

单个参数
data = [1, 2, 3, 4] @pytest.mark.parametrize("item", data) def test_add(item): actual = sum(item) print("\n{}".format(actual)) # assert actual == 3
if name == 'main': pytest.main()
注意,`@pytest.mark.parametrize()`中的第一个参数,必须以字符串的形式来标识测试函数的入参,如上述示例中,定义的测试函数`test_login()`中传入的参数名为`item`,那么`@pytest.mark.parametrize()`的第一个参数则为`"item"`。
运行结果如下:
rootdir: E:\blog\python接口自动化\apiAutoTest, configfile: pytest.ini plugins: html-2.1.1, metadata-1.10.0, ordering-0.6, rerunfailures-9.1.1 collecting ... collected 4 items
test_case_2.py::test_add[1] PASSED [ 25%] 2
test_case_2.py::test_add[2] PASSED [ 50%] 3
test_case_2.py::test_add[3] PASSED [ 75%] 4
test_case_2.py::test_add[4] PASSED [100%] 5
============================== 4 passed in 0.02s ==============================
从结果我们可以看到,测试函数分别传入了data中的参数,总共执行了5次。
#### 多个参数
测试用例需传入多个参数时,`@pytest.mark.parametrize()`的第一个参数同样是字符串, 对应用例的多个参数用逗号分隔。
示例如下:
import pytest import requests import json
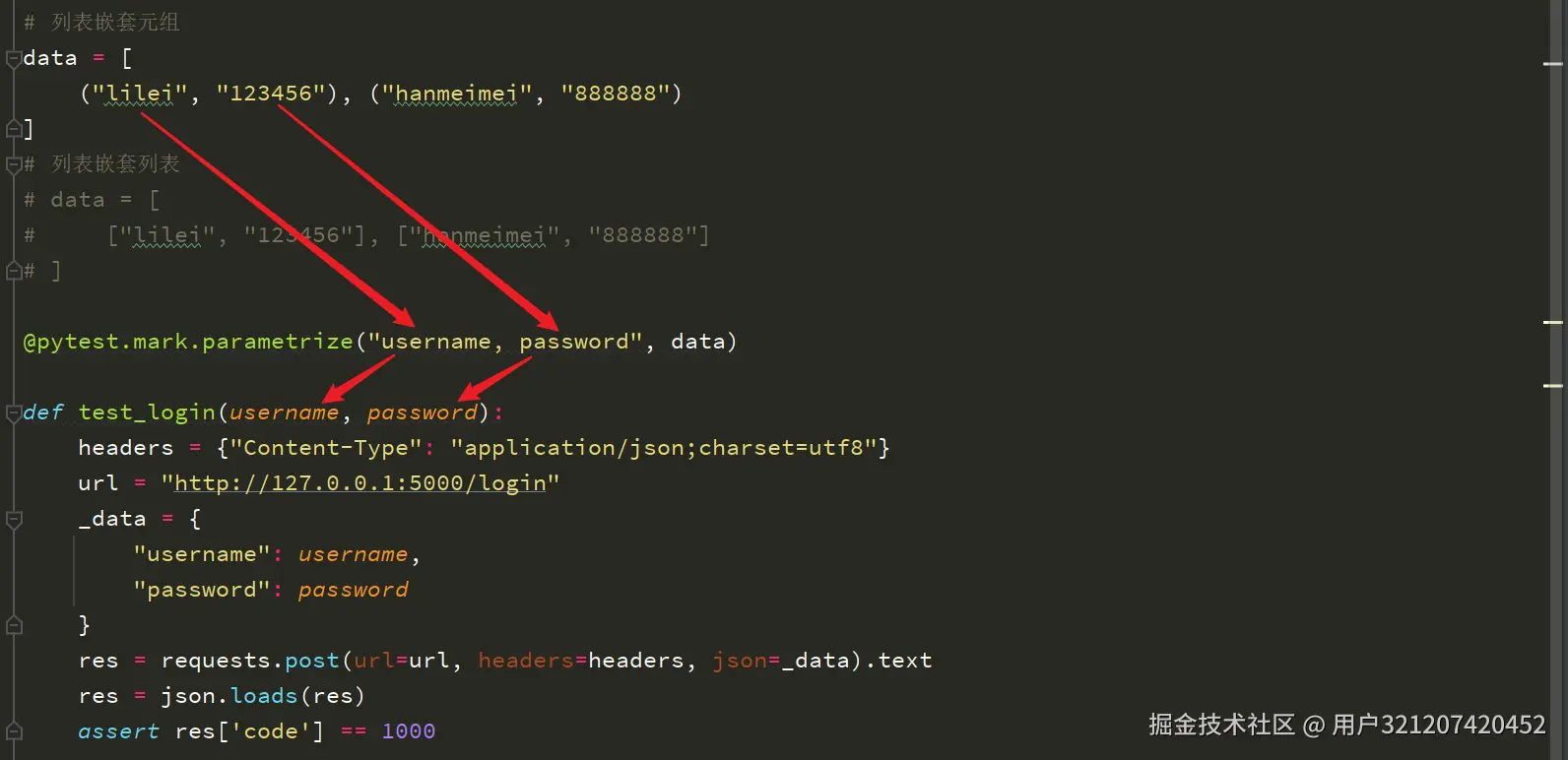
列表嵌套元组
data = [("lilei", "123456"), ("hanmeimei", "888888")]
列表嵌套列表
data = [["lilei", "123456"], ["hanmeimei", "888888"]]
@pytest.mark.parametrize("username, password", data) def test_login(username, password): headers = {"Content-Type": "application/json;charset=utf8"} url = "http://127.0.0.1:5000/login" _data = { "username": username, "password": password } res = requests.post(url=url, headers=headers, json=_data).text res = json.loads(res) assert res['code'] == 1000
if name == 'main': pytest.main()
这里需要注意:
1. 代码中`data`的格式,可以是列表嵌套列表,也可以是列表嵌套元组,列表中的每个列表或元组代表一组独立的请求参数。
2. `"username, password"`不能写成 "username", "password"。
运行结果如下:

从结果中我们还可以看到每次执行传入的参数,如下划线所示部分。
这里所举示例是2个参数,传入3个或更多参数时,写法也同样如此,一定要注意它们之间**一一对应**的关系,如下图:
#### 对测试类参数化
上面所举示例都是对测试函数进行参数化,那么对测试类怎么进行参数化呢?
其实,对测试类的参数化,就是对测试类中的测试方法进行参数化。`@pytest.mark.parametrize()`中标识的参数个数,必须与类中的测试方法的参数一致。示例如下:
