

}
// 3.判断库存是否充足
if(voucher.getStock() < 1){
//库存不足
return Result.fail("库存不足!");
}
Long userId = UserHolder.getUser().getId();
// 这个代码我们不用了,下面要用Redisson中的分布式锁
// SimpleRedisLock lock = new SimpleRedisLock("order:" + userId, stringRedisTemplate);
RLock lock = redissonClient.getLock("order:" + userId);
boolean isLock = lock.tryLock();
// 判断是否获取锁成功
if(!isLock){
// 获取锁失败,返回错误和重试
return Result.fail("不允许重复下单~");
}
try {
// 获取代理对象(只有通过代理对象调用方法,事务才会生效)
IVoucherOrderService proxy = (IVoucherOrderService) AopContext.currentProxy();
return proxy.createVoucherOrder(voucherId);
} finally {
lock.unlock();
}
}
**进行测试:**
在集群环境下,一秒一千次请求~ 一个用户只能下一单。分布式锁测试成功~


#### 5.3 分布式锁-redission可重入锁原理
在Lock锁中,他是借助于底层的一个voaltile的一个state变量来记录重入的状态的,比如当前没有人持有这把锁,那么state=0,假如有人持有这把锁,那么state=1,如果持有这把锁的人再次持有这把锁,那么state就会+1 ,如果是对于synchronized而言,他在c语言代码中会有一个count,原理和state类似,也是重入一次就加一,释放一次就-1 ,直到减少成0 时,表示当前这把锁没有被人持有。
在redission中,我们的也支持支持可重入锁
在分布式锁中,他采用hash结构用来存储锁,其中大key表示表示这把锁是否存在,用小key表示当前这把锁被哪个线程持有。流程图如下:

>
> 为什么每次获取锁成功 或 释放锁 后都要重新设置锁的有效期呢?
>
>
> 这样是为了下面的业务有足够的时间去执行~
>
>
>
**1、接下来我们一起分析一下当前的可重入锁实现的lua表达式**
* 获取锁的Lua脚本:
local key = KEYS[1]; -- 锁的key local threadId = ARGV[1]; -- 线程唯一标识 local releaseTime = ARGV[2]; -- 锁的自动释放时间 -- 判断是否存在 if(redis.call('exists', key) == 0) then -- 不存在, 获取锁 redis.call('hset', key, threadId, '1'); -- 设置有效期 redis.call('expire', key, releaseTime); return 1; -- 返回结果 end; -- 锁已经存在,判断threadId是否是自己 if(redis.call('hexists', key, threadId) == 1) then -- 存在, 获取锁,重入次数+1 redis.call('hincrby', key, threadId, '1'); -- 设置有效期 redis.call('expire', key, releaseTime); return 1; -- 返回结果 end; return 0; -- 代码走到这里,说明获取锁的不是自己,获取锁失败
* 释放锁的Lua脚本:
local key = KEYS[1]; -- 锁的key local threadId = ARGV[1]; -- 线程唯一标识 local releaseTime = ARGV[2]; -- 锁的自动释放时间 -- 判断当前锁是否还是被自己持有 if (redis.call('HEXISTS', key, threadId) == 0) then return nil; -- 如果已经不是自己,则直接返回 end; -- 是自己的锁,则重入次数-1 local count = redis.call('HINCRBY', key, threadId, -1); -- 判断是否重入次数是否已经为0 if (count > 0) then -- 大于0说明不能释放锁,重置有效期然后返回 redis.call('EXPIRE', key, releaseTime); return nil; else -- 等于0说明可以释放锁,直接删除 redis.call('DEL', key); return nil; end;
**2、测试Redission的分布式锁的可重入效果**
/** * @author lxy * @version 1.0 * @Description 测试Redisson的分布式锁的可重入性质 * @date 2022/12/21 16:01 */ @Slf4j @SpringBootTest public class RedissonTest {
@Resource
private RedissonClient redissonClient;
private RLock lock;
@BeforeEach
void setUp(){
lock = redissonClient.getLock("order");
}
@Test
void method1() throws InterruptedException {
// 尝试获取锁
boolean isLock = lock.tryLock(1L, TimeUnit.SECONDS);
if (!isLock){
log.error("获取锁失败....1");
return;
}
try {
log.info("获取锁成功....1");
method2();
log.info("开始执行业务....1");
} finally {
log.warn("开始释放锁....1");
lock.unlock();
}
}
void method2(){
// 尝试获取锁
boolean isLock = lock.tryLock();
if(!isLock){
log.error("获取锁失败....2");
return;
}
try {
log.info("获取锁成功....2");
log.info("开始执行业务....2");
} finally {
log.warn("准备释放锁....2");
lock.unlock();
}
}
}
Debug测试:
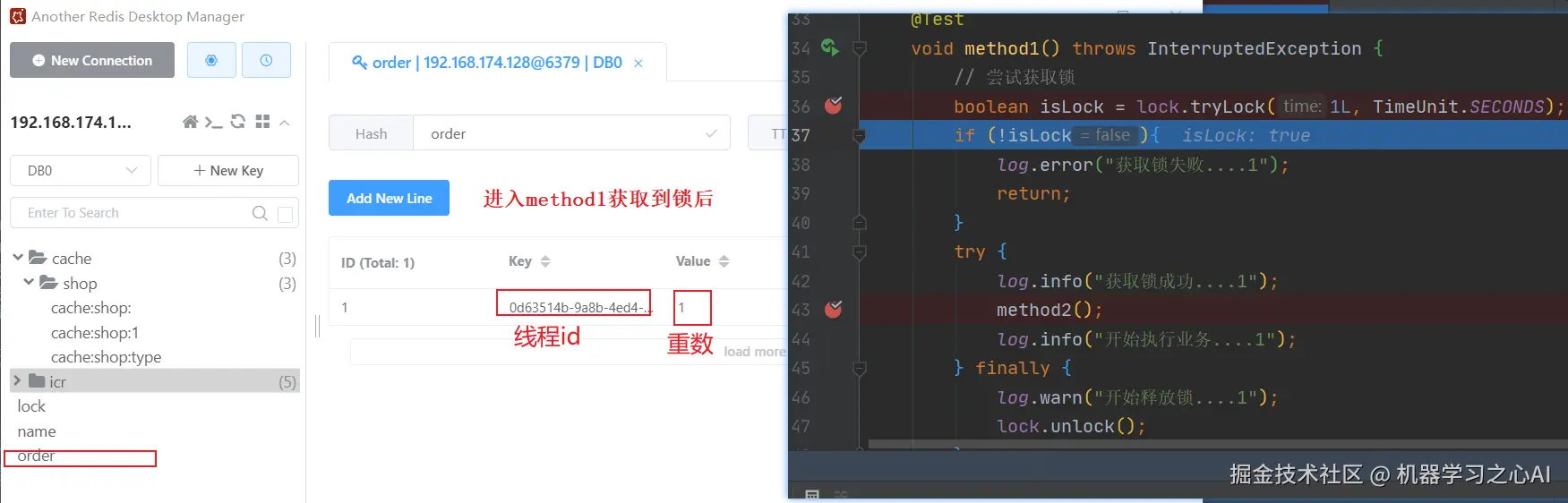

