

在开发过程中,我们经常遇到需要将数据库的行数据(扁平数据)转换成树形数据使用的场景,例如菜单、组织机构等数据。面对这种需求,我们该如何处理呢?这里根据多年开发经验,总结了三种处理方式供大家参考。
递归方式
递归方式是常规做法,但是该方式会生成大量堆栈数据,不适合处理大数据的情况,且需要多次方法调用每次函数执行都会遍历一遍数据,所以该方式性能最差。我还见过递归查询数据库的,那性能只能说惨不忍睹。
public static <T> List<T> toTree(List<T> list, Long parentId) {
List<T> rs = new ArrayList<>();
for (T t : list) {
// `parentId` 相等就是其子级
if (Objects.equals(parentId, t.getParentId())) {
// 递归查找子级
List<T> ts = toTree(list, t.getId());
t.setChildren(ts);
rs.add(t);
}
}
return rs;
}
双重循环
双重循环方式是利用第一重循环遍历每一条数据,第二重循环筛选出每条数据的直接子级。该方式是嵌套循环,时间复杂度和递归一样,但是这里没有函数调用所以性能更好。
List<T> tree = new ArrayList<>();
// 遍历数据库查出的扁平数据 `list`
for (T t : list) {
// 筛选根节点
if (t.getParentId() == null) {
tree.add(t);
}
// 查找每一条数据的直接子级
