

本文内容基于 Linux v5.4 源码
双向链表
核心文件:
include/linux/list.h
/*
* Simple doubly linked list implementation.
*
* Some of the internal functions ("__xxx") are useful when
* manipulating whole lists rather than single entries, as
* sometimes we already know the next/prev entries and we can
* generate better code by using them directly rather than
* using the generic single-entry routines.
*/
基本结构
// /include/linux/types.h
struct list_head {
struct list_head *next, *prev;
};
双链表的基础结构仅有两个指针,一个指向前一个节点,一个指向后一个节点。其保存数据的思路是将链表结构嵌入在实际的数据结构中,同时可以根据二者在内存分布中的位置关系,通过指针偏移来访问数据。
// /include/linux/list.h
/**
* list_entry - get the struct for this entry
* @ptr: the &struct list_head pointer.
* @type: the type of the struct this is embedded in.
* @member: the name of the list_head within the struct.
*/
#define list_entry(ptr, type, member) container_of(ptr, type, member)
// /include/linux/kernel.h
/**
* container_of - cast a member of a structure out to the containing structure
* @ptr: the pointer to the member.
* @type: the type of the container struct this is embedded in.
* @member: the name of the member within the struct.
*
*/
#define container_of(ptr, type, member) ({ \
void *__mptr = (void *)(ptr); \
BUILD_BUG_ON_MSG(!__same_type(*(ptr), ((type *)0)->member) && \
!__same_type(*(ptr), void), \
"pointer type mismatch in container_of()"); \
((type *)(__mptr - offsetof(type, member))); })
// /include/linux/compiler_types.h
/* Are two types/vars the same type (ignoring qualifiers)? */
#define __same_type(a, b) __builtin_types_compatible_p(typeof(a), typeof(b))
// /include/linux/stddef.h
#ifdef __compiler_offsetof
#define offsetof(TYPE, MEMBER) __compiler_offsetof(TYPE, MEMBER)
#else
#define offsetof(TYPE, MEMBER) ((size_t)&((TYPE *)0)->MEMBER)
#endif
访问的方法是通过 list_entry 宏来实现的,抛掉其内部的指针类型校验,可以简单的将宏展开结果等价于 (type *)((char *)(ptr) - (char *) &((type *)0)->member)。这里的基本思路就是假设0地址是type类型的起始地址,访问type->member的地址就是member在type中的偏移量(因为基地址是0,所以这里其实隐含了减去基地址的逻辑),即list_head在结构中的偏移,因此将真实的list_head地址减去偏移量,就能得到数据的真实起始地址。
常用接口
初始化很简单的通过宏将头尾指针都指向了自己
#define LIST_HEAD_INIT(name) { &(name), &(name) }
#define LIST_HEAD(name) \
struct list_head name = LIST_HEAD_INIT(name)
// 和LIST_HEAD_INIT功能一样,这里传递的是指针,而前面传递的是对象
static inline void INIT_LIST_HEAD(struct list_head *list)
{
WRITE_ONCE(list->next, list);
list->prev = list;
}
添加分为了添加在目标节点的尾部 list_add,或添加在目标节点的头部 list_add_tail,两者的实现都是 __list_add, 通过确认操作节点的prev、next,完成三者指针关系的改写。
/*
* Insert a new entry between two known consecutive entries.
*
* This is only for internal list manipulation where we know
* the prev/next entries already!
