

前一篇我们讲了二叉树的基本概念, 今天我们来讲一讲二叉树的遍历顺序
深度遍历 和 广度遍历 , 其中深度遍历又被划分为 前序遍历、中序遍历、后序遍历, 广度遍历被划分为层序遍历
前序、中序、后序的区别是根节点位置不同
1、前序遍历
优先访问根节点, 其次左子树, 再右子树的遍历顺序称为前序遍历
然后在左子树里继续中左右....以此迭代
中左右 这里的中代表根节点
例子
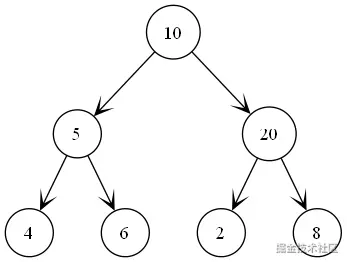
结果为:
遍历过程:
1、优先处理10
2、然后处理10的左子树
3、在 这棵左子树里继续中左右, 所以处理顺序为
4、左子树处理完毕, 开始处理右子树
5、继续中左右, 得到
6、连在一起为 [10, 5, 4, 6, 20, 2, 8]
递归步骤
首先讲代码之前, 先来了解下递归三部曲
1、 确定递归函数的参数和返回值
2、 确定终止条件
3、 确定单层递归逻辑
其实对于二叉树来说, 只要明确一个节点要做的事情, 那么剩下的交给递归就行了, 毕竟二叉树都是由节点构成的
递归解释
1、对于二叉树来说, 参数一般是传入根节点 和 用来保存结果的 , 无返回值
2、遇到空节点就返回上层
3、中左右 我们要先处理根节点, 怎么处理根节点, 是不是只要把根节点的 放入 里就行了呀, 然后去遍历我们的左子树, 再去遍历我们的右子树
中左右 中左右 , 就是先处理中, 再处理左, 然后再处理右
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
result = []
self.dfs(root, result)
return result
# 递归函数, 传入根节点, 和result
def dfs(self, root, result):
if not root: return # 遇到空节点就返回上层
result.append(root.val) # 处理当前节点
self.dfs(root.left, result) # 处理左子树
self.dfs(root.right, result) # 处理右子树
拿上面的例子来说, 一个节点的处理顺序是: 处理根节点(push到list里), 然后处理根节点的左子树, 处理根节点的右子树, 其余节点只要交给递归即可
额外说明一点, 对于叶子节点 来说, 根为 , 左子树为空, 右子树也为空
2、中序遍历
优先访问左子树, 然后在左子树里继续左子树, 根节点, 右子树....以此迭代 , 其次根节点, 再右子树的遍历顺序称为中序遍历
左中右 这里的中代表根节点
例子
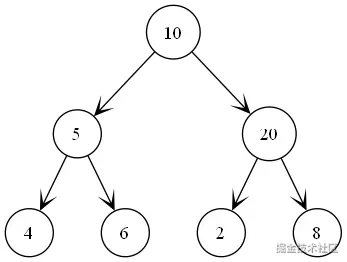
结果为:
遍历过程:
1、优先处理左子树
2、然后在 处理左节点
3、处理根
4、处理右节点
5、处理根节点
6、处理右子树
7、然后在 处理左节点
8、处理根
9、处理右节点
10、连在一起为 [4, 5, 6, 10, 2, 20, 8]
递归步骤
再来了解下递归三部曲
1、 确定递归函数的参数和返回值
2、 确定终止条件
3、 确定单层递归逻辑
其实对于二叉树来说, 只要明确一个节点要做的事情, 那么剩下的交给递归就行了, 毕竟二叉树都是由节点构成的
递归解释
1、对于二叉树来说, 参数一般是传入根节点 和 用来保存结果的 , 无返回值
2、遇到空节点就返回上层
3、左中右 我们要先处理左子树, 再处理根节点, 再去处理我们的右子树
左中右 左中右 , 就是先处理左子树, 再处理中, 然后再处理右子树
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
result = []
self.dfs(root, result)
return result
# 递归函数, 传入根节点, 和result
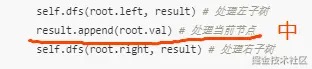
def dfs(self, root, result):
if not root: return # 遇到空节点就返回上层
self.dfs(root.left, result) # 处理左子树
result.append(root.val) # 处理当前节点
self.dfs(root.right, result) # 处理右子树
3、后序遍历
优先访问左子树, 在左子树里也遵循 左右中, 然后右子树, 最后根节点的顺序称为后序遍历
左右中
例子
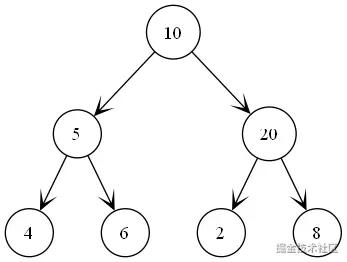
结果为:
遍历过程:
1、优先处理左子树
2、然后在 处理左节点
3、处理右节点
4、处理根
4、处理右子树
5、然后在 处理左节点
6、处理右节点
7、处理根
8、处理根节点
9、连在一起为 [4, 6, 5, 2, 8, 20, 10]
递归步骤
最后再来熟悉下递归三部曲
1、 确定递归函数的参数和返回值
2、 确定终止条件
3、 确定单层递归逻辑
其实对于二叉树来说, 只要明确一个节点要做的事情, 那么剩下的交给递归就行了, 毕竟二叉树都是由节点构成的
递归解释
1、对于二叉树来说, 参数一般是传入根节点 和 用来保存结果的 , 无返回值
2、遇到空节点就返回上层
3、左右中 我们要先处理左子树, 再处理右子树, 最后处理我们的根节点
左右中 左右中 , 就是先处理左子树, 再处理右子树, 然后再处理中
class Solution:
def preorderTraversal(self, root: Optional[TreeNode]) -> List[int]:
result = []
self.dfs(root, result)
return result
# 递归函数, 传入根节点, 和result
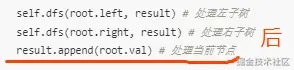
def dfs(self, root, result):
if not root: return # 遇到空节点就返回上层
self.dfs(root.left, result) # 处理左子树
self.dfs(root.right, result) # 处理右子树
result.append(root.val) # 处理当前节点
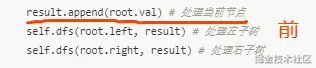
4、小结
递归版本的写法区别其实就是 处理根的位置不同
5、帕先生讲完了, 你看完了吗
下期会讲一下这三种遍历的非递归写法
