Jdk和Jre和JVM的区别
***首先JDK是包含JRE的***
JRE(Java Runtime Enviroment)是 Java 的运行环境,如果你仅下载安装了 JRE,那么你的系统只能运行 Java
程序。它包括 Java 虚拟机、Java 核心类库(主要是java.lang)。
JDK(Java Development Kit)Java 开发工具包,包含了Java的开发工具,也包括了JRE。所以安装了JDK,就无需
再单独安装JRE了。其中的开发工具:编译工具(javac.exe),打包工具(jar.exe)等。
JVM(Java Virtual Machine)Java虚拟机,Java程序需要运行在虚拟机上,不同的平台有自己的虚拟机,因此Java
语言可以实现跨平台。
什么是跨平台性?原理是什么
所谓跨平台性,是指java语言编写的程序,一次编译后,可以在多个系统平台上运行。
实现原理:Java程序是通过java虚拟机在系统平台上运行的,只要该系统可以安装相应的java虚拟
机,该系统就可以运行java程序。
什么是字节码?采用字节码的最大好处是什么
(1)字节码:
Java源代码经过编译器编译后产生的文件(即扩展为.class的文件),它不面向任
何特定的处理器,只面向虚拟机。
(2)采用字节码的好处:
1. 可移植性 :字节码是中间代码,可以在任何⽀持 JVM 的平台上运⾏,使得 Java 程序具有很好的可移植性。
2. 性能 :字节码是⼀种⼆进制格式,相⽐于直接编译为机器码,可以更快地加载和传输,提⾼程序的执⾏效率。
3. 可读性 :可以⽅便地进⾏反汇编和调试。
Hello.java---->javac.exe--->Hello.class(字节码)--->JVM--->机器码--->CPU执行
Oracle JDK 和 OpenJDK 的对比
1、支持性不同
Oracle JDK 由 Oracle 提供技术支持,OpenJDK 由一个开源社区提供技术支持。
2、商业授权不同
Oracle JDK 具有商业授权,而 OpenJDK 是完全开源的。
3、功能不同
通常情况下,Oracle JDK 和 OpenJDK 都具有相同的功能。但是,Oracle JDK 可能附带一些 Oracle 特定的工
具和功能,而这些功能可能不存在于 OpenJDK 中。
4、安全不同
Oracle JDK 可能会在安全方面提供更多的保证,因为它是由资源丰富的公司提供的。而 OpenJDK 可能存在安全漏洞,因为它是由一个开源社区维护的。
OpenJDK是一个开源的、免费的、可修改的Java开发工具包。它是Java平台标准版(Java SE)的一个开源实现,
提供了Java开发所需的所有组件,包括编译器、调试工具、运行时环境等。OpenJDK的目的是通过开源社区的参与
和协作,提高Java平台的质量和可维护性。
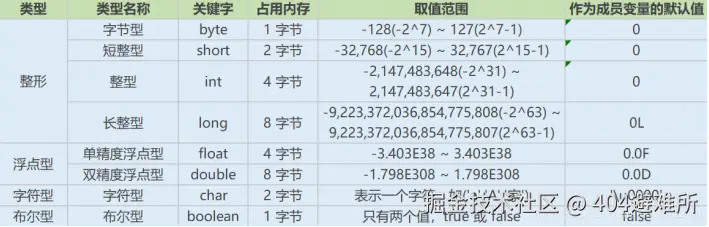
Java有哪些数据类型
Java语言是强类型语言,对于每一种数据都定义了明确的具体的数据类型,在内存中分配了不同
大小的内存空间。
**强类型语言要求在编程过程中,变量、函数参数和返回值等都必须严格遵循预定义的类型。**
switch 是否能作用在 byte 上,是否能作用在 long 上,是否能作用在 String
在 Java 5 以前,switch(expr)中,expr 只能是 byte、short、char、int。从 Java5 开始,Java 中
引入了枚举类型,expr 也可以是 enum 类型,从 Java 7 开始,expr 还可以是字符串(String),但是
长整型(long)在目前所有的版本中都是不可以的。
用最有效率的方法计算 2 乘以 8
2 << 3
--------------------------------------------------
位操作它们操作的是数字的二进制位。
**二进制是2位,二进制数据是用0和1两个数码来表示的数。
拿案例举例2乘以8=16,16的二进制是1 0 0 0 0,其实就是2的二进制数左移3位。
***二进制加法【逢二进一】
1的二进制=1
2的二进制=1 0【1+1=2所以要进位就等于1 0】
3的二进制=1 1【0+1=1不需要进位就等于1 1】
4的二进制=1 0 0
5的二进制=1 0 1
6的二进制=1 1 0
7的二进制=1 1 1
8的二进制=1 0 0 0
9的二进制=1 0 0 1
10的二进制=1 0 1 0
...
