1.IO模型有哪些?如何理解NIO,和BIO、AIO的区别是啥?谈谈reactor模型。
IO模型分为:
1.同步阻塞IO(BIO):在执行IO操作时,如果数据没有准备好,线程或进程会被阻塞,直到数据准备好为止。
2.同步非阻塞(NIO):线程或进程在发起IO请求后,不会等待数据准备好,而是立即返回。如果数据没有准备好,返回一个错误码,应用程序需要不断地轮询检查数据是否准备好。
3.IO多路复用:允许一个线程或进程监视多个文件描述符,一旦某个文件描述符就绪(例如,有数据可读或可写),就能通知应用程序进行相应的处理。
4.信号驱动IO(SIGIO):应用程序告诉内核,当某个文件描述符就绪时,使用信号通知它。
5.异步非阻塞IO(AIO):应用程序发起IO请求后,可以立即返回,内核会在数据准备好后通知应用程序,或者在操作完成后通过回调函数返回结果。
reactor模型:
reactor是一种网络服务器端用来处理高并发网络IO请求的编程模型。它的工作机制是:
1.三类事件处理:reactor模型处理的事件主要包括连接事件、写事件、读事件。
2.三个关键角色:
Reactor:负责监听和分发事件,将IO事件分发给对应的处理器。
Acceptor:负责连接事件,当有新的连接请求时,接受连接并创建新的处理器(Handler)来处理该连接后续的读写事件。
Handler:处理读写事件,对具体的IO操作进行相应。
3.背压机制:Reactor模型的一个显著性能优势是提供了背压机制,这意味着当系统负载过高时,可以向上游发送信号,请求减少数据的发送,从而避免过载。
4.事件驱动的任务处理:
Task:待处理的任务,可以被打断并在适当的时候由Executor调度执行。
Executor:调度器,维护任务队列,包括等待运行的任务和被阻塞的任务。
Reactor:维护事件队列,当有事件发生时,通知Executor来唤醒对应的任务。
在实际应用中,如使用java的Netty框架,Reactor模型可以通过事件循环(EventLoop)来实现,每个事件循环是一个Reactor,它负责监听和分发事件,而事件的处理则由Handlers来完成。
2.反射的原理是什么?反射创建类实例的三种方式是什么?
反射的原理是基于Java虚拟机(JVM)的类加载机制。当类被加载时,JVM会在内存中创建一个对应的java.lang.Class对象,这个对象包含了类的结构信息,如构造函数、方法、字段等。通过这个Class对象,我们可以摘运行时动态地获取类的信息、创建对象实例、访问和修改成员变量、调用方法等。
反射创建类实例的三种方式如下:
1.java.lang.Class.newInstance():这种方式会调用类的无参构造函数来创建实例。如果没有无参构造函数,这种方式将抛出异常。
Class<?> clazz = Class.forName("com.example.MyClass");
Object instance = clazz.newInstance();
2.java.lang.reflect.Constructor.newInstance():这种方式通过Constructor来创建实例,可以指定调用类的特定构造函数。
Class<?> clazz = Class.forName("com.example.MyClass");
Constructor<?> constructor = clazz.getConstructor(String.class);
Object instance = constructor.newInstance("parameter");
3.sum.reflect.ReflectionFactory.newConstructorForSerialization().newInstance():这种方式是用于序列化时的特殊创建实例的方法。通过这种方式创建的实例不会初始化类的成员变量。
sum.reflect.ReflectionFactory factory = sum.reflect.ReflectionFactory.getReflectionFactory();
Constructor<?> constructor = factory.newConstructorForSerialization(clazz, Object.class.getDeclaredConstructor());
Object instance = constructor.newInstance();
3.反射中,Class.forName和ClassLoader 区别
在反射中,Class.forName和ClassLoader.loadClass都可以用来加载类,但它们在使用和加载类时的行为有一些区别:
1.Class.forName:
这是一个静态的方法,可以直接通过类名来加载对应的类。
它不仅会加载类,还会对类进行初始化,即执行类的静态初始化代码块。
使用该方法时,需要传递类的全限定名(包括包名)作为参数。
示例代码:
Class<?> clazz = Class.forName("com.example.MyClass");
2.ClassLoader.loadClass:
这是一个实例方法,需要通过ClassLoader的实例来调用。
它只加载类,但不会进行初始化,即不会执行类的静态代码块。
使用该方法时,也需要传递类的全限定名作为参数。
ClassLoader可以是系统类加载器、自定义加载器等,这允许我们更灵活地控制类的加载过程。
示例代码:
ClassLoader loader = Thread.currentThread().getContextClassLoader();
Class<?> clazz = loader.loadClass("com.example.MyClass");
Class.forName更适合需要立即使用类,并且希望类被完全初始化的场景。
ClassLoader.loadClass更适合于当你需要更细粒度地控制类加载过程,比如在实现自定义类加载器时。
4.动态代理有几种方式?有什么优缺点?
