1. M-P 神经元:
1.1. 定义:
一个用于模拟生物行为的数学模型:接收 n 个输入,输入通常来自其他神经元,并给各个输入赋予权重计算加权和,然后根据自身特有的阈值进行比较(作减法),最后通过激活函数(模拟抑制和激活)处理得到输出(输给下一个神经元)。
y=f(i=1∑nwixi−θ)=f(wTx+b)
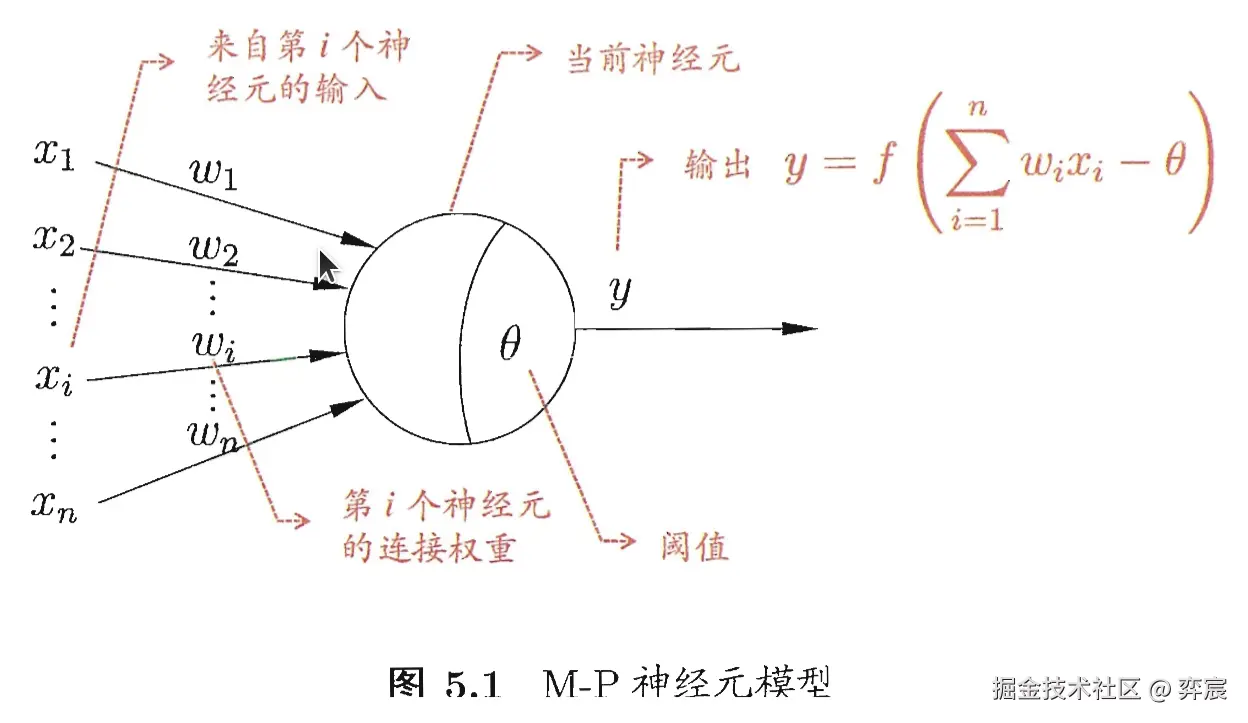 一些激活函数:在单个 M-P 神经元中,一般使用 sigimoid(对数几率回归)或者阶跃函数(感知机)作为激活函数。
一些激活函数:在单个 M-P 神经元中,一般使用 sigimoid(对数几率回归)或者阶跃函数(感知机)作为激活函数。
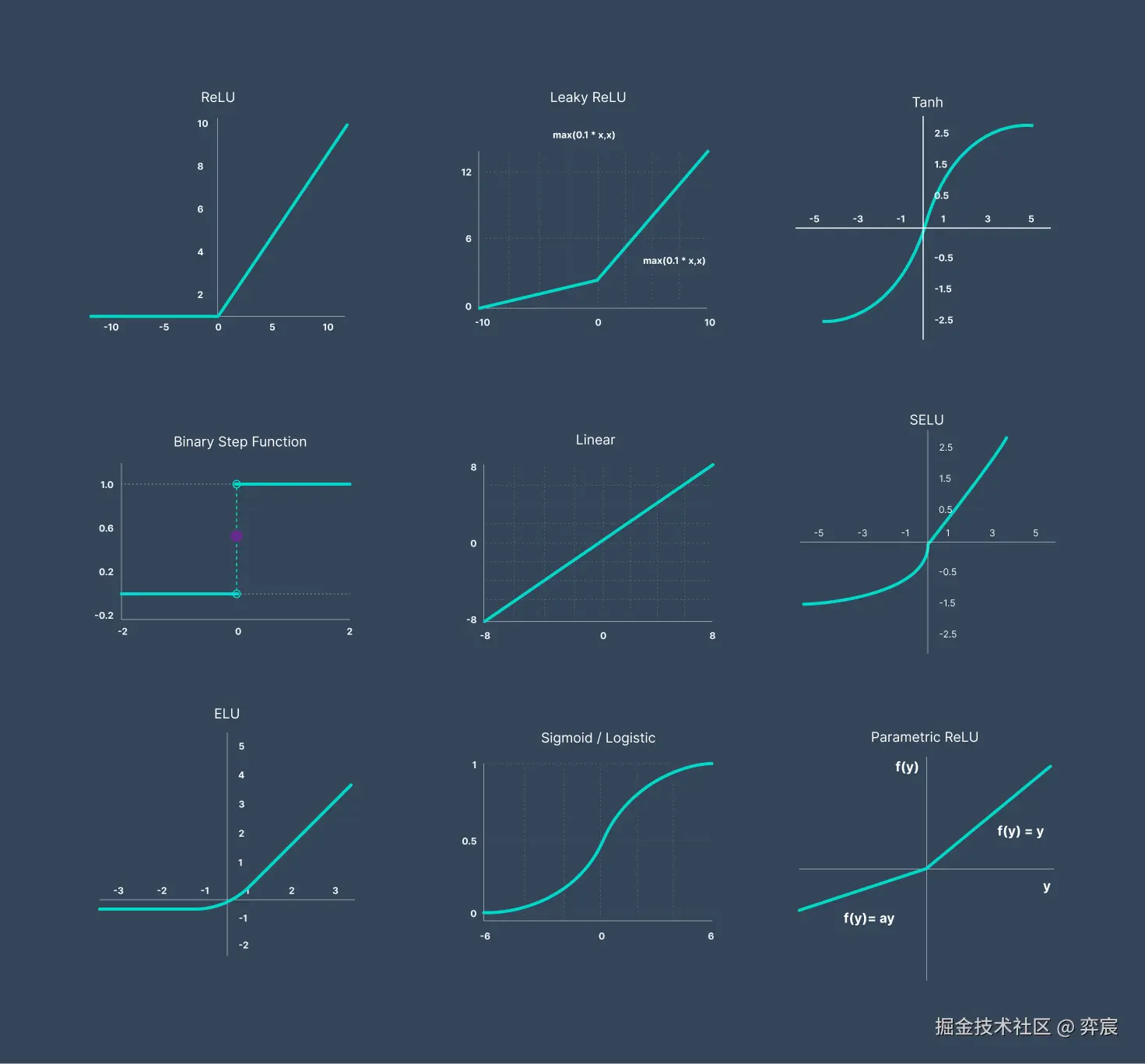

2. 感知机模型:
2.1. 基本定义:
感知机模型是一个分类模型,由两层神经元组成,输入层接收外界输入信号后传递给输出层,输出层是 M - P 神经元。
2.2. 激活函数:
阶跃函数:y=f(wTx+b)=sgn(wTx−θ)={1,0,wTx−θ⩾0wTx−θ<0
