引言
- 前几天使用 LR 作为 baseline 模型进行参数调优时,使用到了交叉验证和网格搜索的方法意外发现了GridSearchCV和cross_val_score的不同用法,本文作为学习记录,仅供参考。
GridSearchCV 主要用于对给定模型的超参数进行穷举搜索和选择。它会尝试不同的超参数组合,并根据交叉验证的结果选择最优的超参数组合。cross_val_score 主要用于对给定的模型和固定的参数,进行交叉验证并计算评估指标得分
- cv: 交叉验证折数或可迭代的次数,默认None,使用三折交叉验证。即fold数量默认为3,参数也可以是yield生成的迭代器
- n_jobs: 同时工作的cpu个数
- 1 作用:确定计算cpu内核的使用数量
- 2 默认n_jobs = 1,表示使用计算机的一个核进行处理;
- 3 n_job = 2/3/4,表示使用2/3/4个核同时处理,提高运行效率
- 4 n_jobs = -1,表示计算机有几个核就使用几个核进行运算
- fit_params:拟合方法的参数
cross_val_score 示例如下
from sklearn import datasets
from sklearn.model_selection import train_test_split,cross_val_score
from sklearn.neighbors import KNeighborsClassifier
import matplotlib.pyplot as plt
iris = datasets.load_iris()
X = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=12)
k_range = range(1,10)
cv_scores = []
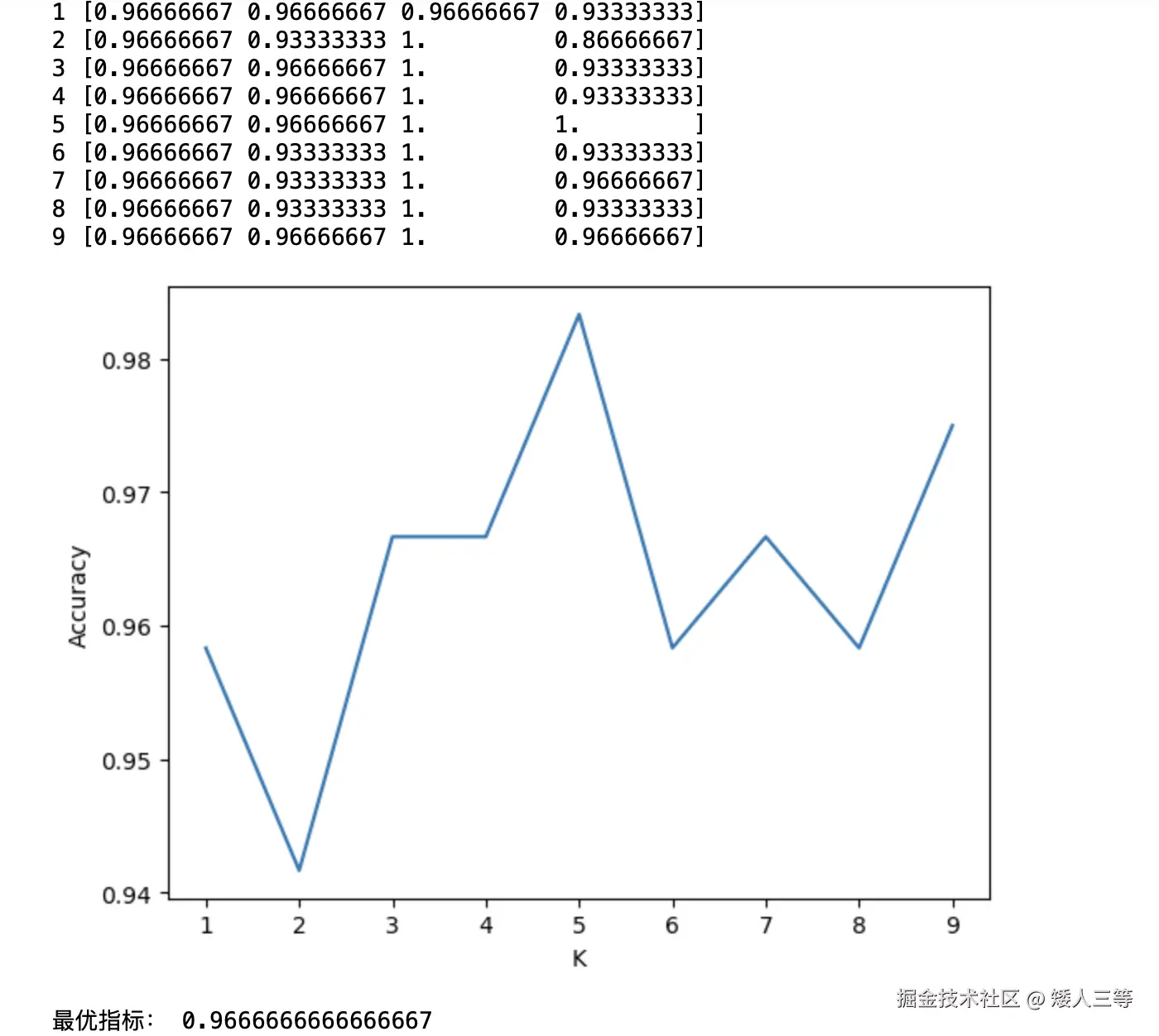
for n in k_range:
knn = KNeighborsClassifier(n)
scores = cross_val_score(knn,x_train,y_train,cv=4,scoring='accuracy')
print(n,scores)
cv_scores.append(scores.mean())
plt.plot(k_range,cv_scores)
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.show()
best_knn = KNeighborsClassifier(n_neighbors=5)
best_knn.fit(x_train,y_train)
print("最优指标:", best_knn.score(x_test,y_test))