...
16的二进制=1 0 0 0 0
`<<` 是左移;如:`<<1`就是左移一位;`<<2`就是左移两位
`>>` 是右移;如:`>>1`就是右移一位;`>>2`就是右移两位
二进制运算规则:
二进制加法有四种情况:0+0=0,0+1=1,1+0=1,1+1=10(0进位为1);
二进制乘法也有四种情况:0×0=0,1×0=0,0×1=0,1×1=1;
二进制减法有四种情况:0-0=0,1-0=1,1-1=0,0-1=1;
二进制除法有两种情况(除数只能为1):0÷1=0,1÷1=1。
Math.round(11.5) 等于多少?Math.round(-11.5)等于多少
Math.round(11.5)的返回值是 12,Math.round(-11.5)的返回值是-11。四舍五入的原理是在参数
上加 0.5 然后进行向下取整。
float f=3.4;是否正确
不正确。3.4 是双精度数,将双精度型(double)赋值给浮点型(float)属于下转型(down�
casting,也称为窄化)会造成精度损失,因此需要强制类型转换float f =(float)3.4; 或者写成 float
f =3.4F;。
short s1 = 1; s1 = s1 + 1;有错吗?short s1 = 1; s1 += 1;有错吗
对于 short s1 = 1; s1 = s1 + 1;由于 1 是 int 类型,因此 s1+1 运算结果也是 int型,需要强制转换
类型才能赋值给 short 型。
而 short s1 = 1; s1 += 1;可以正确编译,因为 s1+= 1;相当于 s1 = (short(s1 + 1);其中有隐含的强
制类型转换。
Java语言采用何种编码方案?有何特点?
Java语言采用Unicode编码标准,Unicode(标准码),它为每个字符制订了一个唯一的数值,因
此在任何的语言,平台,程序都可以放心的使用。
什么Java注释
单行注释
格式:
多行注释
格式:
文档注释
格式:
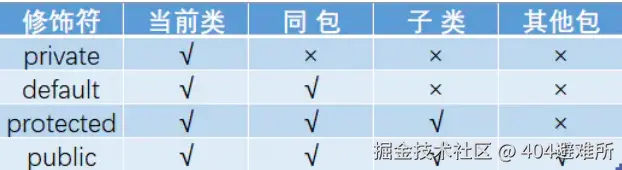
访问修饰符 public,private,protected,以及不写(默认)时的区别
定义:Java中,可以使用访问修饰符来保护对类、变量、方法和构造方法的访问。Java 支持 4 种
不同的访问权限。
分类:
private : 在同一类内可见。使用对象:变量、方法。 注意:不能修饰类(外部类)
default (即缺省,什么也不写,不使用任何关键字): 在同一包内可见,不使用任何修饰符。
使用对象:类、接口、变量、方法。
protected : 对同一包内的类和所有子类可见。使用对象:变量、方法。 注意:不能修饰类
(外部类)。
public : 对所有类可见。使用对象:类、接口、变量、方法
&和&&的区别
&用法1:可以做位运算符。
&作位运算 它会对两个数的每一位进行与操作,只有在对应的位都是1的情况下,结果的对应位才是1
private static void demo03() {
int a = 3;
int b = 4;
int c = a & b;
System.out.println(c);
}
-----------------------------------------------------------------------------------------
&也可以做逻辑与操作,也就是and两边必须同时为true,但是&不会短路,假如左边是false,还会继续计算
右边的值,&&会短路提高运算效率。
private static void demo04() {
boolean a = false;
boolean b = true;
System.out.println(a&b);
System.out.println(a&&b);
}
Java 有没有 goto
goto 是 Java 中的保留字,在目前版本的 Java 中没有使用。
final 有什么用?
被final修饰的类不可以被继承
被final修饰的方法不可以被重写
被final修饰的变量不可以被改变,被final修饰不可变的是变量的引用,而不是引用指向的内容,
引用指向的内容是可以改变的
final finally finalize区别
final可以修饰类、变量、方法,修饰类表示该类不能被继承、修饰方法表示该方法不能被重写、
修饰变量表 示该变量是一个常量不能被重新赋值。
finally一般作用在try-catch代码块中,在处理异常的时候,通常我们将一定要执行的代码方法
finally代码块 中,表示不管是否出现异常,该代码块都会执行,一般用来存放一些关闭资源的代
码。
finalize是一个方法,属于Object类的一个方法,而Object类是所有类的父类,该方法一般由垃圾
回收器来调 用,当我们调用System.gc() 方法的时候,由垃圾回收器调用finalize(),回收垃圾,一
个对象是否可回收的 最后判断。
0.1+0.2=0.3吗?