其中,x∈Rn 为样本的特征向量,是感知机模型的输入,w,θ 是感知机模型的参数,
w∈Rn 为权重,θ 为阈值。
2.3. 几何角度:
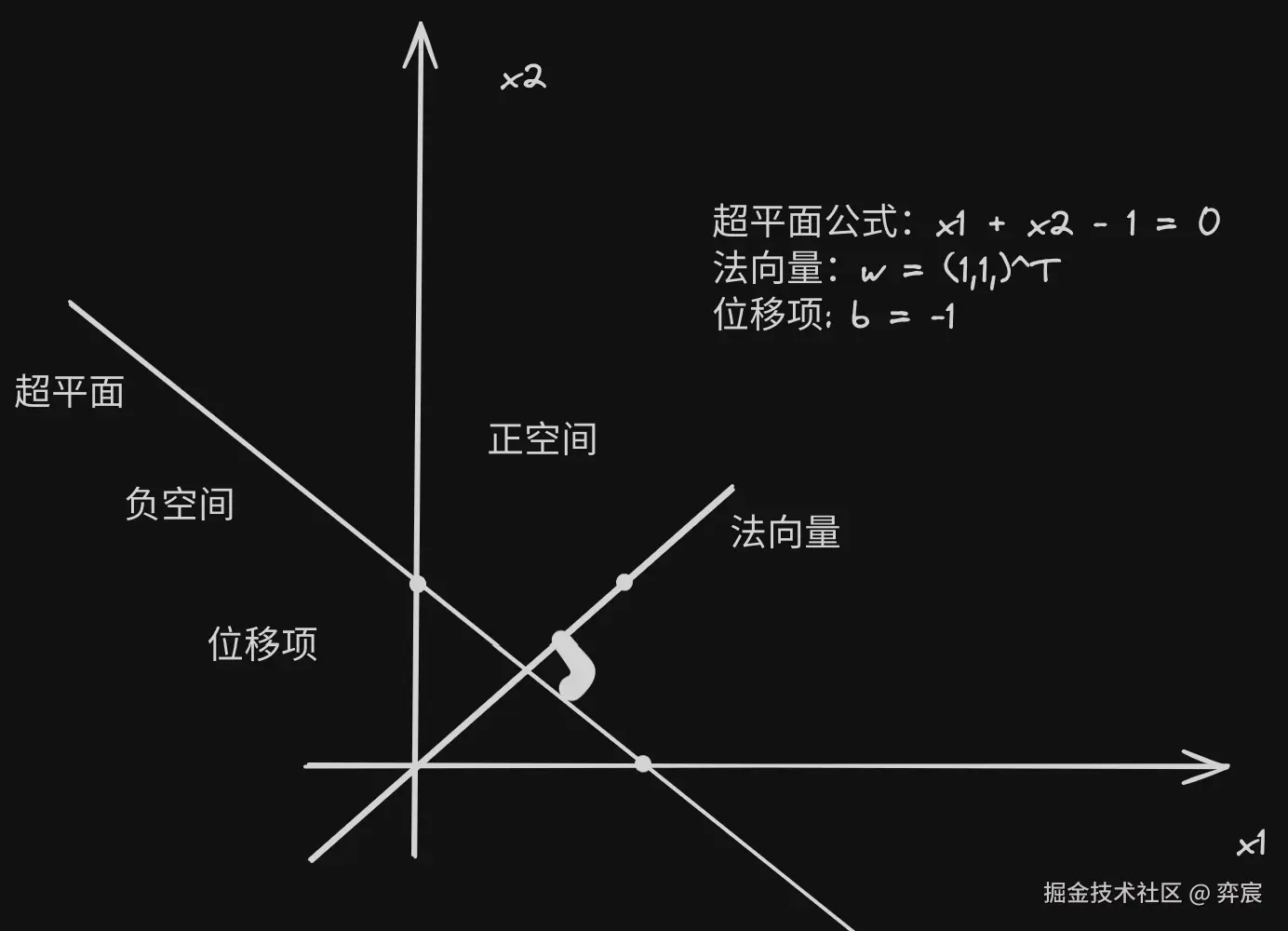
再从几何角度来说,给定一个线性可分的数据集 T,感知机的学习目标是求得能对数据集 T 中的正负样本完全正确划分的超平面,其中 wTx−θ 即为超平面方程。n 维空间的超平面(wTx+b=0,其中 w,x∈Rn) :
- 超平面方程不唯一(系数缩放倍数,值的变化)
- 法向量 w 垂直于超平面
- 法向量 w 和位移项 b 确定一个唯一超平面
- 法向量 w 指向的那一半空间为正空间,另一半为负空间
2.4. 感知机学习策略:
2.4.1. 基本介绍:
感知机学习策略:随机初始化 w,b,将全体训练样本代入模型找出误分类样本,假设此时误分类样本集合为 M⊆T,对任意一个误分类样本 (x,y)∈M 来说,当 wTx− θ⩾0 时,模型输出值为 y^=1,样本真实标记为 y=0;反之,当 wTx−θ<0 时,模型输出值为 y^=0,样本真实标记为 y=1。综合两种情形可知,以下公式恒成立
(y^−y)(wTx−θ)≥0