**3、接下来我们可以查看下Redisson中的分布式锁的实现:**

>
> 注意源码中的KEYS[1]指外边的大Key,AVG[1]:大Key的过期时间,AVG[2]:当前的线程ID
>
>
>

>
> 源码中的KEYS[1]指外边的大Key,AVG[2]:大Key的过期时间,AVG[3]:当前的线程ID。KEYS[2]和ARGV[1]所代表的含义我们后面会讲解~
>
>
>
#### 5.4 分布式锁-redission锁重试和WatchDog机制
关于锁可重试的原理见:<https://www.processon.com/view/link/63a86e6534446c6f609d3a3f>
关于锁超时续约 和 锁释放的原理见:<https://www.processon.com/view/link/63a891cece3d3c6150d7c2ac>
**Redission分布式锁原理**
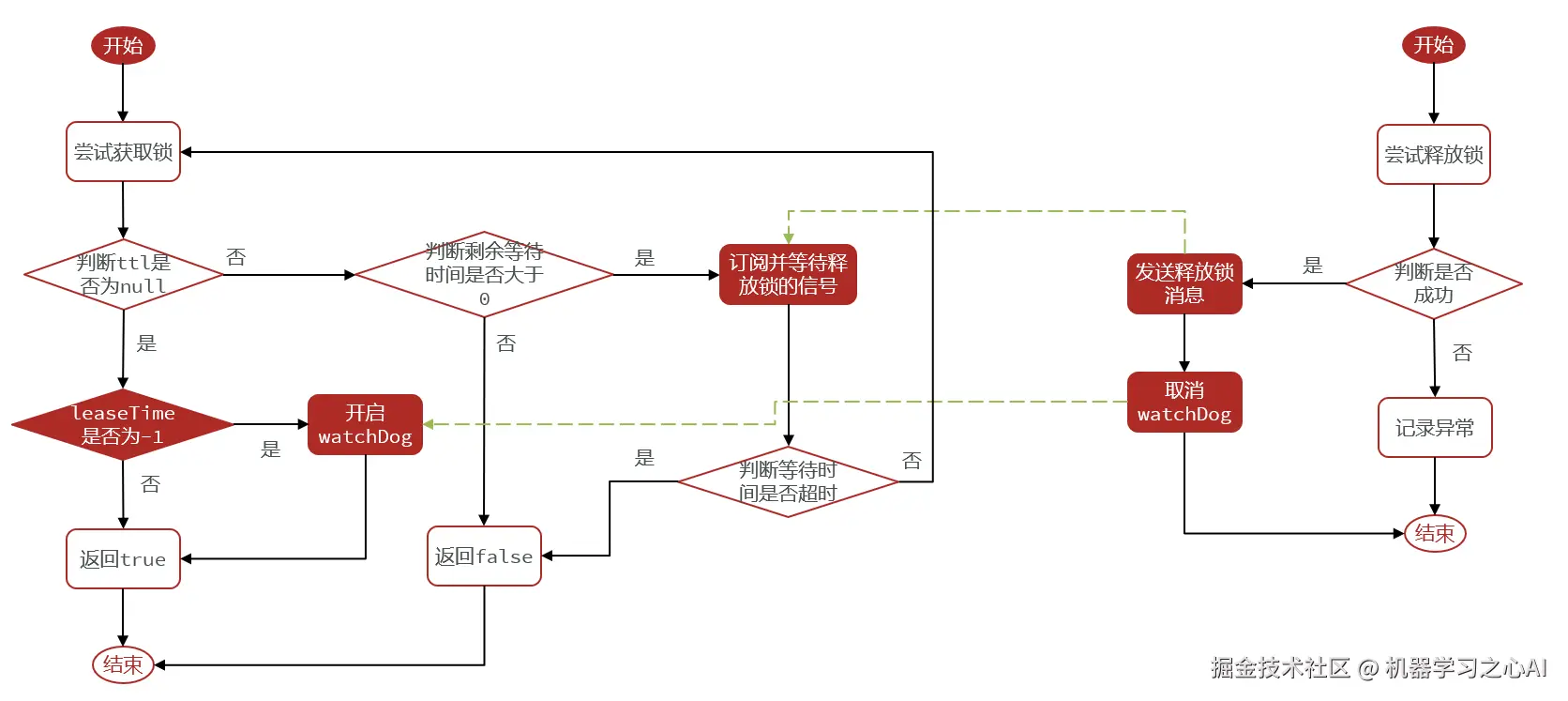
>
> 注意:只有leaseTime=-1,才会走WatchDog的逻辑
>
>
>
**总结:Redisson分布式锁原理**
* 可重入:利用hash结构记录线程id和重入次数
* 可重试:利用信号量和PubSub功能实现等待、唤醒,获取锁失败的重试机制
* 超时续约:利用watchDog,每隔一段时间(releaseTime / 3),重置超时时间
>
> **为什么需要超时续约呢?**
> 因为我们某个线程获取到锁然后开始执行业务逻辑,但是业务执行时候出现了卡顿,从而导致锁超时后会被释放。之后我这业务执行完,再次执行unlock会出错。同时超时释放别的线程会拿到分布式锁而卡顿的业务还没执行完,从而就会产生线程安全问题~
> 所以超时续约目的主要是 `当前线程获取锁后,只要没执行完就不会超时释放,会不断的超时续约`,直到业务逻辑执行完释放锁后,超时续约结束!
>
>
>
#### 5.5 分布式锁-redission锁的MutiLock原理
为了提高redis的可用性,我们会搭建集群或者主从,现在以主从为例
此时我们去写命令,写在主机上, 主机会将数据同步给从机,但是假设在主机还没有来得及把数据写入到从机去的时候,此时主机宕机,哨兵会发现主机宕机,并且选举一个slave变成master,而此时新的master中实际上并没有锁信息,此时锁信息就已经丢掉了。

为了解决这个问题,redission提出来了`MutiLock锁`,使用这把锁咱们就不使用主从了,每个节点的地位都是一样的, 这把锁`加锁的逻辑需要写入到每一个主丛节点上,只有所有的服务器都写入成功,此时才是加锁成功`,假设现在某个节点挂了,那么他去获得锁的时候,只要有一个节点拿不到,都不能算是加锁成功,就保证了加锁的可靠性。

**代码演示:**
①Linux下建立三个Redis节点(使用Docker)