将登陆接口请求单独进行了封装,仅仅只是为了方便下面的示例
def login(username, password): headers = {"Content-Type": "application/json;charset=utf8"} url = "http://127.0.0.1:5000/login" _data = { "username": username, "password": password } res = requests.post(url=url, headers=headers, json=_data).text res = json.loads(res) return res
测试类参数化
data = [ ("lilei", "123456"), ("hanmeimei", "888888") ] @pytest.mark.parametrize("username, password", data) class TestLogin: def test_login_01(self, username, password): res = login(username, password) assert res['code'] == 1000
def test_login_02(self, username, password):
res = login(username, password)
assert res['msg'] == "登录成功!"
if name == 'main': pytest.main(["-s"])
运行结果如下:
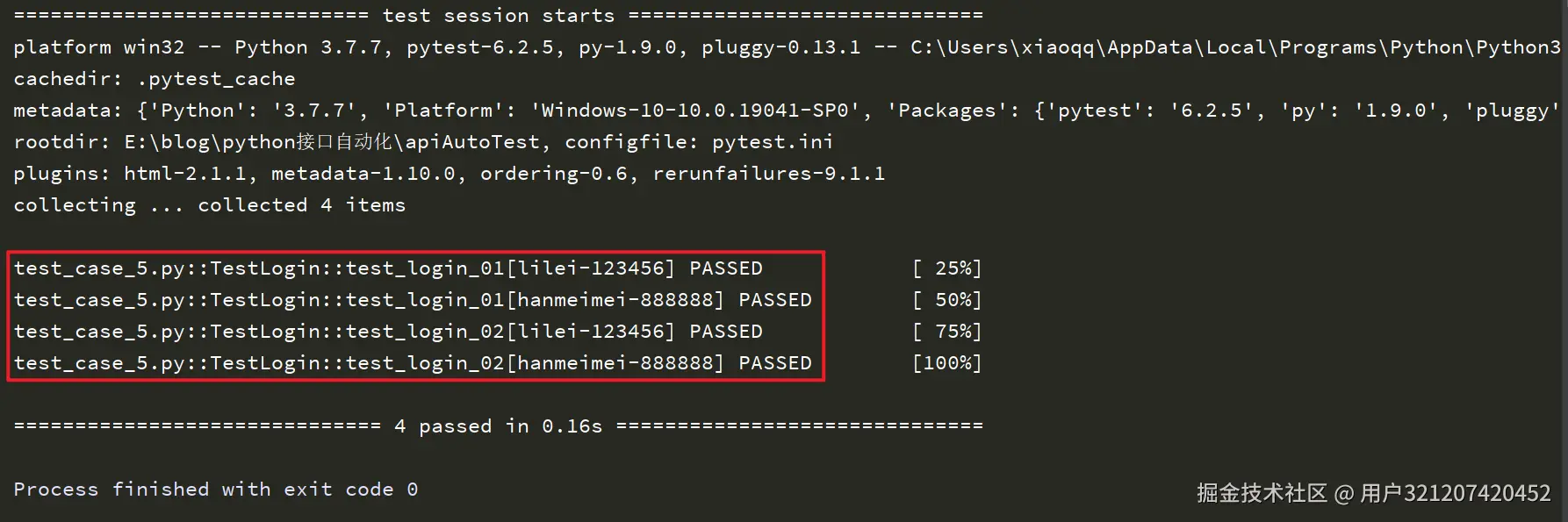
从结果中可以看出来,总共执行了`4`次,测试类中的每个测试方法都执行了`2`次,即每个测试方法都将`data`中的每一组参数都执行了一次。
注意,这里还是要强调参数对应的关系,即`@pytest.mark.parametrize()`中的第一个参数,需要与测试类下面的测试方法的参数一一对应。
#### 参数组合
在编写测试用例的过程中,有时候需要将参数组合进行接口请求,如示例的登录接口中`username`有 lilei、hanmeimei,`password`有 123456、888888,进行组合的话有下列四种情况:
{"username": "lilei", "password": "123456"} {"username": "lilei", "password": "888888"} {"username": "hanmeimei", "password": "123456"} {"username": "hanmeimei", "password": "888888"}
在`@pytest.mark.parametrize()`也提供了这样的参数组合功能,编写格式示例如下:
import pytest import requests import json
username = ["lilei", "hanmeimei"] password = ["123456", "888888"]
@pytest.mark.parametrize("password", password) @pytest.mark.parametrize("username", username) def test_login(username, password): headers = {"Content-Type": "application/json;charset=utf8"} url = "http://127.0.0.1:5000/login" _data = { "username": username, "password": password } res = requests.post(url=url, headers=headers, json=_data).text res = json.loads(res) assert res['code'] == 1000
if name == 'main': pytest.main()
运行结果如下:
rootdir: E:\blog\python接口自动化\apiAutoTest, configfile: pytest.ini plugins: html-2.1.1, metadata-1.10.0, ordering-0.6, rerunfailures-9.1.1 collecting ... collected 4 items
test_case_5.py::test_login[lilei-123456] PASSED [ 25%] test_case_5.py::test_login[lilei-888888] FAILED [ 50%] test_case_5.py::test_login[hanmeimei-123456] FAILED [ 75%] test_case_5.py::test_login[hanmeimei-888888] PASSED [100%] =========================== short test summary info =========================== FAILED test_case_5.py::test_login[lilei-888888] - assert 1001 == 1000 FAILED test_case_5.py::test_login[hanmeimei-123456] - assert 1001 == 1000 ========================= 2 failed, 2 passed in 0.18s =========================
从结果可以看出来,2个username、2个password 有4中组合方式,总执行了4次。如果是3个username、2个password,那么就有6中参数组合方式,依此类推。
注意,以上这些示例中的测试用例仅仅只是用于举例,实际项目中的登录接口测试脚本与测试数据会不一样。
#### 增加测试结果可读性
从示例的运行结果中我们可以看到,为了区分参数化的运行结果,在结果中都会显示由参数组合而成的执行用例名称,很方便就能看出来执行了哪些参数组合的用例,如下示例:

但这只是简单的展示,如果参数多且复杂的话,仅仅这样展示是不够清晰的,需要添加一些说明才能一目了然。
因此,在`@pytest.mark.parametrize()`中有两种方式来自定义上图中划线部分的显示结果,即使用`@pytest.mark.parametrize()`提供的参数 `ids` 自定义,或者使用`pytest.param()`中的参数`id`自定义。
ids(推荐)
`ids`使用方法示例如下:
import pytest import requests import json
data = [("lilei", "123456"), ("hanmeimei", "888888")] ids = ["username:{}-password:{}".format(username, password) for username, password in data] @pytest.mark.parametrize("username, password", data, ids=ids) def test_login(username, password): headers = {"Content-Type": "application/json;charset=utf8"} url = "http://127.0.0.1:5000/login" _data = { "username": username, "password": password } res = requests.post(url=url, headers=headers, json=_data).text res = json.loads(res) assert res['code'] == 1000
if name == 'main': pytest.main()
从编写方式可以看出来,`ids`就是一个`list`,且它的长度与参数组合的分组数量一致。
运行结果如下:

比较上面个执行结果,我们能看出`ids`自定义执行结果与默认执行结果展示的区别。使用过程中,需要根据实际情况来自定义。