*/
static inline void __list_add(struct list_head *new,
struct list_head *prev,
struct list_head *next)
{
if (!__list_add_valid(new, prev, next))
return;
next->prev = new;
new->next = next;
new->prev = prev;
WRITE_ONCE(prev->next, new);
}
static inline void list_add(struct list_head *new, struct list_head *head)
{
__list_add(new, head, head->next);
}
static inline void list_add_tail(struct list_head *new, struct list_head *head)
{
__list_add(new, head->prev, head);
}
删除也很好理解,需要注意的是,LIST_POISON1 和 LIST_POISON2 是内部定义的两个非空指针。因为空指针可能导致程序崩溃,这里采用非空的预设指针来校验 entry 是否被正确的初始化。
static inline void __list_del(struct list_head * prev, struct list_head * next)
{
next->prev = prev;
WRITE_ONCE(prev->next, next);
}
static inline void __list_del_entry(struct list_head *entry)
{
if (!__list_del_entry_valid(entry))
return;
__list_del(entry->prev, entry->next);
}
static inline void list_del(struct list_head *entry)
{
__list_del_entry(entry);
entry->next = LIST_POISON1;
entry->prev = LIST_POISON2;
}
判空
static inline int list_empty(const struct list_head *head)
{
return READ_ONCE(head->next) == head;
}
遍历,需要注意的是,在内核的使用中,链表头是不会嵌入到具体的数据结构中的,这主要是出于通用、灵活、性能等方面的考虑,因此获取链表的头尾元素,需要额外的操作,当然其本质还是对list_entry的调用。
#define list_first_entry(ptr, type, member) \
list_entry((ptr)->next, type, member)
#define list_last_entry(ptr, type, member) \
list_entry((ptr)->prev, type, member)
#define list_for_each(pos, head) \
for (pos = (head)->next; pos != (head); pos = pos->next)
#define list_for_each_prev(pos, head) \
for (pos = (head)->prev; pos != (head); pos = pos->prev)
同时可以看到,这里的遍历其实就是for循环条件的等价替换,可以预见在循环的同时,进行节点的删除或修改,是不够安全的,可能导致循环的终止或访问到非预期的内存位置。
针对这种情况,内核实现也提供了安全的遍历接口,思路是提前保存当前节点的下一个节点,从而规避对当前节点修改时可能对尚未遍历的链表结构造成影响:
/**
* list_for_each_safe - iterate over a list safe against removal of list entry
* @pos: the &struct list_head to use as a loop cursor.
* @n: another &struct list_head to use as temporary storage
* @head: the head for your list.
*/
#define list_for_each_safe(pos, n, head) \
for (pos = (head)->next, n = pos->next; pos != (head); \
pos = n, n = pos->next)
#define list_for_each_prev_safe(pos, n, head) \
for (pos = (head)->prev, n = pos->prev; \
pos != (head); \
pos = n, n = pos->prev)
当然遍历也包括定位当前数据节点的相邻节点,这里也需要指出 list_head 在数据结构中的位置。
/**
* list_next_entry - get the next element in list
* @pos: the type * to cursor
* @member: the name of the list_head within the struct.
*/
#define list_next_entry(pos, member) \
list_entry((pos)->member.next, typeof(*(pos)), member)
#define list_prev_entry(pos, member) \
list_entry((pos)->member.prev, typeof(*(pos)), member)
哈希链表
/include/linux/list.h
基本结构
// /include/linux/types.h