答案:不等于。
原因:计算机在处理时会将十进制转换成二进制,采用乘2取整法。但是不是所有的小数都可以转换成二进制,
所以有些小数在转成二进制时使用近似值表示。(这种近似值表示采用【二进制浮点数算术标准(IEEE754)】
0.1和0.2的二进制表示是一个无限循环小数,实际转换时通常只能截取一定位数。所以在计算0.1+0.2的时候
存在精度损失,所以不等于0.3
**十进制小数转换成二进制小数的计算方法**
乘2取整法:
1. 将小数部分乘以2,取整数部分作为二进制数的下一位。
2. 将余下的小数部分再次乘以2,继续取整数部分。
3. 重复步骤1和步骤2,直到小数部分为0。
4. 如果小数部分永远不能为0,可以根据需要保留一定位数,采用四舍五入的方法处理。
以0.125为例,转换过程如下:
1. 将0.125乘以2,得到0.25,取整数部分0。
2. 将0.25乘以2,得到0.5,取整数部分0。
3. 将0.5乘以2,得到1,取整数部分1。
4. 此时小数部分为0,转换结束。
5. 因此,0.125的二进制表示为0.001。
以0.1,转换过程如下:
1. 将0.1乘以, 得到0.2,取整数部分0。
2. 将0.2乘以2,得到0.4,取整数部分0。
3. 将0.4乘以2,得到0.8,取整数部分0。
4. 将0.8乘以2,得到1.6,取整数部分1。
5. 将0.6乘以2,得到1.2,取整数部分1。
6. 将0.2乘以2,得到0.8,取整数部分0。
...
...
无限循环,所以0.1二进制表示只能取近似值0.0001100110011...
-------------------------------------------
如何实现0.1+0.2=0.3呢?
public static void main(String[] args) {
BigDecimal bigDecimal1 = new BigDecimal("0.1");
BigDecimal bigDecimal2 = new BigDecimal("0.2");
System.out.println(bigDecimal1.add(bigDecimal2));
}
输出:
0.3
Process finished with exit code
注意:在使用BigDecimal不要使用浮点数,要使用字符串,不然会存在精度损失。
this关键字的用法
this代表对象本身,可以理解为指向对象本身的一个引用。
public class TlMain {
public void xx(){
this.getName();
}
private String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
supper关键字的用法
supper表示指向自己父类对象的一个引用,这个父类是离自己最近的一个父类。
public class Teacher {
protected String name;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
public class Student extends Teacher{
private String name;
public Student(String tName,String sName){
super.name = tName;
this.name = sName;
}
@Override
public String getName() {
return name;
}
@Override
public void setName(String name) {
this.name = name;
}
public void syInfo(){
System.out.println("tName----"+super.getName());
System.out.println("sName----"+this.getName());
}
}
public static void main(String[] args) {
Student student = new Student("张三丰", "李雷雷");
student.syInfo();
}
输出:
tName----张三丰
sName----李雷雷
this和supper区别?
