

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
from pyfinance import TSeries
token = '你的tushare密钥' ts.set_token(token) pro = ts.pro_api(token)
1. 首先我们来读取我过去根据我导师的加工后的代码所获取的每个季度,A股上市公司的经营情况的打分。
df_20214 = pd.DataFrame(pd.read_csv("D:\BaiduNetdiskWorkspace\股票候选\季度3连涨候选人_2021年第肆季.csv", encoding='GBK', index_col=0)) df_20221 = pd.DataFrame(pd.read_csv("D:\BaiduNetdiskWorkspace\股票候选\季度3连涨候选人_2022年第壹季.csv", encoding='GBK', index_col=0)) df_20222 = pd.DataFrame(pd.read_csv("D:\BaiduNetdiskWorkspace\股票候选\季度3连涨候选人_2022年第贰季.csv", encoding='GBK', index_col=0))

2. 其次我们看看这三张表里面,每张表大概有多少只股票。`len(df_20214),len(df_20221),len(df_20222)`输出分别为179,509,594。
3. 当我们把分值缩小至66分以上,它们的输出缩小为55,105,132。
df_20214_66 = df_20214[df_20214[df_20214.columns[-1]] > 66] df_20221_66 = df_20221[df_20221[df_20221.columns[-1]] > 66] df_20222_66 = df_20222[df_20222[df_20222.columns[-1]] > 66]
4. 我们来看看在过去的半年里表现一直很亮眼的候选人的名单:
set_stocklist = set(list_20214) & set(list_20221) & set(list_20222) # 看看哪些股票同时在这3张表内 df_result_list = pd.DataFrame({'ts_code':list(set_stocklist)}) # 创建一个列名为ts_code的dataframe df_result = pd.merge(df_result_list, df_20222, on='ts_code') # 与最后一期表合并筛选出这几支股票都是哪些 df_result = df_result.sort_values(by=df_result.columns[-1], ascending=False).reset_index(drop=True) # 排序整理一下
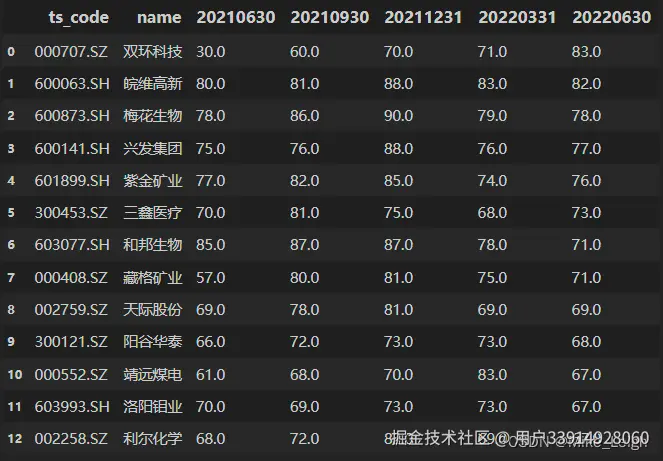
5. 截至到这里我们发现,在2021年~2022年中的表现来看,我们的候选人从我的3张表中筛选出来的**概率只有10%**
#### 代码及分析 - 股票行情
1. 以下的展示代码可以通过导师的这个帖子来学习获得,[请自行阅读获取](https://gitee.com/vip204888)。
2. 首先我们来封装一个从tushare上获取数据的并以时间排序的数据。
def get_data(code,start='2021-01-01',end=''): if code.startswith('399'): # 399开头的指数数据,用于区分股票数据 df=pro.index_daily(ts_code=code,start_date=start,end_date=end) else: df=ts.pro_bar(code,start_date=start,end_date=end,adj='qfq',freq='D') df=df.sort_values('trade_date', ascending=True) # 按照时间正序排列,因为tushare给我们的是倒序排列 df.index=pd.to_datetime(df.trade_date) # 以时间轴为index ret=df.close/df.close.shift(1)-1 # 计算每日收益率 #返回TSeries序列 return TSeries(ret.dropna())
3. 将重要的指标进行封装,有什么不明白的地方请参阅[本贴](https://gitee.com/vip204888)。还有一个可能大家会遇到的问题就是计算标准差这里,很多指标会用到它,但是设计的时候又不让大家传`freq=`的参数。建议大家`pip install pyfinance`库后,去pyfinance的文件夹找一个叫做`returns.py`的文件,把牵扯到`anlzd_stdev()`的公式,统统将参数`freq=250`进行固定年化设置。
def performance(code): tss=get_data(code) benchmark=get_data('399300.SZ').loc[tss.index] dd={} #收益率 #年化收益率 dd['年化收益率']=tss.anlzd_ret() #累积收益率 dd['累计收益率']=tss.cuml_ret() #alpha和beta dd['alpha']=tss.alpha(benchmark) dd['beta']=tss.beta(benchmark) #风险指标 #年化标准差 dd['年化标准差']=tss.anlzd_stdev(freq=250) #下行标准差 dd['下行标准差']=tss.semi_stdev(freq=250) #最大回撤 dd['最大回撤']=tss.max_drawdown() #信息比率和特雷诺指数 dd['信息比率']=tss.info_ratio(benchmark) dd['特雷纳指数']=tss.treynor_ratio(benchmark) #风险调整收益率 dd['夏普比率']=tss.sharpe_ratio() dd['索提诺比率']=tss.sortino_ratio(freq=250) dd['calmar比率']=tss.calmar_ratio() df=pd.DataFrame(dd.values(),index=dd.keys()).round(4) return df
4. 最后将分析逻辑进行封装,获取最后的分析数据矩阵。
def analysis(): df=pd.DataFrame(index=performance('600110.SH').index) name = df_result.name.values[:] code = df_result.ts_code.values[:] stocks = dict(zip(name,code)) for name,code in stocks.items(): try: df[name] = performance(code).values except: continue return df
5. 最终的输出的结果是这样的:

### 总结
1. 从我们的最终结果来看,这13支股票的最大回撤相当的惊人。不难看出最近大A表现得非常难看,与大环境有很大的关系:欧洲打仗,能源暴涨,通货膨胀,国内疫情,最重磅的还有美国持续大力度加息。我们其实是可以通过对大盘的数据进行分析来规避一定的损失,在后期我希望我有机会可以跟大家分享我的理解和心得。
2. 这次分析我们有拿未来数据来套娃,因为毕竟基本面分析是有一定的滞后性的,所以我们要计算我们有多大的概率从中筛选出好的标的。第三季度财报下个月已经快出炉了,后面的策略按照个人的理解可以稍微进行调整。我们也可以通过技术指标分析来进行筛选是否进行投资,如何投资,投资多少。
3. 希望我的这个思路可以对大家有所启迪。
### 参考资料
1. [【手把手教你】使用pyfinance进行证券收益分析](https://gitee.com/vip204888)


**网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。**
**[需要这份系统化资料的朋友,可以戳这里获取](https://gitee.com/vip204888)**
**一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!**