struct hlist_head {
struct hlist_node *first;
};
struct hlist_node {
struct hlist_node *next, **pprev;
};
hlist_head 和 hlist_node 是内核哈希链表的头节点和数据节点,其结构如下图所示。hlist_head 在哈希桶中,仅包含一个指向链表的指针,数据节点则都分布在链表上,包含前驱和后继两个指针。
特别的是,数据节点 hlist_node 是一个二级指针,指向的是前一个节点的 next 指针。之所以这么做,是因为链表首个元素的前驱是 hlist_head,这种情况下,链表中的prev指针无法做到统一表达,因此需要用二级指针来屏蔽这种差异。
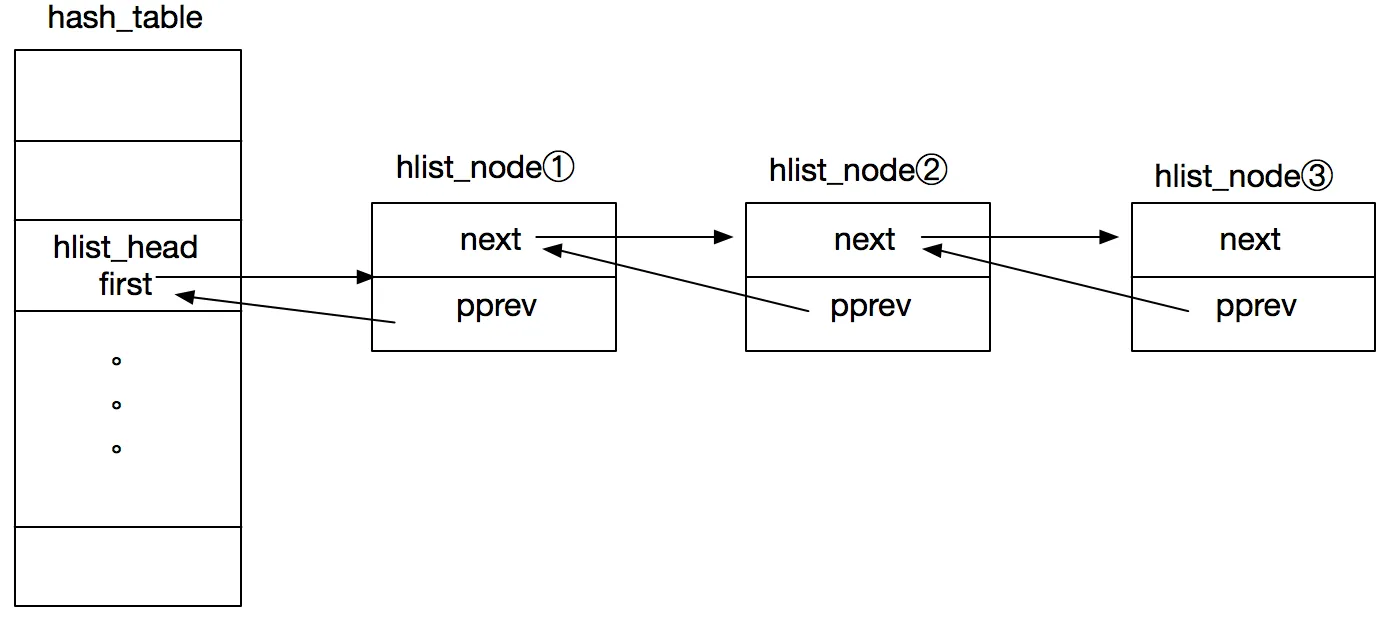
此外对哈希表节点的数据访问和双向链表的数据访问方式完全一致,通过 hlist_entry 宏即可实现:
#define hlist_entry(ptr, type, member) container_of(ptr,type,member)
常用接口
初始化,这里的注释也可以看到,hlist_head 设计为单指针主要是为了节约内存占用,缺陷就是无法通过一次访问找到链表尾结点。不过这个需求在哈希表中并不是很常用。
/*
* Double linked lists with a single pointer list head.
* Mostly useful for hash tables where the two pointer list head is
* too wasteful.
* You lose the ability to access the tail in O(1).
*/
#define HLIST_HEAD_INIT { .first = NULL }
#define HLIST_HEAD(name) struct hlist_head name = { .first = NULL }
#define INIT_HLIST_HEAD(ptr) ((ptr)->first = NULL)
static inline void INIT_HLIST_NODE(struct hlist_node *h)
{
h->next = NULL;
h->pprev = NULL;
}
添加提供了几种常用实现,添加到链表头、链表元素的前面、链表元素的后面。
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
WRITE_ONCE(h->first, n);
n->pprev = &h->first;
}
/* next must be != NULL */
static inline void hlist_add_before(struct hlist_node *n, struct hlist_node *next)
{
n->pprev = next->pprev;
n->next = next;
next->pprev = &n->next;
WRITE_ONCE(*(n->pprev), n);
}
static inline void hlist_add_behind(struct hlist_node *n, struct hlist_node *prev)
{
n->next = prev->next;
prev->next = n;
n->pprev = &prev->next;
if (n->next)
n->next->pprev = &n->next;
}
删除,把当前节点从链表中移除
static inline void __hlist_del(struct hlist_node *n)
{
struct hlist_node *next = n->next;
struct hlist_node **pprev = n->pprev;
WRITE_ONCE(*pprev, next);
if (next)
next->pprev = pprev;
}
static inline void hlist_del(struct hlist_node *n)
{
__hlist_del(n);
n->next = LIST_POISON1;
n->pprev = LIST_POISON2;
}
判空
static inline int hlist_empty(const struct hlist_head *h)
{
return !READ_ONCE(h->first);
}
遍历和双向链表工作原理一样,不过实现上要复杂一点,并且没有反向迭代的版本
/**
* hlist_for_each_entry - iterate over list of given type
* @pos: the type * to use as a loop cursor.
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry(pos, head, member) \
for (pos = hlist_entry_safe((head)->first, typeof(*(pos)), member); \
pos; \
pos = hlist_entry_safe((pos)->member.next, typeof(*(pos)), member))
/**
* hlist_for_each_entry_safe - iterate over list of given type safe against removal of list entry
* @pos: the type * to use as a loop cursor.
* @n: another &struct hlist_node to use as temporary storage
* @head: the head for your list.
* @member: the name of the hlist_node within the struct.