相同点:
1.都是java关键字。
2.只能在非静态方法中使用,用来访问非静态的成员和字段。
3.在构造器中调用时,必须是构造方法中的第一条语句,且不能同时存在。
--------------------------------------------------------------------------------------
不同点:
1.this表示当前对象的引用,supper表父类对象的引用(只能使用子类从父类继承下来的方法和属性)。
2.在构造方法中,this(...)用来调用本类构造方法(必须放在构造方法的首行),super(...)用来调用父类
构造方法(必须放在子类构造方法的首行),两种调用不能同时在构造方法中出现,都只能写在构造方法的第一行。
3.子类构造方法中(第一行)一定会存在super()的调用(父类显示定义无参或者默认的构造方法的时候),没
有写编译器也会增加。
static
static修饰的属性和方法不属于该类任何实例对象,挂载在类本身上。
static可以创建静态代码块,并且可以有多个static块。在类初次被加载的时候,会按照static块的顺序来
执行,并且只执行一次。
特点:
1.被static修饰的变量或者方法是独立于该类的任何对象,也就是说,这些变量和方法不属于任何一个实例
对象,而是被类的实例对象所共享。
2.在类第一次加载的时候,就会去加载被static修饰的部分。
3.static修饰的变量或者方法是优先于对象存在的,也就是说当一个类加载完毕之后,即便没有创建对象,也
可以去访问。
*注意*
1.静态只能访问静态。
2.非静态既可以访问静态,也可以访问非静态。
break、continue、return区别
break:跳出并结束当前循环体。
continue:跳过当前循环、继续执行下个循环。
return:程序直接结束返回,不在执行后面代码。
面向对象和面向过程
面向过程:是具体化的,流程化的,一步一步分析和实现。
面向对象:是模块化的,通过创建不同的业务模块,调用模块中封装好的方法来处理业务。有时候不需要关注
模块里面是怎么实现了,只需要调用处理即可。
*注意*:
面向对象的底层其实还是面向过程,把面向过程抽象成了类,然后封装,以方便我们使用。
面向对象三大特性
1.封装
将数据和操作数据的方法捆绑在一起,形成一个独立的单元,通常称为类。封装的主要目的是提高代码的可维
护性和复用性,并降低代码之间的耦合度。
2.继承
一个类继承另一个类的属性和方法,从而实现代码的重用和扩展。通过继承,可以创建一个新的类,这个新类
可以继承并重用旧类的属性和方法,而不需要重新编写这些代码。继承使得代码更加模块化,提高了开发效率。
3.多态
父类或接口定义的引用变量可以指向子类或具体实现类的实例对象。提高了程序的拓展性。在Java中有两种形
式可以实现多态:继承和接口。
多态的实现:
Java实现多态有三个必要条件:继承、重写和向上转型(父类引用指向子类对象称为向上转型)。
- 继承:在多态中必须存在有继承关系的子类和父类。
- 重写:子类对父类中某些方法进行重新定义,在调用这些方法时就会调用子类的方法。
- 向上转型:在多态中需要将子类的引用赋给父类对象。
Father f = new Son();
编译看左边,运行看左边。
抽象类和接口
抽象类:抽象类是一种特殊的类,用于定义子类的通用特性。它不能被实例化,只能被继承。抽象类可以
包含抽象方法和具体实现的方法,以及字段和构造方法。
接口:接口是一种规范,定义了一组方法,但不实现它们。接口中的所有方法都是抽象的,并且默认访问修饰
符为public。接口可以包含静态方法和默认方法(从Java 8开始),但不能包含构造方法或静态代码块。
抽象类和接口的对比
- 抽象类是用来捕捉子类的通用特性的。接口是抽象方法的集合。
- 从设计层面来说,抽象类是对类的抽象,是一种模板设计,接口是行为的抽象,是一种行为的规范。
抽象类能使用final修饰吗
不能,定义抽象类就是让其他类继承的,如果用final修饰,那么该类将无法被继承。(
抽象类用final修饰编译直接报错)
对象实例和对象引用关系
对象引用存放在栈内存中,一个对象引用可以指向0个或者1个对象。
对象实例存放在堆内存中,一个对象实例可以被n个引用指向它。
成员变量与局部变量的区别
变量:在程序执行的过程中,在某个范围内其值可以发生改变的量。
成员变量:类内部定义的变量属性。
局部变量:类内部方法中定义的变量。
作用域:
成员变量:针对整个类有效。
局部变量:某个范围内有效。(一般指的就是方法或者语句体内)
存储位置:
成员变量:随着对象的创建而存在,随着对象的消失而消失,存储在堆内存中。
局部变量:在方法被调用,或者语句被执行的时候存在,存储在栈内存中。当方法调用完,
或者语句结束后,就自动释放。
生命周期:
成员变量:随着对象的创建而存在,随着对象的消失而消失。
局部变量:当方法调用完毕,或者语句结束后,就自动释放。
初始值:
成员变量:有默认值
局部变量:没有默认值,使用前必须赋值。
在Java中定义一个不做事且没有参数的构造方法的作用
Java程序在执行子类的构造方法之前,如果没有显示用super()来调用父类特定的构造方
法,则会隐式调用父类中“没有参数的构造方法”。因此,如果父类中只定义了有参数的构造
方法,而在子类的构造方法中又没有用super()来调用父类中特定的构造方法,则编译时将
发生错误,因为Java程序在父类中找不到没有参数的构造方法可供执行。解决办法是在父
类里加上一个不做事且没有参数的构造方法。
类的构造方法作用是什么
初始化操作。若一个类没有显示编写构造方法,则会默认存在一个无参的构造方法。