所以,给定数据集 T,其损失函数可以定义为:
L(w,θ)=∑x∈M(y^−y)(wTx−θ)
显然,此损失函数是非负的。如果没有误分类点,损失函数值是0。而且,误分类点离超平面越近,损失函数值就越小。学习目的就是最小化该损失函数,找到对应的 w 和 θ。
2.4.2. 具体操作:
具体地,给定总数据集
T={(x1,y1),(x2,y2),…,(xN,yN)}
其中 xi∈Rn,yi∈{0,1},求参数 w,θ,使其为极小化损失函数的解:
w,θminL(w,θ)=w,θminxi∈M∑(y^i−yi)(wTxi−θ)
其中 M⊆T 为误分类样本集合。若将阈值 θ 看作一个固定输入为-1 的“哑节点”,即目前是 n 维的空间,那么将 n 维扩充到 n+1 维,然后此时的第 n+1 维的权重为 wn+1 对应的 X 的向量为 xn+1=−1 则有公式:
−θ=−1⋅wn+1=xn+1⋅wn+1
根据该式,进行代入,可将要求解的极小化问题进一步简化,需要注意的是,此时的 w和x 是已经扩充了一个维度的向量,而并非是原来的向量:
wminL(w)=wminxi∈M∑(y^i−yi)wTxi