docker run -p 6379:6379 --name redis -v /mydata/redis/data:/data -v /mydata/redis/conf/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf docker run -p 6380:6379 --name redis2 -v /mydata/redis2/data:/data -v /mydata/redis2/conf/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf docker run -p 6381:6379 --name redis3 -v /mydata/redis3/data:/data -v /mydata/redis3/conf/redis.conf:/etc/redis/redis.conf -d redis redis-server /etc/redis/redis.conf
②修改Redisson配置类
/** * @author lxy * @version 1.0 * @Description Redisson配置 * @date 2022/12/21 13:04 */ @Configuration public class RedissonConfig {
@Bean
public RedissonClient redissonClient(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.174.128:6379");
// 创建RedissonClient对象
return Redisson.create(config);
}
@Bean
public RedissonClient redissonClient2(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.174.128:6380");
// 创建RedissonClient对象
return Redisson.create(config);
}
@Bean
public RedissonClient redissonClient3(){
// 配置
Config config = new Config();
config.useSingleServer().setAddress("redis://192.168.174.128:6381");
// 创建RedissonClient对象
return Redisson.create(config);
}
}
③编写测试代码
@Slf4j @SpringBootTest public class RedissonTest {
@Resource
private RedissonClient redissonClient;
@Resource
private RedissonClient redissonClient2;
@Resource
private RedissonClient redissonClient3;
private RLock lock;
既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