*/
#define hlist_for_each_entry_safe(pos, n, head, member) \
for (pos = hlist_entry_safe((head)->first, typeof(*pos), member); \
pos && ({ n = pos->member.next; 1; }); \
pos = hlist_entry_safe(n, typeof(*pos), member))
队列
核心文件 /include/linux/kfifo.h /lib/kfifo.c
A generic kernel FIFO implementation
基本结构
struct __kfifo {
unsigned int in;
unsigned int out;
unsigned int mask;
unsigned int esize;
void *data;
};
内核FIFO的实现非常高效,它使用一个环形数组来存储数据,并且使用两个指针来标记队列的入口和出口
in标记入队索引,入队n个数据时,in变量就+nout标记出队索引,出队k个数据时,out变量就+kout不允许大于in(out等于in时表示fifo为空)in不允许比out大超过fifo空间in、out都会保持增长,不会轻易从零重新计算- 如果需要获取位置,则
in、out会按位与mask,mask的大小是size - 1,同时会要求FIFO的大小必须是2的幂次,保证了获取位置的效率
#define __STRUCT_KFIFO_COMMON(datatype, recsize, ptrtype) \
union { \
struct __kfifo kfifo; \
datatype *type; \
const datatype *const_type; \
char (*rectype)[recsize]; \
ptrtype *ptr; \
ptrtype const *ptr_const; \
}
#define __STRUCT_KFIFO(type, size, recsize, ptrtype) \
{ \
__STRUCT_KFIFO_COMMON(type, recsize, ptrtype); \
type buf[((size < 2) || (size & (size - 1))) ? -1 : size]; \
}
#define STRUCT_KFIFO(type, size) \
struct __STRUCT_KFIFO(type, size, 0, type)
/**
* DECLARE_KFIFO - macro to declare a fifo object
* @fifo: name of the declared fifo
* @type: type of the fifo elements
* @size: the number of elements in the fifo, this must be a power of 2
*/
#define DECLARE_KFIFO(fifo, type, size) STRUCT_KFIFO(type, size) fifo
#define __STRUCT_KFIFO_PTR(type, recsize, ptrtype) \
{ \
__STRUCT_KFIFO_COMMON(type, recsize, ptrtype); \
type buf[0]; \
}
#define STRUCT_KFIFO_PTR(type) \
struct __STRUCT_KFIFO_PTR(type, 0, type)
/**
* DECLARE_KFIFO_PTR - macro to declare a fifo pointer object
* @fifo: name of the declared fifo
* @type: type of the fifo elements
*/
#define DECLARE_KFIFO_PTR(fifo, type) STRUCT_KFIFO_PTR(type) fifo
宏定义提供了两种方式来声明一个FIFO结构,分别是静态的 STRUCT_KFIFO 和 动态的 STRUCT_KFIFO_PTR。
以 STRUCT_KFIFO 为例,假设我们定义一个存储int型数据的FIFO,大小为16,则最终的展开结果是:
// STRUCT_KFIFO(my_fifo, int, 16)
// |
// STRUCT_KFIFO(int, 16) my_fifo
// |
// struct __STRUCT_KFIFO(int, 16, 0, int) my_fifo
// |
// struct {
// __STRUCT_KFIFO_COMMON(int, 0, int);
// int buf[((16 < 2) || (16 & (16 - 1))) ? -1 : 16];
// } my_fifo
struct {
union {
struct __kfifo kfifo;
int *type;
const int *const_type;
int (*rectype)[0];
int *ptr;
int const *ptr_const;
};
int buf[16];
} my_fifo;
上述展开结果中,存在通过 __STRUCT_KFIFO_COMMON 展开的一个 union,为什么这么设计呢?因为 __kfifo 中并不包含元素数据类型,元素指针类型,那如何确定这些类型呢?这些类型实质上是保存在了 union 的声明中,比如可以通过 typeof(*my_fifo->type) 来获取到 my_fifo 的数据类型是 int 类型。同时这些额外的声明(type、const_typ,etc)放在union内,也不会占用 my_fifo 的运行期开销。
动态的声明,唯一的区别就是不会立即指定buf大小,而是用一个不定长数组 buf[0] 来表示。
随之而来的问题是如果给出了一个 FIFO 的变量名,如何确定是通过哪一种方式声明的呢?内核也提供了判断方法,其判断是根据FIFO的数据是否和其结构存放在一起:
/*
* helper macro to distinguish between real in place fifo where the fifo
* array is a part of the structure and the fifo type where the array is
* outside of the fifo structure.