感知机学习算法:当误分类样本集合 M 固定时,那么可以求得损失函数 L(w) 的梯度为(关于 w 泰勒展开得到)
∇wL(w)=xi∈M∑(y^i−yi)xi
感知机的学习算法具体采用的是随机梯度下降法(随机选取部分或单个样本计算梯度),也就是极小化过程中不是一次使 M 中所有误分类点的梯度下降,而是一次随机选取一个误分类点使其梯度下降。所以权重 w 的更新公式为,其中 η 为学习率。
wi←wi+Δwi
Δwi=−η(y^i−yi)xi=η(yi−y^i)xi
相应地,w 中的某个分量 wi 的更新公式即为西瓜书公式(5.2),最终解出来的 w 通常不唯一(画个图即可解释)。
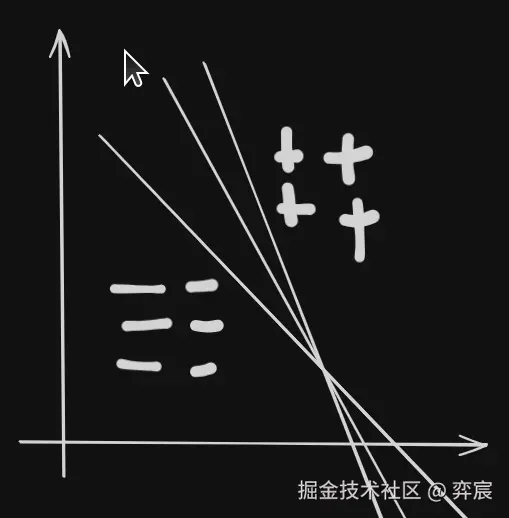
2.5. 感知机缺点:
神经元分类能力有限,只能分类线性可分的数据集,无法分类线性不可分的数据集,如西瓜书上的异或问题。
3. 神经网络:
3.1. 基本定义:
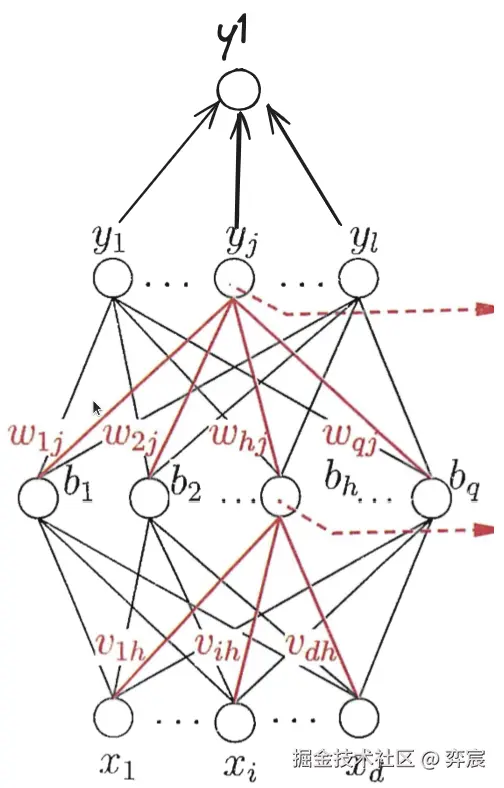
神经网络由多个神经元构成的网络结构。简化的两层感知机如图所示:
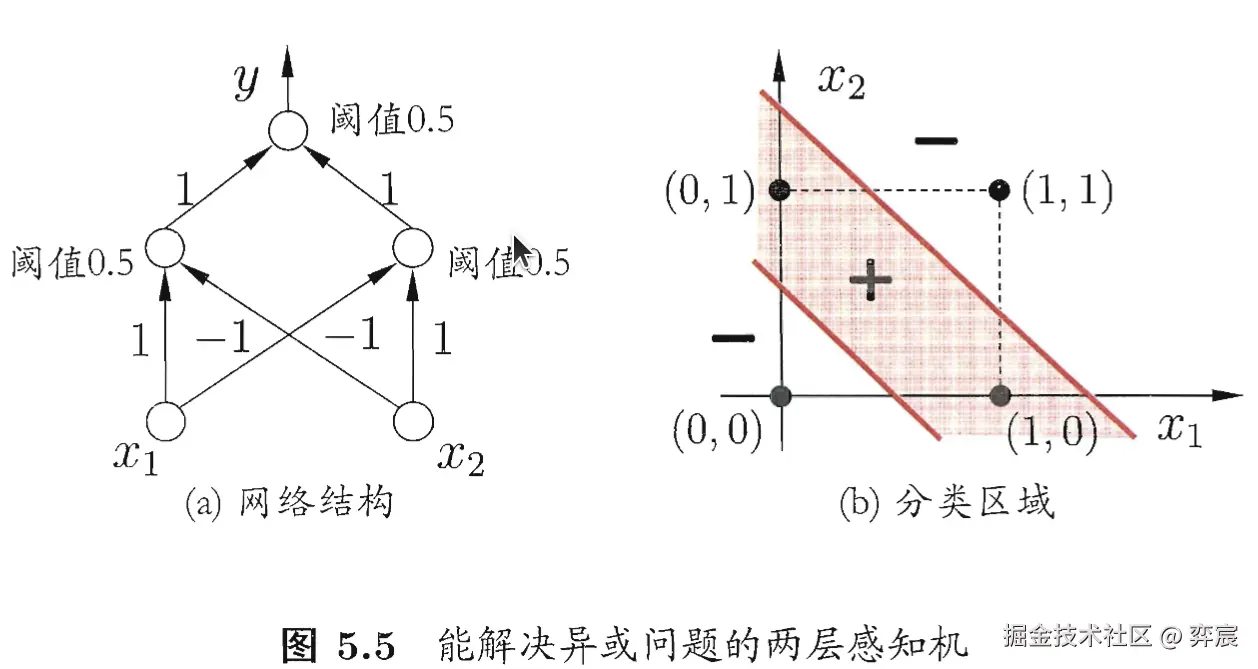 每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接.这样的神经网络结构通常称为“多层前馈神经网络" ,一般的神经网络包含输入层,隐含层和输出层,其基本结构如图所示:
每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接.这样的神经网络结构通常称为“多层前馈神经网络" ,一般的神经网络包含输入层,隐含层和输出层,其基本结构如图所示:
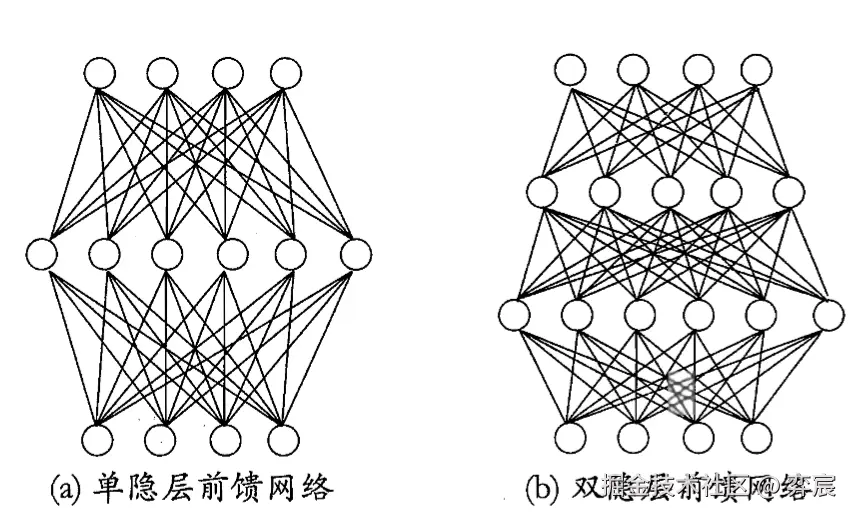 根据通用近似定理:只需要一个包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数。神经网络即能做回归,也能作分类。
根据通用近似定理:只需要一个包含足够多神经元的隐层,多层前馈网络就能以任意精度逼近任意复杂度的连续函数。神经网络即能做回归,也能作分类。
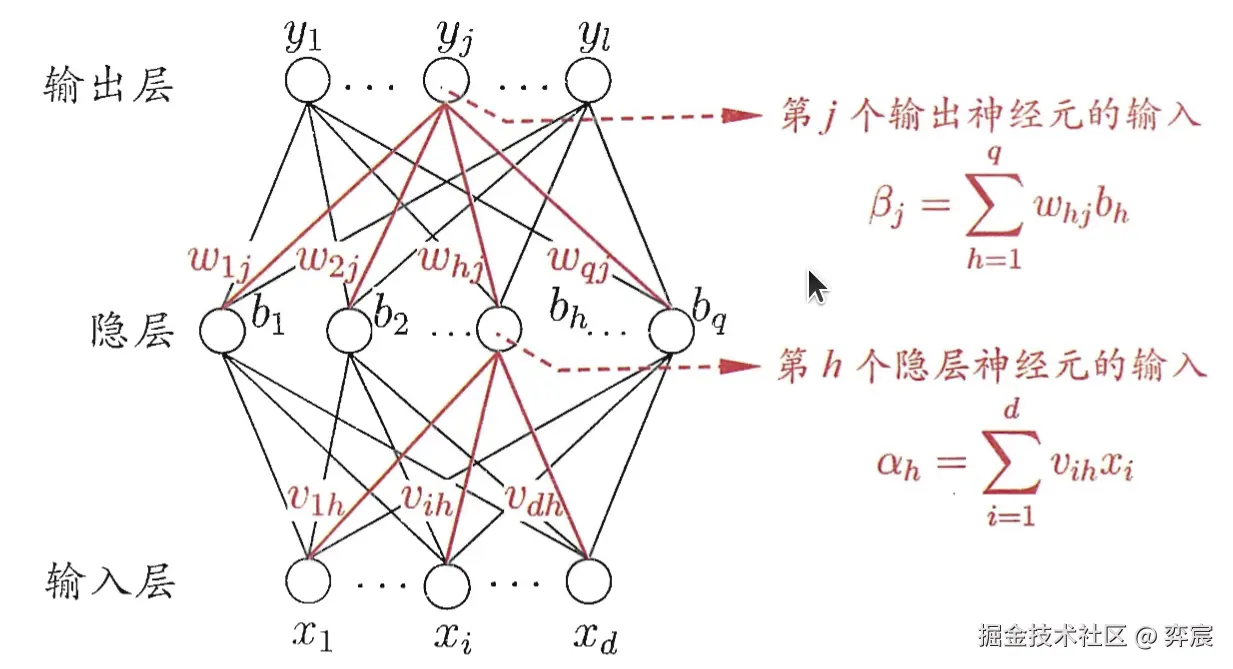
3.2. 多层前馈网络:
每层神经元与下一层神经元全互连,神经元之间不存在同层连接,也不存在跨层连接。 (隐层阈值 γh,输出层阈值 θj)
将神经网络(记为 NN)看作一个特征加工函数:x 是一个 d 维的特征向量,经由神经网络进行处理和加工输出 y,并且由 d 维转为了 l 维
x∈Rd→NN(x)→y=x∗∈Rl
单输出:输出的 y 只有一个值
- 回归:后面接一个 Rl→R (l 维)的神经元,例如:没有激活函数的神经元,损失函数一般使用均方误差来训练。
ynew=wTx∗+b
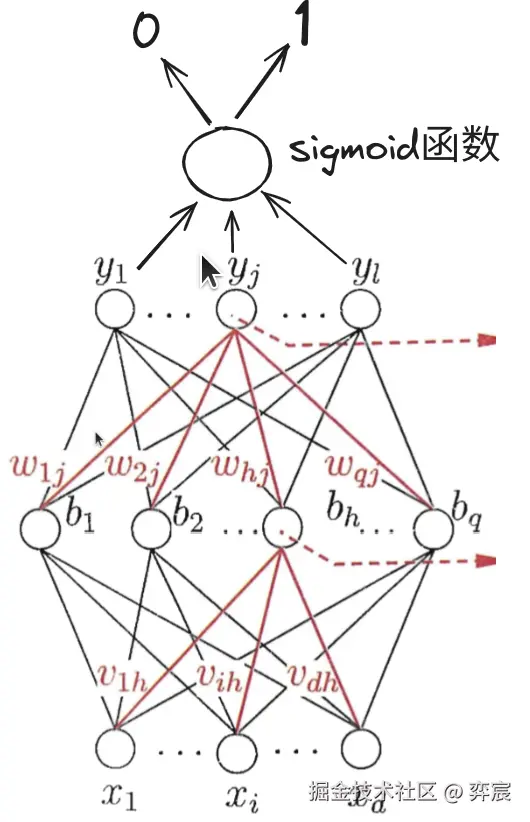
- 分类:后面接一个 Rl→[0,1] 的神经元,例如:激活函数为 sigmoid 函数的神经元,损失函数一般使用交叉熵进行训练。
y=1+e−(wTx∗+b)1
在模型训练过程中,神经网络(NN)自动学习提取有用的特征,因此,机器学习向“全自动数据分析”又前进了一步。
3.3. BP 推导:
假设多层前馈网络中的激活函数全为sigmoid函数,且当前要完成的任务为一个 (多输出)回归任务,因此损失函数可以采用均方误差(分类任务则用交叉熵)。