大约2500年前,古希腊人通过将多边形分成小三角形,再把这些三角形的面积加起来,找到了计算多边形面积的方法。为了计算像圆这种曲线形状的面积,他们发明了“内接多边形”的方法:在曲线内画一个多边形,随着边数越来越多,多边形就越来越接近圆。这种方法叫做逼近法。
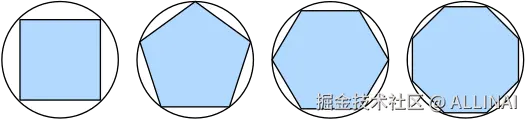
图4.1 用逼近法求圆的面积
实际上,逼近法就是积分的雏形。几千年后,另一种微积分分支——微分,也被发明了。微分主要用于解决优化问题,简单来说,就是找到让事情做到最好的方法。在深度学习中,优化问题随处可见。
在深度学习里,我们通过“训练”模型,不断调整它的参数,让模型在看到更多数据后表现得越来越好。通常,表现更好意味着我们在最小化损失函数,也就是一个用来衡量模型表现有多差的分数。最终,我们希望模型在从未见过的数据上也能有良好表现,但训练过程只能让模型适应已知数据。
因此,训练模型可以分为两个核心问题:
- 优化:通过调整模型参数,使它更好地拟合已有数据;
- 泛化:通过数学理论和经验,确保模型在未见过的数据上也能有好表现。
为了更好理解后续的优化问题和方法,本文提供了一个简明的微分基础教程,帮助读者快速掌握深度学习中的常用微分知识。
1. 导数和微分
我们首先讨论如何计算导数,这是几乎所有深度学习优化算法的核心步骤。在深度学习中,通常选择对于模型参数可微的损失函数。简单来说,对于每个参数,我们希望知道当这个参数增加或减少一个极小的量时,损失函数的变化速度。
假设我们有一个函数 f(x),其输入和输出都是标量。如果这个函数的导数存在,那么导数的定义可以用下面的公式表示:
f′(x)=h→0limhf(x+h)−f(x)
如果这个极限存在,我们就说 f(x) 在 𝑥 处是可微的。若函数在某个区间的每个点上都是可微的,则称该函数在该区间内是可微的。导数 f′(x) 可以解释为 f(x) 在 𝑥 处的瞬时变化率,即当 ℎ 很小时,f(x) 随着 𝑥 的变化速度。
1.1 实验:计算导数
为了更好地理解导数,假设我们定义一个简单的函数:f(x)=3x2−4x
def f(x):
return 3 * x ** 2 - 4 * x
现在,我们通过减小 ℎ 值,来计算数值导数。我们将使用以下代码进行实验:
def numerical_lim(f, x, h):
return (f(x + h) - f(x)) / h
h = 0.1
for i in range(5):
print(f'h={h:.5f}, numerical limit={numerical_lim(f, 1, h):.5f}')
h *= 0.1
运行结果如下:
h=0.10000, numerical limit=2.30000
h=0.01000, numerical limit=2.03000
h=0.00100, numerical limit=2.00300
h=0.00010, numerical limit=2.00030
h=0.00001, numerical limit=2.00003
从上面的结果可以看出,随着 h 越来越小,数值结果越来越接近 2,这说明当 h→0 时,导数的精确值为 2。
1.2 导数符号
对于导数,以下符号是等价的:
f′(x)=dxdf(x)=dxdf
其中,dxd 和 dxdf 都是微分运算符,表示对 𝑥 求导数。为了求出常见函数的导数,可以使用以下规则:
- 常数的导数为 0。
- 幂函数的导数:dxdxn=nxn−1(其中 𝑛 是实数)。
1.3 微分法则
若 𝑓(𝑥) 和 𝑔(𝑥) 都是可微的函数,且 𝑐 是常数,那么以下法则适用:
- 常数相乘法则: dxd[c⋅f(x)]=c⋅f′(x)
设 f(x)=3x2,其中 c=3,那么导数为:f′(x)=3⋅dxd(x2)=3⋅2x=6x
- 加法法则: dxd[f(x)+g(x)]=f′(x)+g′(x)
设 f(x)=x2,g(x)=2x,那么导数为:(f(x)+g(x))′=dxd(x2)+dxd(2x)=2x+2
- 乘法法则: dxd[f(x)⋅g(x)]=f′(x)⋅g(x)+f(x)⋅g′(x)
设 f(x)=x2,g(x)=3x,那么导数为:
(f(x)g(x))′=dxd(x2)⋅3x+x2⋅dxd(3x)=2x⋅3x+x2⋅3=6x2+3x2=9x2
- 除法法则: dxd[g(x)f(x)]=g(x)2f′(x)⋅g(x)−f(x)⋅g′(x)
设 f(x)=x2,g(x)=x+1,那么导数为:
(x+1x2)′=(x+1)22x(x+1)−x2(1)=(x+1)22x2+2x−x2=(x+1)2x2+2x
1.4 导数的可视化
我们需要定义几个函数,保存在一个独立的包d2l中,以后无须重新定义就可以直接调用它们(例如,d2l.use_svg_display())。
import sys
from matplotlib import pyplot as plt
from matplotlib_inline import backend_inline
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