*/
#define __is_kfifo_ptr(fifo) \
(sizeof(*fifo) == sizeof(STRUCT_KFIFO_PTR(typeof(*(fifo)->type))))
初始化
对于静态的FIFO,其初始化动作不涉及内存分配,仅更新了 __kfifo 的成员变量。 注意mask的大小是 size - 1,并将data指向了union外部的buf,这样就在 __kfifo 一个结构内实现了对 FIFO的管理。
/**
* INIT_KFIFO - Initialize a fifo declared by DECLARE_KFIFO
* @fifo: name of the declared fifo datatype
*/
#define INIT_KFIFO(fifo) \
(void)({ \
typeof(&(fifo)) __tmp = &(fifo); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
__kfifo->in = 0; \
__kfifo->out = 0; \
__kfifo->mask = __is_kfifo_ptr(__tmp) ? 0 : ARRAY_SIZE(__tmp->buf) - 1; \
__kfifo->esize = sizeof(*__tmp->buf); \
__kfifo->data = __is_kfifo_ptr(__tmp) ? NULL : __tmp->buf; \
})
此外,内核还提供了 #define DEFINE_KFIFO(fifo, type, size),能够在一句代码中完成对 FIFO 的声明和定义。
对于动态的FIFO,则需要在初始化时,分配buf空间,并将buf指针赋值给__kfifo的data成员变量。
内核在这里采用了一个校验参数是否为指针类型的技巧,即 typeof((fifo) + 1)。如果传入的是普通结构体,表达式将会引发编译器错误,因为结构体与一个整数一起使用一元加号是不允许的。如果传入的是指针,那么二元加号将会对其加1,结果仍然是同一类型的指针,并且表达式在语法上是正确的。
实际的内存分配发生在kmalloc_array,定义在/include/linux/slab.h,其实际分配了一串连续的内存作为一个array,其入参分别是:元素个数、元素大小、给分配器的标志位
/**
* kfifo_alloc - dynamically allocates a new fifo buffer
* @fifo: pointer to the fifo
* @size: the number of elements in the fifo, this must be a power of 2
* @gfp_mask: get_free_pages mask, passed to kmalloc()
*
* This macro dynamically allocates a new fifo buffer.
*
* The number of elements will be rounded-up to a power of 2.
* The fifo will be release with kfifo_free().
* Return 0 if no error, otherwise an error code.
*/
#define kfifo_alloc(fifo, size, gfp_mask) \
__kfifo_int_must_check_helper( \
({ \
typeof((fifo) + 1) __tmp = (fifo); \
struct __kfifo *__kfifo = &__tmp->kfifo; \
__is_kfifo_ptr(__tmp) ? \
__kfifo_alloc(__kfifo, size, sizeof(*__tmp->type), gfp_mask) : \
-EINVAL; \
}) \
)
// /lib/kfifo.c
int __kfifo_alloc(struct __kfifo *fifo, unsigned int size,
size_t esize, gfp_t gfp_mask)
{
/*
* round up to the next power of 2, since our 'let the indices
* wrap' technique works only in this case.
*/
size = roundup_pow_of_two(size);
fifo->in = 0;
fifo->out = 0;
fifo->esize = esize;
if (size < 2) {
fifo->data = NULL;
fifo->mask = 0;
return -EINVAL;
}
fifo->data = kmalloc_array(esize, size, gfp_mask);
if (!fifo->data) {
fifo->mask = 0;
return -ENOMEM;
}
fifo->mask = size - 1;
return 0;
}
EXPORT_SYMBOL(__kfifo_alloc);
入队
入队是通过copy的方式完整数据的转移的
static void kfifo_copy_in(struct __kfifo *fifo, const void *src,
unsigned int len, unsigned int off)
{
unsigned int size = fifo->mask + 1;
unsigned int esize = fifo->esize;
unsigned int l;
off &= fifo->mask;
// 可以认为off、size、len都是归一化的,因此当element_size != 1时,需要round up到其真实大小
if (esize != 1) {
off *= esize;
size *= esize;
len *= esize;
}
// 这里体现了FIFO是循环的,当尾部空余不足以放下数据的时候,会对数据进行切分,分别拷贝在尾部和头部
l = min(len, size - off);
memcpy(fifo->data + off, src, l);
memcpy(fifo->data, src + l, len - l);
/*
* make sure that the data in the fifo is up to date before
* incrementing the fifo->in index counter