动态代理在java中主要有两种实现方式:JDK自带的代理(JDK Proxy)和基于字节码操作的库(如CGLIB、Javassis等)。
1.JDK Proxy:
优点:
最小化依赖:JDK Proxy不需要依赖额外的库,简化了开发和运维。
JDK版本升级平滑:随着JDK版本升级,JDK Proxy通常不需要额外的适配。
实现简单:使用JDK提供的API即可直接创建代理实例。
缺点:
必须实现接口:JDK Proxy要求代理的目标类必须实现至少一个接口,这对没有实现接口的类不适用。
性能:传统观点认为JDK Proxy的性能不如CGLIB,但在现代JDK版本中,性能差距已经大幅缩小。
2.CGLIB(Code Generation Libraty):
优点:
无需实现接口:CGLIB通过继承的方式生成代理类,因此不需要目标类实现任何接口,对于没有接口的类非常实用。
高性能:CGLIB直接操作字节码,通常性能会比JDK Proxy好。
灵活:可以只对关心的类生成代理,而不影响其他相关类。
缺点:
依赖外部库:使用CGLIB需要引入额外的依赖。
JDK版本兼容:字节码操作库可能在新版本Java中需要更新以保持兼容性。
变成复杂度:相对于JDK Proxy,CGLIB的使用稍微复杂一些。
代码实例:
JDK Proxy的简单使用:
InvocationHandler handler = new MyInvocationHandler(targetObject);
MyInterface proxy = (MyInterface) Porxy.newProxyInstance(
targetObject.getClass().getClassLoader(),
targetObject.getClass().getInterfaces(),
handler);
CGLIB的简单实用:
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(MyClass.class);
enhancer.setCallback(new MethodInterceptor() {
@Override
public Object intercept(Object obj, Method method, Object[] args, MethodProxy proxy) throws Throwable {
return proxy.invokeSupper(obj, args);
}
});
MyClass proxy = (MyClass) enhancer.create();
5.简述Mybatis的插件运行原理,以及如何编写一个插件?
运行原理:
Mybatis仅可以编写针对ParameterHandler、ResultSetHandler、StatementHandler、Executor这四种接口的插件,Mybatis使用JDK的动态代理,为需要拦截的接口生成代理对象以实现接口方法拦截功能,每当执行这4种接口对象的方法时,就会进入拦截方法,具体是InvocationHandler的invoke()方法,当然,只会拦截指定需要拦截的方法。
插件编写:
实现Mybatis的Interceptor接口并复写intercept()方法,然后再给插件编写注解,指定要拦截哪一个接口的哪些方法即可,配置文件中药配置编写的插件。
6.redis的高并发和快速的原因
1.redis是基于内存的,内存读写速度非常快;
2.redis是单线程的,省去了很多上下文切换线程时间
3.redis采用多路复用技术,允许它同时处理多个客户端请求,可以处理并发的连接,从而实现高吞吐率。
4.高效的数据结构:redis使用了如哈希表、跳表等高效的数据结构,这些数据结构能够提供快速的读写操作。
7.redis有哪些数据结构?