构造方法特点:
1.名字与类名相同。
2.没有返回值,但不能用void声明构造函数。
3.生成类的对象时自动执行,无需调用。
静态变量和实例变量区别
静态变量:静态变量不属于任何实例对象,属于类的,所以在内存中只会有一份,在类加载
过程中,JVM只为静态变量分配一次内存空间。
实例变量:每次创建对象,都会为每个对象分配成员变量内存空间,实例变量是属于实例对
象的,在内存中,创建几次对象,就有几份成员变量。
静态方法和实例方法有何不同
1.在外部调用静态方法时,可以使用"类名.方法名"的方式,也可以使用"对象名.方法
名"的方式。而实例方法只有后面这种方式。也就是说,调用静态方法可以无需创建对象。
2.静态方法在访问本类的成员时,只允许访问静态成员(即静态成员变量和静态方法),而
不允许访问实例成员变量和实例方法,实例方法则无此限制。
内部类
内部类:在Java中,可以将一个类的定义放在另外一个类的定义内部,这就是内部类。内
部类本身就是类的一个属性,与其他属性定义方式一致。
内部类可以分为四种:成员内部类、局部内部类、匿名内部类和静态内部类。
静态内部类
public class Cat {
private static String name = "小小喵";
static public class CatName{
public void printCatName(){
System.out.println("my name:"+name);
}
}
}
静态内部类可以访问外部类所有的静态变量,而不可访问外部类的非静态变量;静态内部类
的创建方式,`new 外部类.静态内部类()`,如下:
public static void main(String[] args) {
Cat.CatName catName = new Cat.CatName();
catName.printCatName();
}
输出:
my name:小小喵
成员内部类:定义在类内部,成员位置上的非静态类,就是成员内部类。
public class Cat {
private String name = "小红喵";
public class CatName{
public void printCatName(){
System.out.println("my name:"+name);
}
}
}
成员内部类可以访问外部类所有的变量和方法,包括静态和非静态,私有和公有。成员内部
类依赖于外部类的实例,它的创建方式`外部类实例.new 内部类()`,如下:
public static void main(String[] args) {
Cat cat = new Cat();
Cat.CatName cn = cat.new CatName();
cn.printCatName();
}
局部内部类:定义在方法中的内部类,就是局部内部类。
1.定义在实例方法中的局部类可以访问外部类的所有变量和方法。
2.定义在静态方法中的局部类只能访问外部类的静态变量和方法。
局部内部类的创建方式,在对应方法内,`new 内部类()`,如下:
public class Zoo {
private static String dogName = "黑大帅";
private String tigerName = "上山虎";
public static void myDog(){
class Dog{
public void printName(){
System.out.println("my name:"+dogName);
}
}
Dog dog = new Dog();
dog.printName();
}
public void myTiger(){
class Tiger{
public void printName(){
System.out.println("my name:"+tigerName);
}
}
Tiger tiger = new Tiger();
tiger.printName();
}
}
匿名内部类就是没有名字的内部类。
public class Ear {
public static void main(String[] args) {
new EyeInterface(){
@Override
public void eyeName() {
System.out.println("大眼睛 炯炯有神的眼睛");
}
}.eyeName();
}
}
public interface EyeInterface {
void eyeName();
}
特点:
1.- 匿名内部类必须继承一个抽象类或者实现一个接口。
2.- 匿名内部类不能定义任何静态成员和静态方法。
3.- 当所在的方法的形参需要被匿名内部类使用时,必须声明为 final。
4.- 匿名内部类不能是抽象的,它必须要实现继承的类或者实现接口的所有抽象方法。
优点:
1.- 内部类不为同一包的其他类所见,具有很好的封装性;
2.- 内部类有效实现了“多重继承”,优化 java 单继承的缺陷。
局部内部类和匿名内部类访问局部变量的时候,为什么变量必须要加上final
1.生命周期问题:
局部变量的生命周期是当该方法被调用时在栈中被创建,当方法调用结束时退栈,这
些局部变量就会死亡。然而,内部类对象是创建在堆中的,其生命周期与其它类一样,只有
当JVM通过可达性分析法发现这个对象通过GCRoots节点已经不可达时,才会进行GC。因
此,完全有可能出现一个方法已经调用结束(局部变量已死亡),但内部类的对象仍然活着
