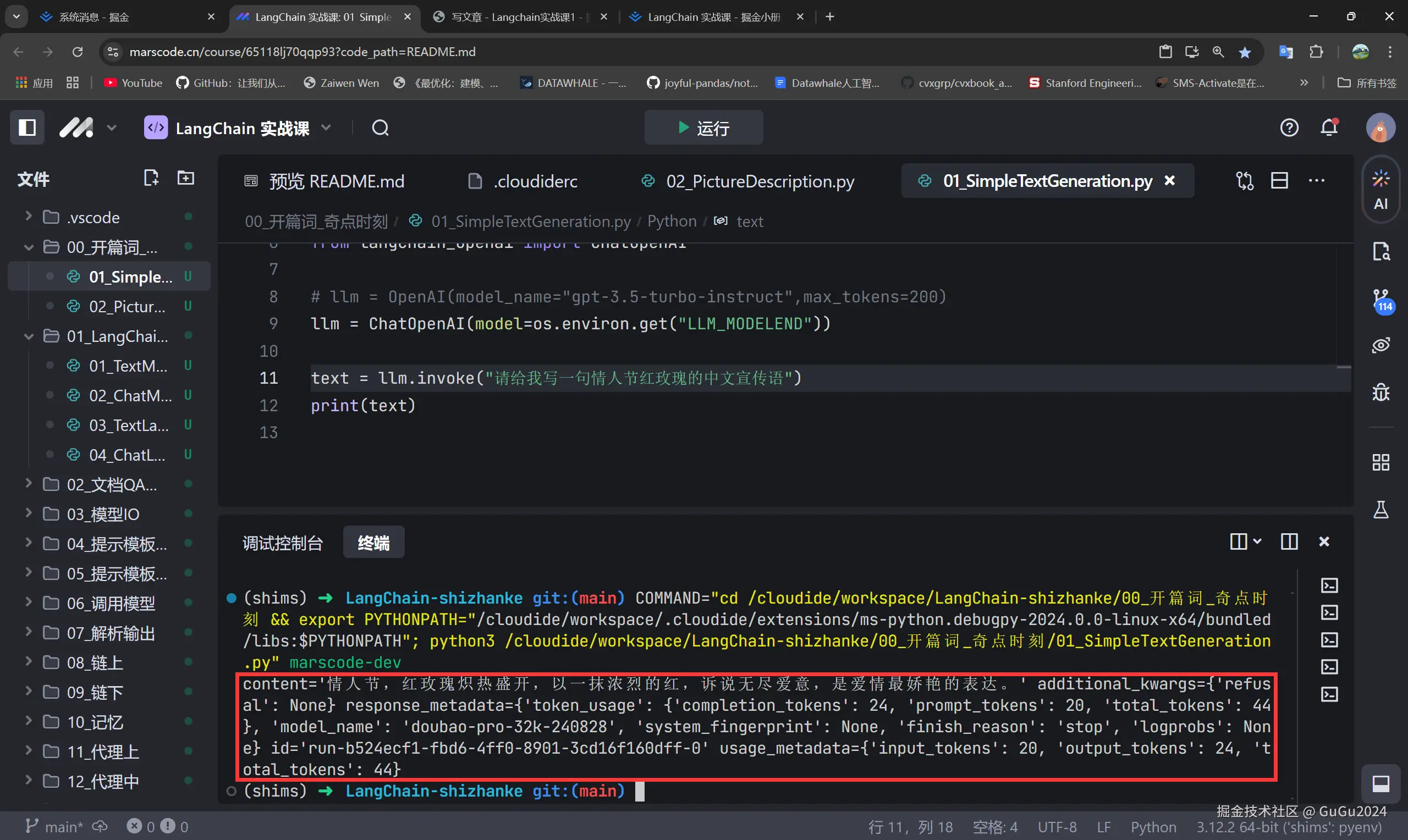
这些信息的意思是
- content部分:这是生成的文本内容,即你请求生成的情人节红玫瑰宣传语。
- additional_kwargs部分:这是一个附加的参数字典。在你的输出中,
refusal 为 None,表示模型没有拒绝响应这个请求。在某些情况下,模型可能会拒绝回答特定类型的问题,这时 refusal 就会有具体的值。
- response_metadata部分:
- token_usage
- completion_tokens: 表示用于生成文本的 token 数量,这里是
28
- prompt_tokens: 表示输入 prompt 所使用的 token 数量,这里是
20
- total_tokens: 表示整个请求的总 token 数量,即
prompt_tokens + completion_tokens = 48
- model_name: 表示使用的模型的名称,这里是
doubao-pro-32k-240828.这表明你用的模型有具体的配置或者版本号
- system_fingerprint: 是系统指纹,通常用于标识系统或执行环境。在这个输出中它为
None
- finish_reason: 生成完成的原因,这里是
'stop',通常表示模型正常完成生成,遇到停止符号(如句子结束)
- logprobs: 这个字段用于表示生成过程中 token 的对数概率分布,在这个输出中它为
None,表示未记录或未请求 log 概率信息
- id部分:这是请求的唯一标识符 (
id)。它用于唯一标识该次生成任务,在需要追踪或调试某个特定请求时很有用
- usage_metadata部分:
- input_tokens: 输入的 token 数量,这与
token_usage 中的 prompt_tokens 一致,为 20
- output_tokens: 输出生成的 token 数量,与
token_usage 中的 completion_tokens 一致,为 28
- total_tokens: 总 token 数量,为
48