1.字符串(String)
SET mykey "hello"
GET mykey
2.列表(Lists)
LPUSH mylist "item1"
LRANGE mylist
3.集合(Sets)
SADD myset "member1"
SMEMBERS myset
4.哈希(Hashes)
HMSET myhash field1 "Hello" filed2 "world"
HGETALL myhash
5.有序集合(Sorted Set)
ZADD myzset 1 "member1"
ZRANGE myzset 0 -1 WITHSCORES
6.流(Streams,从Redis5.0开始支持)
7.位图(Bitmaps)
8.超日志(HyperLogLogs)
底层数据结构方面,Redis使用了以下几种
1.整数数组
2.双向链表
3.哈希表
4.压缩列表(ziplist)
5.跳表(skiplist)
8.谈谈Spring Bean的生命周期和作用域
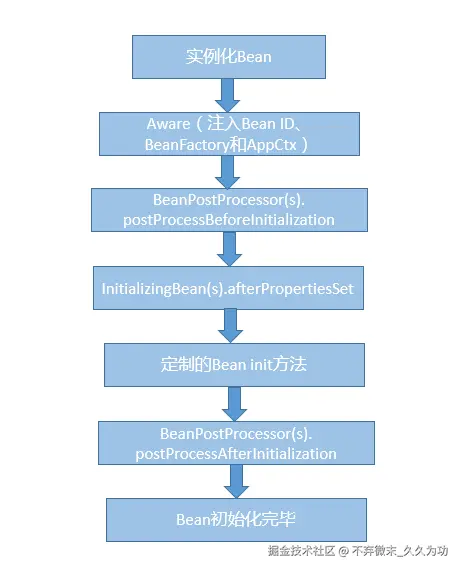
Spring Bean的生命周期主要包含以下阶段:
1.实例化:Spring容器负责创建Bean的实例。
2.依赖注入:如果Bean有依赖关系,Spring容器会在这个阶段处理依赖注入。
3.初始化:在这个阶段,Spring容器会调用Bean的初始方法(如定义了init-method)。如果Bean实现了InitializingBean接口,那么在初始化阶段还会调用afterPropertiesSet方法。
4.使用:这是Bean可以自行其业务逻辑的阶段。
5.销毁:当容器关闭时,如果Bean实现了DisposableBean接口,Spring容器会调用destroy方法。同样,如果定义了destroy-method,改方法也会调用。
import javax.annotation.PostConstruct;
import javax.annotation.PreDestroy;
import org.springframework.beans.factory.DisposableBean;
import org.springframework.beans.factory.InitializingBean;
import org.springframework.stereotype.Component;
@Component
public class MyBean implements InitializingBean, DisposableBean {
public MyBean() {
}
@Override
public void afterPropertiesSet() throws Exception {
}
@PostConstruct
public void init() {
}
@Override
public void destroy() throws Exception {
}
@PreDestroy
public void cleanup() {
}
}
Spring Bean的作用域:
1.singleton:默认作用域,容器中只存在一个Bean实例。
2.prototype:每次请求都会创建一个新的Bean实例。
3.request:每次HTTP请求都会创建一个新的Bean实例,仅适用于Web应用。
4.session:同一个HTTP Session共享一个Bean实例,仅适用于Web应用。
5.globalSession: 用于portlet应用环境,仅适用于Web应用。
6.application:整个Web应用共享一个Bean实例,仅适用于Web应用。
7.websocket: WebSocket的生命周期内共享一个Bean实例。
9.介绍下netty
Netty是一个基于Java NIO(非阻塞I/O)的成熟网络应用框架,它提供了异步和事件驱动的网络应用程序的开发工具。Netty主要用于构建高性能、高可靠性的网络服务器和客户端程序。
以下是对Netty的总结:
1. 提高稳定性:由于网络编程的复杂性,Netty提供了处理网络闪断、客户端重复接入、连接管理、安全认证等细节的解决方案,这些功能经过长时间打磨,稳定性高。
2. 降低开发成本:Netty封装了Java NIO的复杂性,开发者不需要处理底层的复杂多线程模型和缓冲区管理,可以快速开发网络应用。
3. 性能优势:
- 支持多种序列化框架,通过ChannelHandler机制,可以自定义编码和解码器。
- 提供线程池模式和Buffer重用机制,有助于性能调优。
4. 易于学习和使用:Netty通过简单的例子和组件,如EchoClient和EchoServer,让开发者容易理解其工作原理。
以下是使用Netty创建一个简单服务端的代码示例:
public class EchoServer {
private final int port;
public EchoServer(int port) {
this.port = port;
}
public void start() throws Exception {
final EchoServerHandler serverHandler = new EchoServerHandler();
EventLoopGroup group = new NioEventLoopGroup();
try {
ServerBootstrap b = new ServerBootstrap();
b.group(group)
.channel(NioServerSocketChannel.class)
.localAddress(new InetSocketAddress(port))
.childHandler(new ChannelInitializer<SocketChannel>() {
@Override
public void initChannel(SocketChannel ch) throws Exception {
ch.pipeline().addLast(serverHandler);
}
});
ChannelFuture f = b.bind().sync();
f.channel().closeFuture().sync();
} finally {
group.shutdownGracefully().sync();
}
}
public static void main(String[] args) throws Exception {
int port = 8080;
