Spark优化经验(2)
引言
- 本文章为个人学习公司一个技术大佬写的 Spark 相关技术文档,个人手敲摘录的部分内容以及个人补充,涉密原因图片仅供参考(实际例子截图不能外传,且本地我没办法布集群,so...)
- 如果有错误欢迎指正,有问题可以一起探讨(由于本人非大数据岗,所以可探讨内容有限,文章内容参考即可)。
- 后续会补充其他Spark 的相关问题。
3 参数优化及使用说明
- 核心参数配置说明
- num-executor
- 每个 node 的 executors 数 = 单节点 yarn 总核数/每个 executor的 cpu 核数
- 比如:yarn.nodemanager.resource.cpu-vcores 配置为:64,参数 executor-cores 的值为:4,那么每个 node 的 executors 数 = 64 / 4 = 16,假设集群节点为 329,那么总的 num-executors = 16 * 329 = 5264;
- num-executors * executors-memory < 资源队列最大内存量,申请的内存建议不超过资源队列最大内存的 2/3,避免 Spark 作业占用资源队列全部资源,导致共用资源队列的任务无法运行;
- executor-memory
- 该参数最大值 = yran-nodemanager.resource.memory-mb / 每个节点的 executors 的数量
- 比如:yarn 的参数配置为 500G,单节点 num-executors 值为 16,那么每个 executors 最大值内存为 500G / 16 ≈ 31G,同时要注意 yarn 配置中每个容器允许的最大内存是否匹配。
- num-executors * executors-memory < yarn 资源队列最大内存,若与其他用户共享 yarn 资源队列,则最好不要超过 yarn 资源队列的 1/3 - 1/2.通常设置 4G-8G 较为合适
- executor-core
- 每个 executors 的最大核数,此参数设置每个 executors 进程cpu core 数量,此参数决定每个 executors 进程并行执行 task 线程能力。
- num-executors * executors-cores < yarn 资源队列最大 cores,若与其他用户共享 yarn 队列,则最好不要超过 yarn 资源队列的 1/3 - 1/2, 通常设置 2-4 个较为合适
- 每个并行度的数据量(总数据量/并行度)在(executor内存/core数/2,executor内存/core 数)取件提交执行
- driver-memory
- 指定 driver 可使用的内存大小,默认值为 1G
- 调优建议:一般保持默认值即可,但是使用 collect 等算子将数据收集到 driver 端,需要加大内存,不然容易造成 OOM(内存溢出)
- Spark.default.parallelism
- 参数说明:用户未设置时,由join,reduceByKey 和 parallelize等算子转换返回的 RDD 默认分区数。对于 reduceBeKey 好 join 等分布式 shuffle 操作,参数默认值为父RDD 中分区的最大数量;
- 而对于 parallelize等无父 RDD 的操作,参数取决于集群管理器,在 yarn 模式下,参数为所有 executors 节点的内核数与 2 的最大值
- 调优建议:参数值为 num-executors * executors-cores 的 2-3 倍较为合适
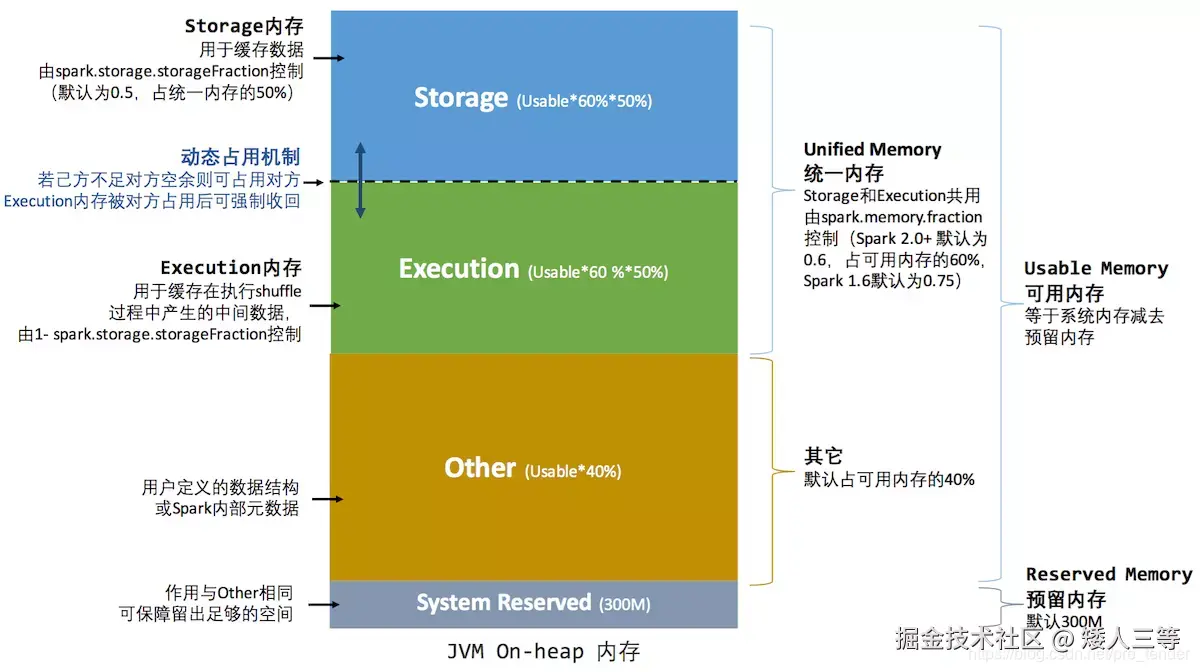
- 内存使用说明
4 案例优化实操
- 背景(参考即可):一个查询任务中,累计创建 92 张临时视图,作业耗时过长 10h+,针对此情况给出的一个方法1 是将临时视图改为实体表 2 增加基于业务特性的 Spark 参数,效果明显明显(10h43min -- > 19 分钟)
- 结论:
- 若多次调用临时试图的需求,变成实体表可避免反复计算临时视图的问题,以加快查询(11h --> 0.5h)
- 对于复杂的查询语句,需根据业务特性调优,本次重点针对 cbo 参数调优,计算速度提升明显(29min --> 19min)
- cbo:基于成本的优化
- 临时视图或串行跑任务速度调优:
- A 视图计算完成后储存在内存中,B 视图计算的时候可能因为内存不够导致 shuffle 溢出,速度下降很多。
- 调用临时试图需重新计算试图结果集,替换实体表将过程结果预计算完成并储存,提升查询效率
- 将任务拆分,如 A 和 B 并行跑,结束跑C 任务
- 多 join 过程启用 join 顺序调整策略
- 广播小表避免 shuffle 过程
后续待继续完善内容
- 待补充 1:Spark 作业报错信息库
- 待补充 2:Spark 问题排查模板
- 待补充 3:Spark 开发优化指引
- 待补充 4:Spark 任务调优策略
- 待补充 5:参数优化使用说明
- 待补充 6:Spark3 资源评估
- 待补充 7:Spark3.3 新特性