t.setChildren(list.stream()
.filter(x -> Objects.equals(x.getParentId(), t.getId()))
.collect(Collectors.toList()));
}
// 得到树形数据结构结果
return tree;
分组 + 循环
第一步按照父 id 对扁平数据进行分组,第二步使用循环为每一条数据的 children 字段赋值。这种方式总共只需遍历两遍数据,所以较前两种方式性能最好。
// 按父 `id` 分组
Map<Long, List<T>> map = list.stream().collect(Collectors.groupingBy(T::getParentId));
// 遍历设置 `children`
for (T t : list) {
t.setChildren(map.get(t.getId()));
}
// 获取根节点组返回(根节点父 `id` 必须是特定值,这里传入相应的值)
return map.get(0L);
 如果你还有其他实现方式,欢迎在评论区留言探讨。
如果你还有其他实现方式,欢迎在评论区留言探讨。
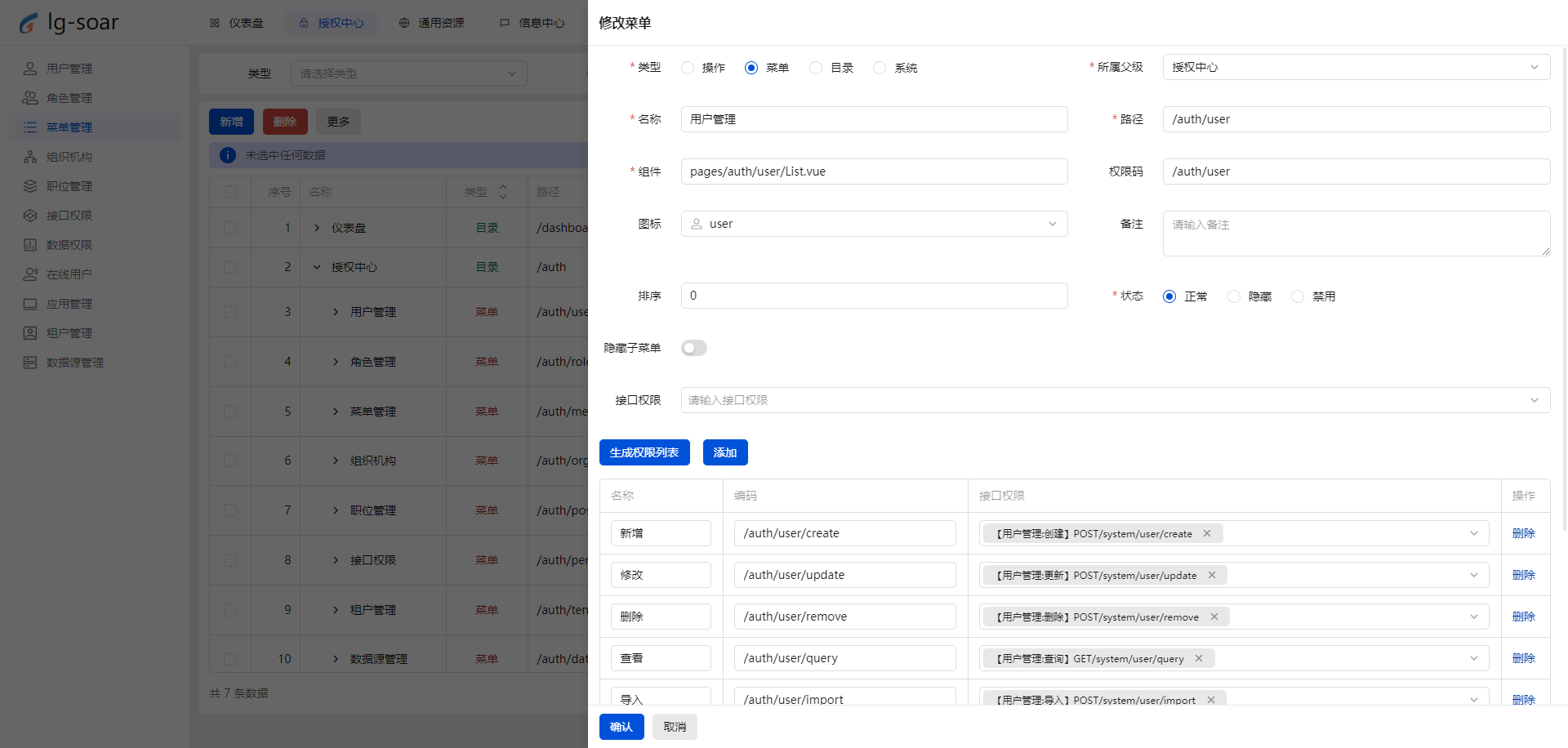
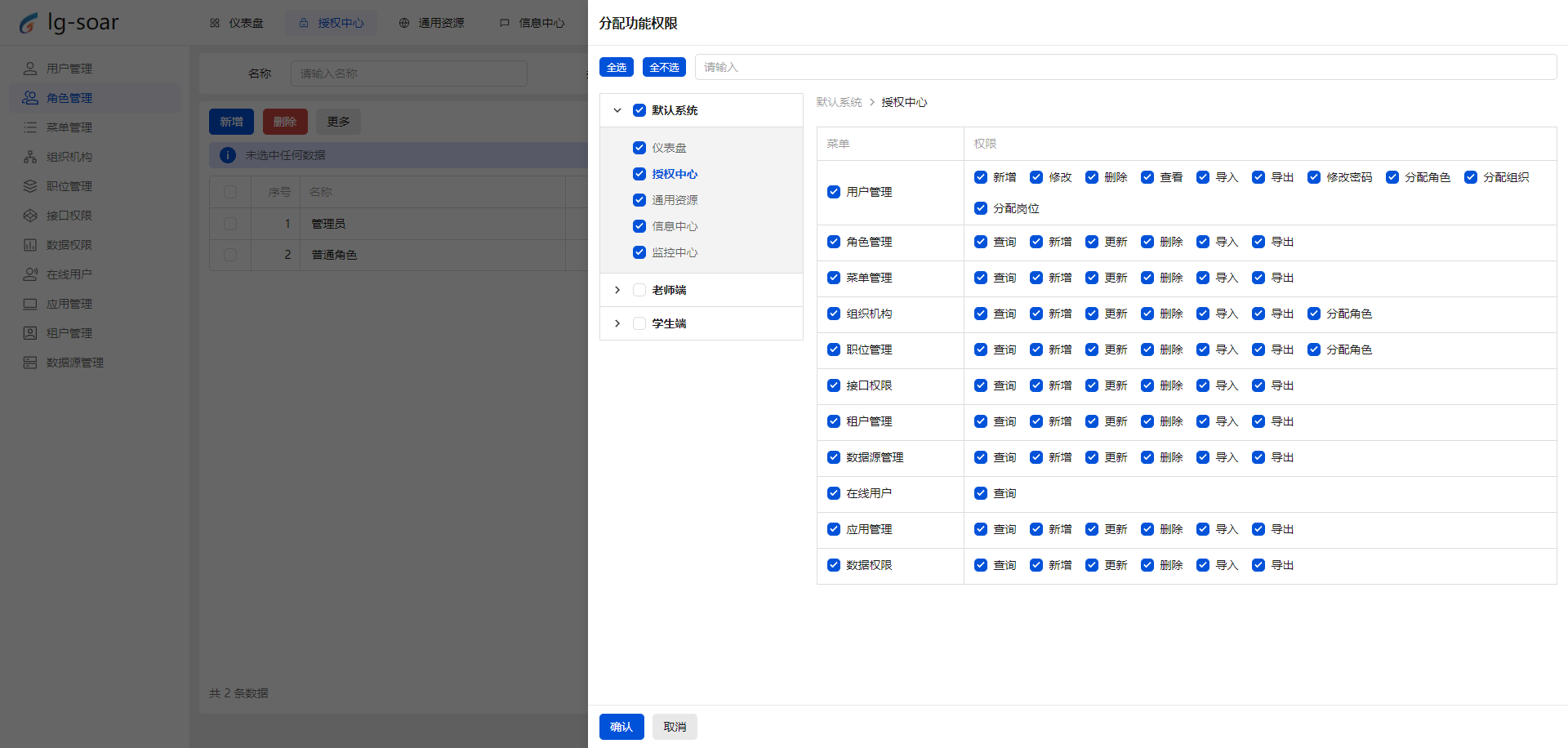
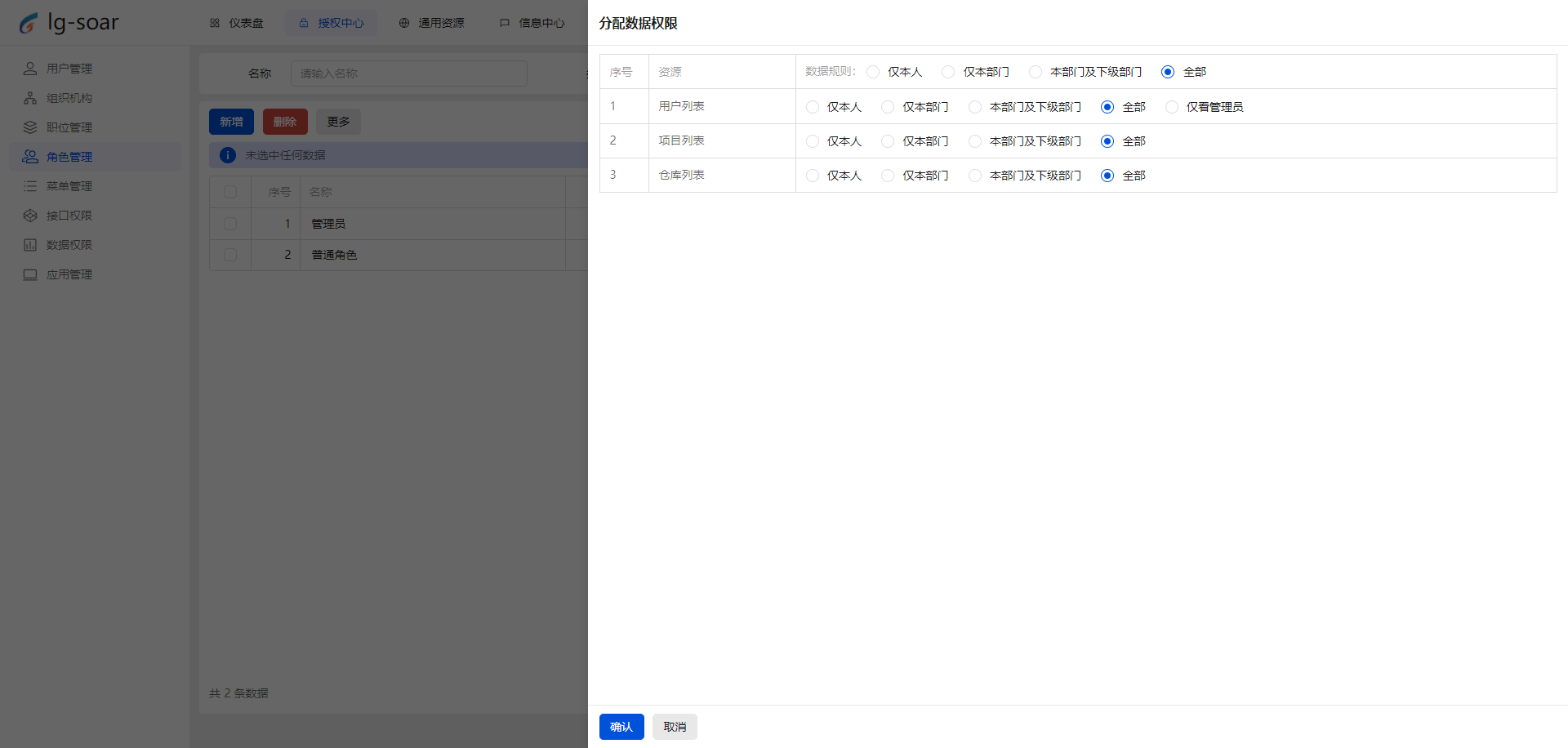
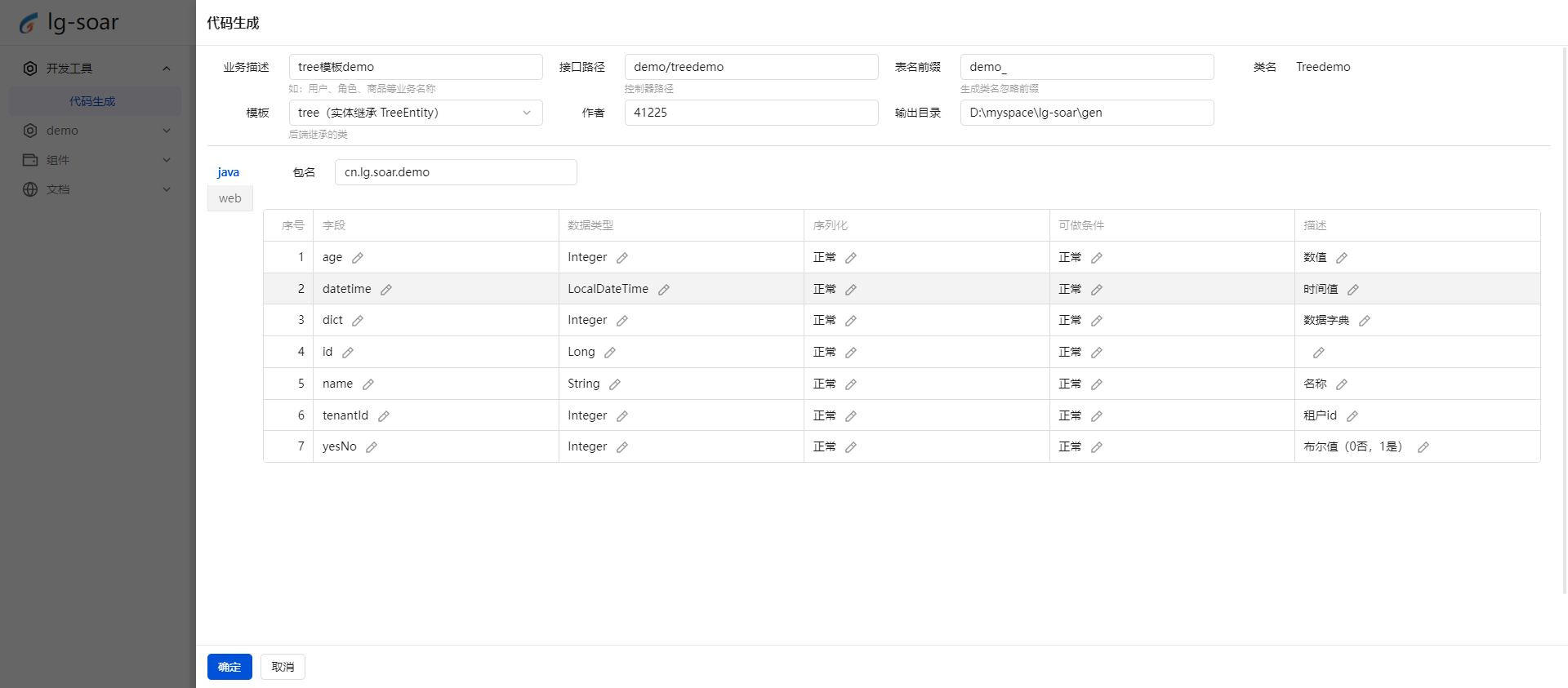
- 推荐一个前后端脚手架 lg-soar:助力开发者腾飞的利器
- 原文连接 将数据库行数据变成树形数据的三种方式