对于某个训练样本 (xk,yk),其中 yk=(y1k,y2k,…,ylk),假定其多层前馈网络的输出为 y^k= (y^1k,y^2k,…,y^lk),则该单个样本的均方误差(损失)为
Ek=21j=1∑l(y^jk−yjk)2
误差逆传播算法 (BP 算法):基于 [[#2.4. 感知机学习策略:|随机梯度下降法]] 的参数更新算法
w←w+Δw
Δw=−η∇wE
其中 η 为学习率。只需推导出 ∇wE 这个损失函数 E 关于参数 w 的一阶偏导数(梯度)即可(链式求导,补充矩阵向量求导)。值得一提的是,由于NN (x) 通常是极其复杂的非凸函数,不具备像凸函数这种良好的数学性质,因此随机梯度下降不能保证一定能走到全局最小值点,更多情况下走到的都是局部极小值点。
下面以输入层第 i 个神经元与隐层第 h 个神经元之间的连接权为例推导一下:(隐层阈值 γh,输出层阈值 θj)。
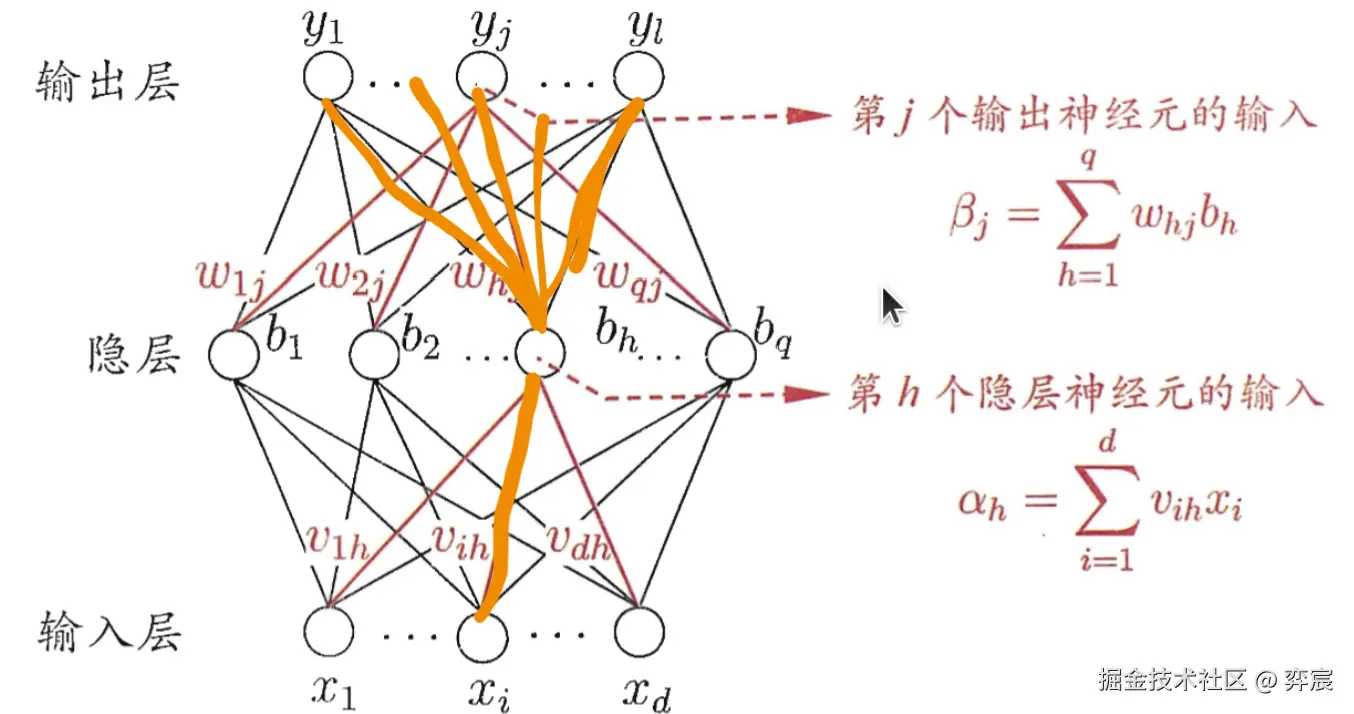
Ek=21j=1∑l(y^jk−yjk)2,Δvih=−η∂vih∂Ek∂vih∂Ek=j=1∑l∂y^jk∂Ek⋅∂βj∂y^jk⋅∂bh∂βj⋅∂αh∂bh⋅∂vih∂αh