d2l = sys.modules[__name__]
def use_svg_display():
"""使用svg格式在Jupyter中显示绘图"""
backend_inline.set_matplotlib_formats('svg')
def set_figsize(figsize=(3.5, 2.5)):
"""设置matplotlib的图表大小"""
use_svg_display()
d2l.plt.rcParams['figure.figsize'] = figsize
def set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):
"""设置matplotlib的轴"""
axes.set_xlabel(xlabel)
axes.set_ylabel(ylabel)
axes.set_xscale(xscale)
axes.set_yscale(yscale)
axes.set_xlim(xlim)
axes.set_ylim(ylim)
if legend:
axes.legend(legend)
axes.grid()
def plot(X, Y=None, xlabel=None, ylabel=None, legend=None, xlim=None,
ylim=None, xscale='linear', yscale='linear',
fmts=('-', 'm--', 'g-.', 'r:'), figsize=(3.5, 2.5), axes=None):
"""绘制数据点"""
if legend is None:
legend = []
set_figsize(figsize)
axes = axes if axes else d2l.plt.gca()
def has_one_axis(X):
return (hasattr(X, "ndim") and X.ndim == 1 or isinstance(X, list)
and not hasattr(X[0], "__len__"))
if has_one_axis(X):
X = [X]
if Y is None:
X, Y = [[]] * len(X), X
elif has_one_axis(Y):
Y = [Y]
if len(X) != len(Y):
X = X * len(Y)
axes.cla()
for x, y, fmt in zip(X, Y, fmts):
if len(x):
axes.plot(x, y, fmt)
else:
axes.plot(y, fmt)
set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend)
plt.show()
为了更好地理解导数的几何意义,我们可以绘制函数 f(x) 及其在 x=1处的切线y=2x−3。切线的斜率就是该点的导数值。使用 matplotlib 绘图库,我们可以创建以下可视化:
import numpy as np
import d2l
def f(x):
return 3 * x ** 2 - 4 * x
x = np.arange(0, 3, 0.1)
d2l.plot(x, [f(x), 2 * x - 3], 'x', 'f(x)', legend=['f(x)', 'Tangent line(切线) (x=1)'])
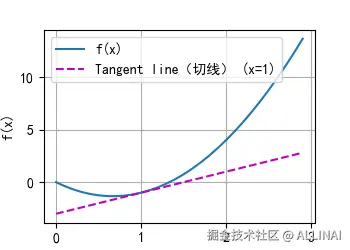
2. 偏导数
到目前为止,我们只讨论了仅含一个变量的函数的微分。在深度学习中,函数通常依赖于许多变量。因此,我们需要将微分的思想推广到 多元函数 ( multivariate function ) 上。
设 y=f(x1,x2,…,xn) 是一个具有 n 个变量的函数。关于第 i 个参数 xi 的偏导数(partial derivative)为:
∂xi∂y=Δxi→0limΔxif(x1,…,xi+Δxi,…,xn)−f(x1,…,xi,…,xn)
为了计算 ∂xi∂f,我们可以简单地将 x1,x2,…,xi−1,xi+1,…,xn 看作常数,并计算 f 关于 xi 的导数。对于偏导数的表示,以下是等价的(三种不同的表示方式):
∂xi∂y=∂xi∂f=∂xi∂f(x)=Dxif(x)
3. 梯度
我们可以连结一个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量。具体而言,设函数 f 的输入是一个 𝑛 维向量 x=[x1,x2,…,xn]T,并且输出是一个标量。函数 f 相对于 x 的梯度是一个包含 𝑛 个偏导数的向量:
g=∇xf(x)=[∂x1∂f(x),∂x2∂f(x),…,∂xn∂f(x)]
其中 ∇xf(x) 通常在没有歧义时被简化为 ∇f。
假设 x=[x1,x2,…,xn] 为 n 维向量,在微分多元函数时经常使用以下规则:
- 对于所有 A∈Rm×n,都有 ∇xAx=AT
- 对于所有 A∈Rm×n,都有 ∇xxTAx=A
- 对于所有 A∈Rm×n,都有 ∇xxTAx=(A+AT)x
