

Note. 1
The law of large numbers and the probability of obtaining a majority ?
Law of Large Number
In probability theory, the law of large numbers (LLN) is a mathematical theorem that states that the averge of results obtained from a large number of independent random samples converges to the true value, if it exists. More formally, the LLN states that given a sample of independent and identically distributed values, the sample mean converges to the true mean.
Probability of Obtaining A Majority
The probability of obtaining a majority meatures the likelihood that one outcome will dominate another in repeated trials. In the case of a biased coin (eg., 51% chance of heads), the probability that heads will be in the majority increases as the nmuber of tosses increases, due to the cumulative effect of the bias.

Fig. 1. The law of large number.
Note. 2
The bias & variance, underfitting & overfitting, and bias-variance tradeoff in machine learning?
Bias & Variance
A supervised Machine Learning model aims to train itself on the input variables in such a way that the predicted values are as close to the actual values as possible. This difference between the actual values and predicted values is the error and it is used to evaluate the model. The error for any supervised Machine Learning algorithm comprises of 3 parts:
Bias error
Variance error
Noise
While the noise is the irreducible error that we cannot eliminate, the other two i.e. Bias and Variance are reducible errors that we can attempt to minimize as much as possible.
1. In statistics, the bias of an estimator (or bias function) is the difference between this estimator's expected value and the true value of the paramater being estimated.
A linear algorithm often has high bias, which makes them learn fast. In linear regression analysis, bias refers to the error that is introduced by approximating a real-life problem, which may be complicated, by a much simpler model. The simpler the algorithm, the more bias it has likely introduced.
Technically, we can define bias as the error between average model prediction and the ground truth. Moreover, it describes how well the models matches the training data set:
A model with a higher bias pays very little attention to the training data and oversimplifies the model. This typically results in underfitting.
A low bias model will closely match the training data set. However, if the bias is too low, it might lead to overfitting.
For more information, pleace clink it.
2. In statistics, variancce is an error from sensitivity to small fluctuations in the training set.

Fig. 2. The meaning of high variance.

Fig. 3. The meaning of low variance.

Fig. 4. A:Graphical illustration of bias and variance. B: The variation of Bias and Variance with the model complexity. This is similar to the concept of overfitting and underfitting. More complex models overfit while the simplest models underfit. Source: scott.fortmann-roe.com/docs/BiasVa…
Underfitting & Overfitting
The term underfitting and overfitting refer to how the model fails to match the data.
3. Underfitting occurs when a mathematical model cannot adequately capture the underlying structure of the data. Underfitting the training set is when the loss is not as low as it could be because the hasn't learnded enough features (That is, there is no "serious" learn).
4. Overfitting is the production of an analysis that corresponds too closely or exactly to a parrticular set of data, and may therefore fail to fit to additional data or predict future observations reliably. Overfitting the training set is when the loss is not as low as it could be because the learnded too much features (That is, "seriously" learned, however, to learn only"one set of volumes").
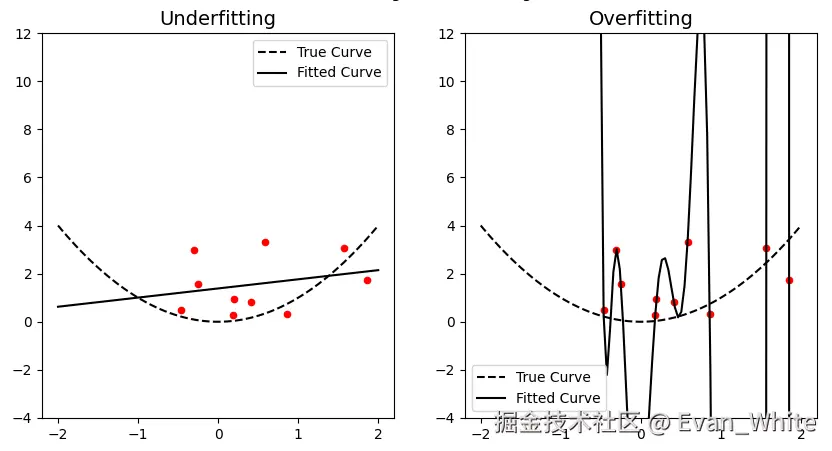
Fig. 4. Underfitting and Overfitting.
Bias-variance Tradeoff
Bias and variance are inversely connected. It is impossible to have an machine learning model with a low bias and a low variance.
5. In statistics and machine learning, the bias-variance tradeoff describes the relationship between a model's complexity, the accuracy of its predictions, and how well it can make predictions on previously unseen data that were not used to train the model.
The tradeoff in multiple ways:
- Increasing the complexity of the model to count for bias and variance, thus decreasing the overall bias while increasing the variance to an accpetable level.
- Increasing the training data set can also help to balance this tradeoff, to some extent. This is prefered method when dealing with overfitting models.