的情况。为了防止这种情况导致内部类对象访问已死亡的局部变量,Java规定局部变量必
须加上final。
2.final修饰符的作用:
当局部变量被定义为final时,编译程序可以将这些final型局部变量作为内部类对象
的数据成员。这样,即使栈中的局部变量已经死亡,但由于它是final,其值永不变,因此
内部类对象在变量死亡后仍然可以访问final型局部变量。
3.作用域问题:
匿名内部类是出现在一个方法的内部的,如果它要访问这个方法的参数或者方法中定
义的变量,则这些参数和变量必须被修饰为final。这是因为编译时内部类和方法在同一级
别上,外部类中的方法中的变量或参数只有为final,内部类才可以引用。
4.数据同步问题:
如果局部变量不是final的,其取值可以被修改,而内部类对象中保存的是其原来的
值,这就会出现数据不同步的问题。为了避免这种情况,Java规定内部类只能访问final的
局部变量。
==和equals区别
==:它的作用是判断两个对象的地址是不是相等。即判断两个对象是不是同一个对象。
(基本数据类型 == 比较的是值,引用数据类型 == 比较的是内存地址)
equals():比较两个对象内容(值)相等。(需要重写equals方法)
public static void main(String[] args) {
String aName = new String("小马");
String bName = new String("小马");
System.out.println(aName.equals(bName));
String cName = "晓晓";
String dName = "晓晓";
System.out.println(cName.equals(dName));
}
注意:
1.String中的equals方法是被重写过的,因为object的equals方法是比较的对象的内存
地址,而String的equals方法比较的是对象的值。
2.当创建String类型的对象时,虚拟机会在常量池中查找有没有已经存在的值和要创建
值相同的对象,如果有就把它赋给当前引用。如果没有就在常量池中重新创建一个String对象。
hashCode()
hashCode() 的作用是获取哈希码,也称为散列码;它实际上是返回一个int整数。这个哈
希码的作用是确定该对象在哈希表中的索引位置。hashCode() 定义在JDK的Object.java
中,这就意味着Java中的任何类都包含有hashCode()函数。
散列表存储的是键值对(key-value),它的特点是:能根据“键”快速的检索出对应的
“值”。这其中就利用到了散列码!(可以快速找到所需要的对象)
-------------------------------------------------------------------------
为什么要有hashCode
当你把对象加入 HashSet 时,HashSet 会先计算对象的 hashcode 值来判断对象加入的
位置,同时也会与其他已经加入的对象的 hashcode 值作比较,如果没有相符hashcode,
HashSet会假设对象没有重复出现。但是如果发现有相同 hashcode 值的对象,这时会调
用 equals()方法来检查 hashcode 相等的对象是否真的相同。如果两者相同,HashSet
就不会让其加入操作成功。这样我们就大大减少了 equals 的次数,相应就大大提高了执
行速度。
hashCode()与equals()的相关规定
- 如果两个对象相等,则hashcode一定也是相同的。
- 两个对象有相同的hashcode值,它们也不一定是相等。
对象的相等与指向他们的引用相等,两者有什么不同
1.对象相等:比较的是内存中存放的内容是否相等。
2.引用相等:比较的是它们指向的内存地址是否相等。
值传递
在java方法参数的传递都是值传递,基本类型和引用类型都是传递参数的副本。
--基本类型传递
public class TlMain {
public static void main(String[] args) {
int a1 = 10;
int a2 = 20;
addSeven(a1,a2);
System.out.println("a1:"+a1);
System.out.println("a2:"+a2);
}
private static void addSeven(int a1,int a2){
a1 = a1+7;
a2 = a2+7;
System.out.println("addSeven---a1:"+a1);
System.out.println("addSeven---a2:"+a2);
}
}
输出:
addSeven---a1:17
addSeven---a2:27
a1:10
a2:20
--引用对象传递,传递的是引用对象地址副本,所以arr和arr指向的是同一个对象。
public class TlMain {
public static void main(String[] args) {
int[] arr = {1,2,3};
addSeven(arr);
System.out.println("arr[0]:"+arr[0]);
}
private static void addSeven(int[] arr){
arr[0]=arr[0]+7;
System.out.println("addSeven--arr[0]"+arr[0]);
}
}
输出:
addSeven--arr[0]8
arr[0]:8
IO流
java中IO流分为几种?