new EchoServer(port).start();
}
}
class EchoServerHandler extends ChannelInboundHandlerAdapter {
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) {
ctx.write(msg);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) {
ctx.flush();
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) {
cause.printStackTrace();
ctx.close();
}
}
在这个示例中,我们创建了一个EchoServer,它监听8080端口,并将接收到的消息打印到控制台。EchoServerHandler类继承自ChannelInboundHandlerAdapter,用于处理服务器端的I/O事件。这段代码展示了如何使用Netty构建一个简单的服务器端应用程序。
10.常用的分布式ID设计
常用的分布式ID设计主要解决在分布式系统中如何生成全局唯一ID的问题
1.单体环境下的解决方案:
使用内存中的计数器:在单节点应用中,可以通过内存中的计数器来计算生成唯一ID。这种方法简单但可能导致ID含义暴露,需要通过加密算法混淆。
2.分布式环境下的解决方案:
独立组件远程调用:例如,使用Redis的INCR命令或Zookeeper等中间件生成唯一ID。
Snowflake算法:Twitter开源的分布式ID生成算法,通过组合时间戳、机器ID、数据中心ID和序列号来生成唯一ID。
MongoDB ObjectId:MongoDB内置12字节ID,包含时间戳、机器ID、进程ID和计数序列。
国内大厂开源实现:如微信的seqsvr、百度的uid-generator等,这些实现通常根据特定的业务场景进行优化。
3.关于Snowflake算法:
snowfke算法通常不会受到夏令时或冬令时切换的影响,因为它依赖于System.currentTimeMillis(),这个时间戳是从1970年1月1号UTC时间开始计算的,与具体的时区无关。
代码实现如下:
public class SnowflakeIdGenerator {
private long workerId;
private long datacenterId;
private long sequence = 0L;
private long twepoch = 1288834974657L;
private long workerIdBits = 5L;
private long datacenterIdBits = 5L;
private long maxWorkerId = -1L ^ (-1L << workerIdBits);
private long maxDatacenterId = -1L ^ (-1L << datacenterIdBits);
private long sequenceBits = 12L;
private long workerIdShift = sequenceBits;
private long datacenterIdShift = sequenceBits + workerIdBits;
private long timestampLeftShift = sequenceBits + workerIdBits + datacenterIdBits;
private long sequenceMask = -1L ^ (-1L << sequenceBits);
public SnowflakeIdGenerator(long workerId, long datacenterId) {
if (workerId > maxWorkerId || workerId < 0) {
throw new IllegalArgumentException("workerId can't be greater than %d or less than 0");
}
if (datacenterId > maxDatacenterId || datacenterId < 0) {
throw new IllegalArgumentException("datacenterId can't be greater than %d or less than 0");
}
this.workerId = workerId;
this.datacenterId = datacenterId;
}
public synchronized long nextId() {
long timestamp = timeGen();
if (timestamp < lastTimestamp) {
throw new RuntimeException("Clock moved backwards. Refusing to generate id");
}
if (lastTimestamp == timestamp) {
sequence = (sequence + 1) & sequenceMask;
if (sequence == 0) {
timestamp = tilNextMillis(lastTimestamp);
}
} else {
sequence = 0L;
}
lastTimestamp = timestamp;
return ((timestamp - twepoch) << timestampLeftShift) |
(datacenterId << datacenterIdShift) |
(workerId << workerIdShift) |
sequence;
}
private long tilNextMillis(long lastTimestamp) {
long timestamp = timeGen();
while (timestamp <= lastTimestamp) {
timestamp = timeGen();
}
return timestamp;
}
private long timeGen() {
return System.currentTimeMillis();
}
}
这段代码是一个简化版的Snowflake算法实现,用于生成全局唯一的ID。实际使用时,需要根据实际环境设置合适的workerId和datacenterId。