由图和公式即可推导其梯度变化量,由于是全连接的,因此需要求该输出的所有的相关的神经元的输入输出和。
链式求导推理公式(南瓜书第五章相应部分),其中每一个分量的取值,从图中的公式以及神经元的公式即可推出:
注意,后三步与 sigmoid 函数的性质 处处可导,且导数计算公式有关系
gj=−∂y^jk∂Ek⋅∂βj∂y^jk=−(y^jk−yjk)f′(βj−θj)=y^jk(1−y^jk)(yjk−y^jk)∂vih∂Ek=j=1∑l∂y^jk∂Ek⋅∂βj∂y^jk⋅∂bh∂βj⋅∂αh∂bh⋅∂vih∂αh=j=1∑l∂y^jk∂Ek⋅∂βj∂y^jk⋅∂bh∂βj⋅∂αh∂bh⋅xi=j=1∑l∂y^jk∂Ek⋅∂βj∂y^jk⋅∂bh∂βj⋅f′(αh−γh)⋅xi=j=1∑l∂y^jk∂Ek⋅∂βj∂y^jk⋅whj⋅f′(αh−γh)⋅xi=j=1∑l(−gj)⋅whj⋅f′(αh−γh)⋅xi=−f′(αh−γh)⋅j=1∑lgj⋅whj⋅xi=−bh(1−bh)⋅j=1∑lgj⋅whj⋅xi=−eh⋅xi
eh=bh(1−bh)⋅j=1∑lgj⋅whj 