1.- 按照流的流向分,可以分为输入流和输出流;
2.- 按照操作单元划分,可以划分为字节流和字符流;
3.- 按照流的角色划分为节点流和处理流。
InputStream/Reader: 所有的输入流的基类,前者是字节输入流,后者是字符输入流。
OutputStream/Writer: 所有输出流的基类,前者是字节输出流,后者是字符输出流。
BIO
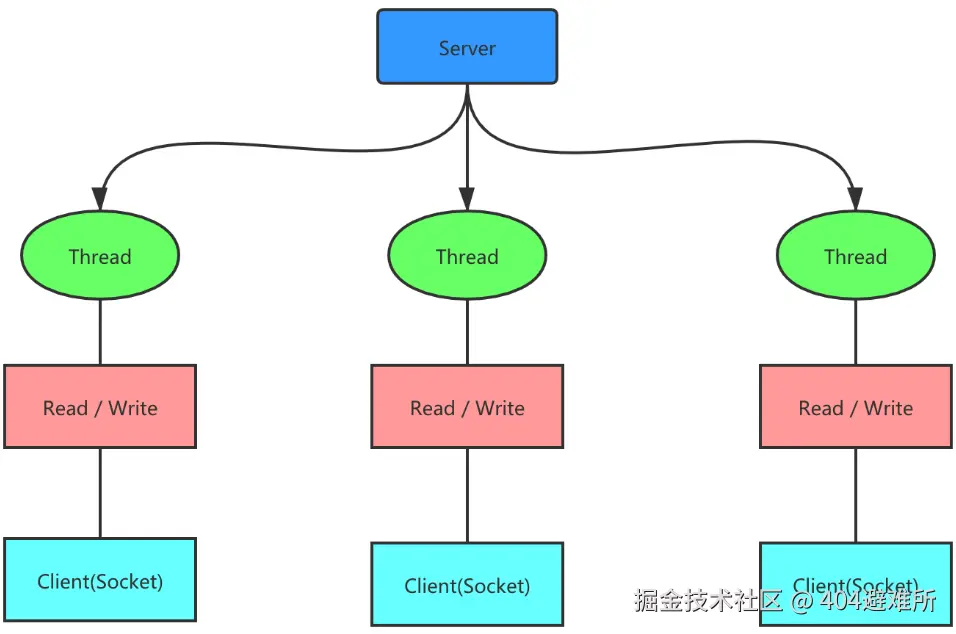
BIO:(Blocking I/O)同步阻塞I/O模式,一个连接对应一个线程,客户端有连接请求时服务
端就启动一个线程,即使这个连接不做任何事情也会占用线程资源。
--service--
public class BioService {
public static void main(String[] args) {
ServerSocket ss = null;
try {
System.out.println("——服务端启动——");
ss = new ServerSocket(8888);
while (true){
Socket socket = ss.accept();
new ServerThreadReader(socket).start();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
public class ServerThreadReader extends Thread{
private Socket socket;
public ServerThreadReader(Socket socket) {
this.socket = socket;
}
@Override
public void run() {
InputStream is = null;
try {
is = socket.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is));
String msg;
if ((msg = br.readLine()) != null){
System.out.println("服务端接收到:"+msg);
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
--client--
public class BioClient {
public static void main(String[] args) {
try {
Scanner sc = new Scanner(System.in);
while (true){
System.out.print("请输入:");
String msg = sc.nextLine();
Socket socket = new Socket("127.0.0.1",8888);
OutputStream os = socket.getOutputStream();
PrintStream ps = new PrintStream(os);
ps.println(msg);
ps.flush();
}
} catch (IOException e) {
e.printStackTrace();
}
}
}
NIO
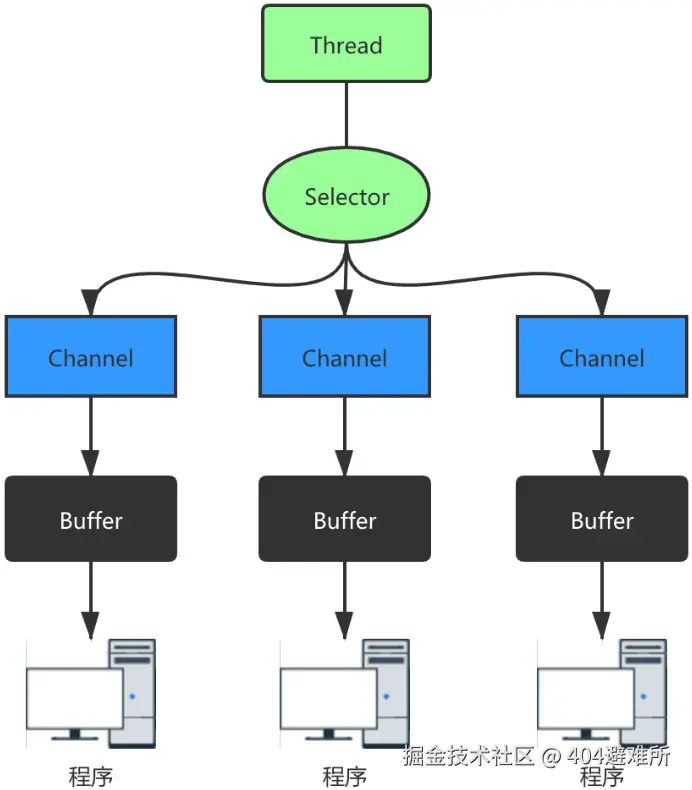
NIO (New I/O):NIO是一种同步非阻塞的I/O模型,在Java 1.4 中引入了NIO框架,对应
java.nio 包。NIO 采用 Reactor 模式,属于IO多路复用模型,可以用一个线程处理多
个请求。NIO有三大核心模块,通道(Channel)、缓冲区(Buffer)、选择器(Selector)。
服务端只会创建一个线程负责管理Selector(多路复用器),Selector(多路复用器)不
断的轮询注册其上的Channel(通道)中的 I/O 事件,并将监听到的事件进行相应的处
理。每个客户端与服务端建立连接时会创建一个 SocketChannel 通道,通过
SocketChannel 进行数据交互。
Selector 对应一个线程,一个 Selector 可以对应多个 Channel,一个 Channel 对应
一个 Buffer。程序切换到哪个 Channel 是由事件决定的,Selector 会根据不同的事件
切换不同的 Channel。
AIO(Asynchronous I/O)
(Asynchronous I/O)是Java中一种处理I/O操作的高级模型,特别适用于高并发和大量I/O请求的场景。AIO
允许线程在发起I/O请求后立即返回,继续执行其他任务,而不需要等待I/O操作完成。当I/O操作完成后,系统
会通过回调机制通知应用程序处理结果.