- ∇x∥x∥2=∇xxTx=2x
4. 链式法则
然而,上面方法可能很难找到梯度。这是因为在深度学习中,多元函数通常是复合(composite)的,所以难以应用上述任何规则来微分这些函数。幸运的是,链式法则可以被用来微分复合函数。
让我们先考虑单变量函数。假设函数 y=f(u) 和 u=g(x) 都是可微的,根据链式法则:
dxdy=dudydxdu
现在考虑一个更一般的场景,即函数具有任意数量的变量的情况。 假设可微分函数 y 有变量 u1,u2,...,um,其中每个可微分函数 ui都有变量 x1,x2,...,xn。 注意,y 是 x1,x2,...,xn的函数。对于任意i=1,2,...,n,链式法则给出:
∂xi∂y=∂u1∂y∂xi∂u1+∂u2∂y∂xi∂u2+⋯+∂un∂y∂xi∂un
雅可比矩阵(Jacobian Matrix)是向量值函数的一阶偏导数矩阵,它描述了一个向量函数在某一点处的局部变化特性。简单来说,它可以看作是对多元函数的偏导数进行组织和排列的一种方式。
定义
设有一个从 Rn 到 Rm 的向量值函数:
f(x)=f1(x)f2(x)⋮fm(x)
其中x=[x1x2…xn]⊤ 是 Rn 中的输入变量,而 f(x) 是 Rm 中的输出向量。
雅可比矩阵是函数 f 对变量 x 的所有偏导数组成的一个矩阵。其形式为:
Jf(x)=∂x1∂f1∂x1∂f2⋮∂x1∂fm∂x2∂f1∂x2∂f2⋮∂x2∂fm……⋱…∂xn∂f1∂xn∂f2⋮∂xn∂fm
雅可比矩阵的作用
- 线性近似:雅可比矩阵可以用来线性近似非线性函数的局部变化。函数在某一点的雅可比矩阵描述了它在该点附近的线性近似。
- 牛顿法:在多元非线性方程求解中,牛顿法依赖于雅可比矩阵来更新解的近似值。
- 机器学习与神经网络:在反向传播算法中,雅可比矩阵用于计算梯度,以调整模型的参数。
4.1 平方函数的复合
设 f(x)=(2x+3)2,我们可以将其看作 f(x)=u2,其中 u=2x+3。这是一个复合函数,外层是平方函数,内层是线性函数。
推导过程:
- 定义外层和内层函数:
- 外层函数:f(u)=u2
- 内层函数:u(x)=2x+3
- 求内层函数的导数:
u′(x)=dxd(2x+3)=2
- 求外层函数对内层的导数:
f′(u)=dud(u2)=2u
- 应用链式法则:
f′(x)=f′(u)⋅u′(x)=2u⋅2=4(2x+3)
因此,f(x)=(2x+3)2 的导数为 f′(x)=4(2x+3)。
4.2 三角函数的复合
设 f(x)=sin(3x),我们可以将其看作 f(x)=sin(u),其中 u=3x。这是一个三角函数的复合。
推导过程:
- 定义外层和内层函数:
- 外层函数:f(u)=sin(u)
- 内层函数:u(x)=3x
- 求内层函数的导数:
u′(x)=dxd(3x)=3
- 求外层函数对内层的导数:
f′(u)=dud(sin(u))=cos(u)
- 应用链式法则:
f′(x)=f′(u)⋅u′(x)=cos(u)⋅3=3cos(3x)
因此,f(x)=sin(3x) 的导数为 f′(x)=3cos(3x)。
4.3 指数函数的复合
设 f(x)=e5x,我们可以将其看作 f(x)=eu,其中 u=5x。这是一个指数函数的复合。
推导过程:
- 定义外层和内层函数:
- 外层函数:f(u)=eu
- 内层函数:u(x)=5x
- 求内层函数的导数:
u′(x)=dxd(5x)=5
- 求外层函数对内层的导数:
f′(u)=dud(eu)=eu
- 应用链式法则:
f′(x)=f′(u)⋅u′(x)=eu⋅5=5e5x
因此,f(x)=e5x 的导数为 f′(x)=5e5x。
4.4 向量链式法则
假设有如下的函数:
f(x)=g(u(x))
其中,x=[x1 x2] 是二维向量,u(x)=[u1(x) u2(x)] 也是二维向量。
已知:
u1(x)=x12+x22
u2(x)=x1+x2
且 g(u)=u1+u2 是标量函数。
要求:对 f(x) 关于 x 求导。
推导过程
- 定义外层函数 g(u) 和内层函数 u(x):
- 外层函数:g(u)=u1+u2
- 内层函数:u(x)=[u1(x) u2(x)]
- 求内层函数的雅可比矩阵:
雅可比矩阵 Ju(x) 是 u 对 x 的偏导数矩阵:
Ju(x)=[∂x1∂u1∂x1∂u2∂x2∂u1∂x2∂u2]
首先计算:
∂x1∂u1=2x1,∂x2∂u1=2x2
∂x1∂u2=1,∂x2∂u2=1
因此,雅可比矩阵为:
Ju(x)=[2x112x21]
- 求外层函数对 u 的导数:
g(u)=u1+u2,因此对 u 求导得到梯度向量:
∇ug(u)=[∂u1∂g∂u2∂g]=[11]
- 应用链式法则:
根据链式法则,f(x) 的梯度 ∇xf(x) 可以表示为:
∇xf(x)=Ju(x)T∇ug(u)
将雅可比矩阵 Ju(x) 和 ∇ug(u) 代入公式:
∇xf(x)=[2x12x211][11]
进行矩阵乘法计算:
∇xf(x)=[2x1⋅1+1⋅12x2⋅1+1⋅1]=[2x1+12x2+1]
最终结果为:
∇xf(x)=[2x1+12x2+1] 