GridSearchCV示例如下
- param_grid – 需要优化的参数字典组合
- scoring = None :模型评价指标,默认为None;或者如scoring = ‘roc_auc’
- cv,n_jobs同上
- verbose:控制输出的详细程度:
verbose=0 通常表示几乎不输出任何信息,只在必要时输出关键的错误或警告verbose=1 可能会输出一些基本的进度信息或重要的步骤描述。verbose=2及以上 会提供更详细的每一步的信息。
- best_score_:交叉验证中最优解
- best_estimator_:最优参数模型
- best_params_:最优参数
- estimator.cv_results_: dict of numpy (masked) ndarrays,每次交叉验证后的验证集准确率结果和训练集准确率结果
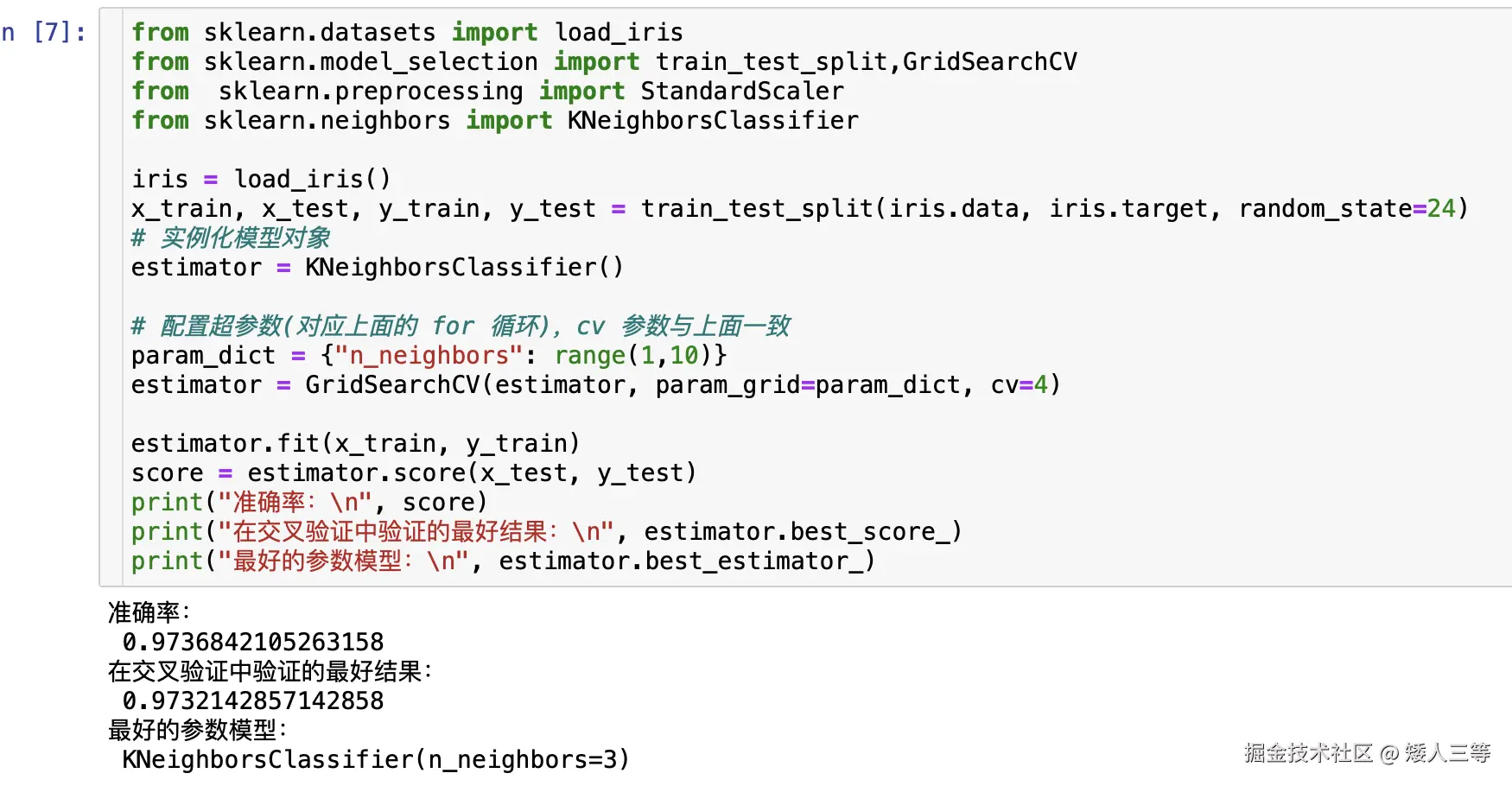
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split,GridSearchCV
from sklearn.preprocessing import StandardScaler
from sklearn.neighbors import KNeighborsClassifier
iris = load_iris()
x_train, x_test, y_train, y_test = train_test_split(iris.data, iris.target, random_state=24)
estimator = KNeighborsClassifier()
param_dict = {"n_neighbors": range(1,10)}
estimator = GridSearchCV(estimator, param_grid=param_dict, cv=4)
estimator.fit(x_train, y_train)
score = estimator.score(x_test, y_test)
print("准确率:\n", score)
print("在交叉验证中验证的最好结果:\n", estimator.best_score_)
print("最好的参数模型:\n", estimator.best_estimator_)
总结
- GridSearchCV :除了自行完成叉验证外,还返回了最优的超参数及对应的最优模型,使用更为方便;
- cross_val_score :一般用于获取每个 fold的交叉验证的得分,然后根据这个得分为模型选择合适的超参数,但是通常需要编写循环手动完成交叉验证过程。