*/
smp_wmb();
}
unsigned int __kfifo_in(struct __kfifo *fifo,
const void *buf, unsigned int len)
{
unsigned int l;
// 校验FIFO的可用空间是否足够,不足的情况下,会通过改写len对数据进行截断
l = kfifo_unused(fifo);
if (len > l)
len = l;
kfifo_copy_in(fifo, buf, len, fifo->in);
// 完成拷贝之后,再更新指针位置,通过上述smp_wmb保证了数据的可见性
fifo->in += len;
return len;
}
EXPORT_SYMBOL(__kfifo_in);
出队
出队提供了两种场景语义:peek,pop,peek不修改fifo的状态。此外出队的具体逻辑基本就是入队的镜像操作。
static void kfifo_copy_out(struct __kfifo *fifo, void *dst,
unsigned int len, unsigned int off)
{
unsigned int size = fifo->mask + 1;
unsigned int esize = fifo->esize;
unsigned int l;
off &= fifo->mask;
if (esize != 1) {
off *= esize;
size *= esize;
len *= esize;
}
l = min(len, size - off);
memcpy(dst, fifo->data + off, l);
memcpy(dst + l, fifo->data, len - l);
/*
* make sure that the data is copied before
* incrementing the fifo->out index counter
*/
smp_wmb();
}
unsigned int __kfifo_out_peek(struct __kfifo *fifo,
void *buf, unsigned int len)
{
unsigned int l;
l = fifo->in - fifo->out;
if (len > l)
len = l;
kfifo_copy_out(fifo, buf, len, fifo->out);
return len;
}
EXPORT_SYMBOL(__kfifo_out_peek);
unsigned int __kfifo_out(struct __kfifo *fifo,
void *buf, unsigned int len)
{
len = __kfifo_out_peek(fifo, buf, len);
fifo->out += len;
return len;
}
EXPORT_SYMBOL(__kfifo_out);
映射表IDR
/include/linux/idr.h/lib/idr.c
在源码的文件注释中,是这么解释idr的:Small id to pointer translation service avoiding fixed sized tables.
简单来说,struct idr 是在 Linux 内核中定义的一种数据结构,用于实现 ID 到指针的映射。这种映射机制允许内核将整数值(ID)与内存地址(指针)相关联,便于通过 ID 快速访问和管理内核中的资源。struct idr 通常用于管理如进程 ID、文件描述符 ID、IPC(进程间通信)ID 等系统资源。
struct idr 的实现通常基于基数树(radix tree)或者类基数树的结构,这种数据结构提供了高效的查找、插入和删除操作。
每个 IDR 都包含一个radix tree树,内核在初始化完 IDR 之后,每当 需要分配新的 ID 与指针绑定的时候,IDR 通过计算 idr_base + idr_next 的值计算下一 个 ID 的值,并且从radix tree中找到 ID 对应的slot供存储指针。由于 ID 申请 是连续的,因此从 radix tree 来看,树都是往一侧偏移退化形成一个稀疏数组。
基本结构
struct idr {
struct radix_tree_root idr_rt; // 基数树的根节点,用于存储 ID 到指针的映射
unsigned int idr_base; // IDR的基地址,表示分配ID的起始值
unsigned int idr_next; // 用于循环分配的下一个ID的位置
};
可以看到radix tree是基于xarray实现的,我们会在后面的章节分析xarray的实现细节。
// /include/linux/radix-tree.h
/* Keep unconverted code working */
#define radix_tree_root xarray
#define radix_tree_node xa_node
基本使用流程
#include <linux/idr.h>
// 使用 `DEFINE_IDR` 宏定义一个静态分配的 IDR 实例,或者使用 `idr_init` 函数初始化一个动态分配的 IDR 实例。
DEFINE_IDR(my_idr);
// 或者
struct idr *my_idr;
my_idr = kmalloc(sizeof(*my_idr), GFP_KERNEL);
idr_init(my_idr);
// 如果需要,可以预加载内存以优化 IDR 的性能,为当前 CPU 的 radix_tree_node 缓冲区加载足够的对象(节点),以确保在树中添加单个元素时不会失败。如果函数成功执行,即成功预加载了所需的基数树节点,它将返回 0。此外,在返回时,会保持对内核抢占的禁用状态。这意味着一旦函数成功执行完毕,调用者需要负责重新启用抢占。
idr_preload(GFP_KERNEL);
// 使用 `idr_alloc` 或 `idr_alloc_cyclic` 函数分配一个唯一的 ID 并将它与一个指针关联。
int id;
void *ptr = kmalloc(sizeof(*ptr), GFP_KERNEL); // 分配内存给指针
id = idr_alloc(my_idr, ptr, 0, 0, GFP_KERNEL);
// 使用 `idr_find` 函数通过 ID 来查找对应的指针。
void *found_ptr = idr_find(my_idr, id);
// 如果需要遍历 IDR,可以使用 `idr_get_next` 函数来获取序列中的下一个 ID。