AIO与BIO和NIO的区别?
- BIO(Blocking I/O):传统的同步阻塞I/O模型,每个请求都会阻塞一个线程,适用于少量并发请求,但性能和资源消耗不理想。
- NIO(Non-blocking I/O):通过选择器和通道管理多个连接的I/O操作,避免了每个请求都需要一个线程的问题,但仍然是基于轮询机制的。
- AIO:真正的异步操作模型,线程不阻塞,系统在I/O操作完成后通过回调机制通知应用程序。AIO在处理大量并发I/O请求时更加高效。
Files的常用方法都有哪些?
- Files.exists():检测文件路径是否存在。
- Files.createFile():创建文件。
- Files.createDirectory():创建文件夹。
- Files.delete():删除一个文件或目录。
- Files.copy():复制文件。
- Files.move():移动文件。
- Files.size():查看文件个数。
- Files.read():读取文件。
- Files.write():写入文件。
反射
Java反射是一种在运行时检查和修改类或接口的方法。通过反射,Java程序可以在运行时获取类的结构
(如类名、字段、方法、构造函数等),动态地创建类的实例,调用类的方法或访问字段。
反射的用途
1.动态创建对象:反射可以基于类的信息,程序可以在运行时动态创建对象实例。
2.调用方法:反射可以根据方法名称,程序可以在运行时动态地调用对象的方法。
3.访问成员变量:反射可以根据成员变量名称,程序可以在运行时访问和修改成员变量(包括私有成员变量)。
4.运行时类型信息:反射允许程序在运行时查询对象的类型信息,这对于编写通用的代码和库非常有用。
反射的核心类和方法
反射主要依赖`java.lang.reflect`包中的类和方法,这些核心类包括:
`Class`:代表类或接口本身,用于获取类的名称、构造方法、方法、字段等信息。
`Constructor`:用于表示类的构造方法,可以用来创建类的实例。
`Method`:表示类的方法,可以用来调用对象的方法。
`Field`:表示类的字段(属性),可以直接操作对象的属性。
反射的基本操作
1.获取Class对象:可以通过类字面量、对象实例的`getClass()`方法或`Class.forName()`方法获取Class对象。
2.获取构造方法:通过Class对象可以获取类的构造方法并创建实例。
3.访问字段:可以通过反射访问和修改类的字段。
反射的性能和安全性问题
反射会带来性能开销,因为需要在运行时动态查找和调用方法,这比直接调用方法要慢。此外,反射可能会破
坏封装性,因为可以访问和修改私有成员。因此,在使用反射时需要注意性能和安全性的影响。
反射机制的应用场景有哪些?
1:我们在使用JDBC连接数据库时使用Class.forName()通过反射加载数据库的驱动程序;
2:Spring框架也用到很多反射机制,最经典的就是xml的配置模式。
Java获取反射的三种方法
1.通过new对象实现反射机制
2.通过路径实现反射机制
3.通过类名实现反射机制
public class Fs {
public static void main(String[] args) throws ClassNotFoundException {
Cat cat = new Cat();
Class c1 = cat.getClass();
System.out.println(c1.getName());
Class c2 = Class.forName("com.durian.Cat");
System.out.println(c2.getName());
Class c3 = Cat.class;
System.out.println(c3.getName());
}
}