int next_id;
void *next_ptr = idr_get_next(my_idr, &next_id);
// 使用 `idr_for_each` 或 `idr_for_each_entry` 宏来遍历 IDR 中的所有条目。
idr_for_each(my_idr, my_callback, NULL);
// 如果需要更新指针,可以使用 `idr_replace` 函数来替换特定 ID 的指针。
void *new_ptr = kmalloc(sizeof(*new_ptr), GFP_KERNEL);
idr_replace(my_idr, new_ptr, id);
// 使用 `idr_remove` 函数从 IDR 中移除一个 ID 及其关联的指针。
idr_remove(my_idr, id);
// 使用 `idr_is_empty` 函数检查 IDR 是否没有任何分配的 ID。
bool empty = idr_is_empty(my_idr);
// 当 IDR 不再需要时,使用 `idr_destroy` 函数来销毁 IDR 并释放相关资源。
idr_destroy(my_idr);
// 如果是动态分配的 IDR 实例,还需要释放内存
kfree(my_idr);
// 如果在分配ID之前使用了 `idr_preload`,使用完毕后需要调用 `idr_preload_end` 来结束预加载。
idr_preload_end();
初始化和销毁
静态初始化通过如下宏展开实现,完成了radix tree的初始化,并把两个id都初始化为零
#define IDR_INIT_BASE(name, base) { \
.idr_rt = RADIX_TREE_INIT(name, IDR_RT_MARKER), \
.idr_base = (base), \
.idr_next = 0, \
}
#define IDR_INIT(name) IDR_INIT_BASE(name, 0)
#define DEFINE_IDR(name) struct idr name = IDR_INIT(name)
动态初始化如下,除了idr是动态分配,需要传入指针之外,还允许我们传入初始id的值。
static inline void idr_init_base(struct idr *idr, int base)
{
INIT_RADIX_TREE(&idr->idr_rt, IDR_RT_MARKER);
idr->idr_base = base;
idr->idr_next = 0;
}
/**
* idr_init() - Initialise an IDR.
* @idr: IDR handle.
*
* Initialise a dynamically allocated IDR. To initialise a
* statically allocated IDR, use DEFINE_IDR().
*/
static inline void idr_init(struct idr *idr)
{
idr_init_base(idr, 0);
}
内核提供了 idr_remove 删除id并释放相关数据 idr_destroy 释放所有的id映射和层
/**
* idr_remove() - Remove an ID from the IDR.
* @idr: IDR handle.
* @id: Pointer ID.
*
* Removes this ID from the IDR. If the ID was not previously in the IDR,
* this function returns %NULL.
*
* Since this function modifies the IDR, the caller should provide their
* own locking to ensure that concurrent modification of the same IDR is
* not possible.
*
* Return: The pointer formerly associated with this ID.
*/
void *idr_remove(struct idr *idr, unsigned long id)
{
return radix_tree_delete_item(&idr->idr_rt, id - idr->idr_base, NULL);
}
EXPORT_SYMBOL_GPL(idr_remove);
// /lib/radix-tree.c
/**
* idr_destroy - release all internal memory from an IDR
* @idr: idr handle
*
* After this function is called, the IDR is empty, and may be reused or
* the data structure containing it may be freed.
*
* A typical clean-up sequence for objects stored in an idr tree will use
* idr_for_each() to free all objects, if necessary, then idr_destroy() to
* free the memory used to keep track of those objects.
*/
void idr_destroy(struct idr *idr)
{
struct radix_tree_node *node = rcu_dereference_raw(idr->idr_rt.xa_head);
if (radix_tree_is_internal_node(node))
radix_tree_free_nodes(node);
idr->idr_rt.xa_head = NULL;
root_tag_set(&idr->idr_rt, IDR_FREE);
}
EXPORT_SYMBOL(idr_destroy);
插入
循环地分配一个ID,并关联到某一个具体的资源指针。函数本身是不带锁的,需要调用者保证互斥访问。
循环是指:在查找可用ID的时候,会从上一个被分配的ID开始,向end增长查找,如果到end还没有找到的话,则会绕回到start继续寻找。
/**
* idr_alloc_cyclic() - Allocate an ID cyclically.
* @idr: IDR handle.
* @ptr: Pointer to be associated with the new ID.
* @start: The minimum ID (inclusive).
* @end: The maximum ID (exclusive).
* @gfp: Memory allocation flags.
*
* Allocates an unused ID in the range specified by @nextid and @end. If
* @end is <= 0, it is treated as one larger than %INT_MAX. This allows
* callers to use @start + N as @end as long as N is within integer range.
* The search for an unused ID will start at the last ID allocated and will
* wrap around to @start if no free IDs are found before reaching @end.
*
* The caller should provide their own locking to ensure that two
* concurrent modifications to the IDR are not possible. Read-only
* accesses to the IDR may be done under the RCU read lock or may
* exclude simultaneous writers.
*
* Return: The newly allocated ID, -ENOMEM if memory allocation failed,
* or -ENOSPC if no free IDs could be found.
*/
int idr_alloc_cyclic(struct idr *idr, void *ptr, int start, int end, gfp_t gfp)
{
u32 id = idr->idr_next;
int err, max = end > 0 ? end - 1 : INT_MAX;
if ((int)id < start)
id = start;
err = idr_alloc_u32(idr, ptr, &id, max, gfp);
if ((err == -ENOSPC) && (id > start)) {
id = start;
err = idr_alloc_u32(idr, ptr, &id, max, gfp);
}
if (err)
return err;
idr->idr_next = id + 1;
return id;
}
EXPORT_SYMBOL(idr_alloc_cyclic);
相对应的还有一个非循环的分配函数,在分配失败的时候返回-ENOSPC。
int idr_alloc(struct idr *idr, void *ptr, int start, int end, gfp_t gfp)
具体的是idr_alloc_u32,在这里会调用radix_tree来获取
int idr_alloc_u32(struct idr *idr, void *ptr, u32 *nextid,
unsigned long max, gfp_t gfp)
{
struct radix_tree_iter iter;
void __rcu **slot;
unsigned int base = idr->idr_base;
unsigned int id = *nextid;
if (WARN_ON_ONCE(!(idr->idr_rt.xa_flags & ROOT_IS_IDR)))
idr->idr_rt.xa_flags |= IDR_RT_MARKER;
id = (id < base) ? 0 : id - base;
radix_tree_iter_init(&iter, id);
slot = idr_get_free(&idr->idr_rt, &iter, gfp, max - base);
if (IS_ERR(slot))
return PTR_ERR(slot);
*nextid = iter.index + base;
/* there is a memory barrier inside radix_tree_iter_replace() */
radix_tree_iter_replace(&idr->idr_rt, &iter, slot, ptr);
radix_tree_iter_tag_clear(&idr->idr_rt, &iter, IDR_FREE);
return 0;
}
EXPORT_SYMBOL_GPL(idr_alloc_u32);
查询
idr_find()函数用于通过 ID 查找与之绑定的指针。函数直接通过radix_tree_lookup()函数在radix tree 中查找指定的节点,如果找到则返回 ID 绑定的指针;反之返回NULL。
/**
* idr_find() - Return pointer for given ID.
* @idr: IDR handle.
* @id: Pointer ID.
*
* Looks up the pointer associated with this ID. A %NULL pointer may
* indicate that @id is not allocated or that the %NULL pointer was
* associated with this ID.
*
* This function can be called under rcu_read_lock(), given that the leaf
* pointers lifetimes are correctly managed.
*
* Return: The pointer associated with this ID.
*/
void *idr_find(const struct idr *idr, unsigned long id)
{
return radix_tree_lookup(&idr->idr_rt, id - idr->idr_base);
}
EXPORT_SYMBOL_GPL(idr_find);
遍历
提供了两种遍历方式。两者的本质是类似的,核心都是通过radix_tree_for_each_slot来执行遍历,只是两种不同的写法。
#define idr_for_each_entry(idr, entry, id) \
for (id = 0; ((entry) = idr_get_next(idr, &(id))) != NULL; ++id)
// Iterate through all stored pointers.
int idr_for_each(const struct idr *idr,
int (*fn)(int id, void *p, void *data), void *data);
针对
radix tree及其他数据结构,会在后续文章"从源码学习Linux中的数据结构(二)"继续学习。
