

Redis数据结构—HyperLogLog
一、简单介绍
HyperLogLog是一种用于大规模数据集计数的概率性统计结构,可以统计集合中不同元素的数量,该数据结构有一下特点:
- 内存占用极少,统计上亿甚至几十亿的数量级只需要12KB的内存占用。
- 计算复杂度低,插入、查询操作的复杂复杂度都是O(1)。
- 支持多个数据集的并集:可以将多个集合进行去重合并,并且复杂度是O(1)。
- 结果是估计值,但误差非常小。
二、 应用场景
网站当日访问的去重复IP数量,或者访问某个短视频的用户总数,就是所谓的“唯一元素的计数”。在数学集合论中,基数表示集合中包含唯一元素的个数。
通常,这种技术需要记录截止当前遇到所有的唯一元素,以便在下一个元素到来时,判断是否已经被计数过,仅该元素以前从未出现过才增加计数器。在元素数量大到一定程度之后(比如短视频APP有1亿活跃用户,1亿条视频播放,要实时统计每条视频的UV),无论使用哈希表、搜索树、位图,存储占用消耗都会大到不能接受。
有一类随机算法可以使用估算集合的基数,只使用少量且固定的存储空间,并且插入和统计的算法复杂度都是O(1)。HyperLogLog 算法就非常出色,使用非常少量的内存,同时可以很好地估算基数。HyperLogLog 之所以叫 HyperLogLog,是因为它在 LogLog 算法基础上做的改进,而之前还有Linear Counting算法。
Redis的HyperLogLog仅使用12KB+16B进行计数,标准误差为0.81%,并且可以计数的上限达到了2^64。HyperLogLog 由 Philippe Flajolet 在 原始论文《HyperLogLog: the analysis of a near-optimal cardinality estimation algorithm》 中提出。Redis 中对 HLL 的三个 PFADD/PFCOUNT/PFMERGE,都是以 PF 开头,就是纪念 2011 年已经去世的 Philippe Flajolet 。
2013 年 Google 的 一篇论文《HyperLogLog in Practice: Algorithmic Engineering of a State of The Art Cardinality Estimation Algorithm》 深入介绍了其实际实现和变体。
三、实现原理
先来考虑一个这样的场景:要求你花一段时间来抛硬币,并记录连续抛硬币中连续正面最多的次数,我会用它来猜测你抛硬币的总次数。直观地讲,如果你花了一段时间抛硬币若干次,而你看到的最长连续正面次数是 3,我可以猜到你抛硬币的总次数一定不多。而如果你告诉我你看到了连续 100 个正面朝上,我猜你已经抛硬币很长很长时间了。
当然,你可能很幸运,会在从一开始就连续抛出了 10 次正面,然后停止抛硬币(这是个小概率事件,但是确实可能发生)。那根据这“连续抛出10次正面”的描述,我将会提供一个错的离谱的抛硬币总数的估计值。
所以,可以改进一下这个实验,我会给你10个硬币和和10张纸,你需要轮换着来抛这10枚硬币,每张纸记录每个硬币连续正面最多的次数。这样可以观察到更多的数据,我再评估就会更准确。
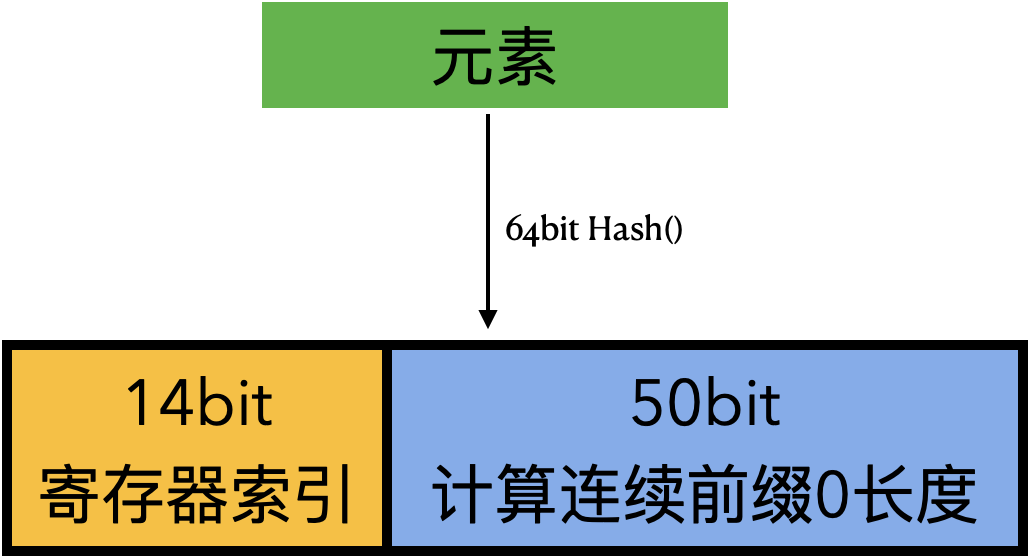
HyperLogLog 的原理类似:它对要加入的每个新元素进行 Hash 处理。Hash 的一部分用于索引寄存器(对应前面前面的示例中的某对【硬币+纸对】,作用是将原始集合分成 m 个子集);另一部分用于计算哈希中最长的前导零序列(对应前面硬币连续正面的最大次数)。
HyperLogLog 根据寄存器数组中的值(这些寄存器被设置为迄今为止针对给定子集观察到的最大连续零),计算出估计的基数,并应用修正公式来纠正估计误差, 能够提供非常好的近似基数。
Redis 中,HyperLogLog 使用 64bit 的 Hash 函数,14bit 用于寄存器索引,剩下的 50bit 用于计算前导 0 的个数。具体地,Redis 中 HLL 有 16384(2^14)个寄存器,其中存的值的范围是 0 ~ 50(实际是0~51,在Redis实现 HLL的文章中有介绍)。我们使用 6bit 就可以存储下 0~50 的所有值,所以需要的存储空间是 16384 * 6bit / (8bit/Byte) = 12288 Byte 也就是开头说的 12KB。
实际上 Redis 中对 HyperLogLog 的存储也是个 字符串,只不过这个字符串有个固定格式的头部(16字节)。
struct hllhdr {
char magic[4]; /* "HYLL" */
uint8_t encoding; /* HLL_DENSE or HLL_SPARSE. */
uint8_t notused[3]; /* Reserved for future use, must be zero. */
uint8_t card[8]; /* Cached cardinality, little endian. */
uint8_t registers[]; /* Data bytes. */
};
HyperLogLog 的标准误差为 1.04/sqrt(m),其中 m 是使用的寄存器数量,因此 Redis HLL 标准误差为 0.81%。
关于 HyperLogLog 有三个指令:
PFADD var element1 element2 ...:向一个 key 中加入一个或多个元素PFCOUNT var:获取一个 key 中的基数评估PFCOUNT var1 var2 ...:获取多个 key 合并后的基数评估PFMERGE dst src1 src2 ...:将多个 key 合并成1个存储到 dst 中
3.1 头
通过上边的结构,我们可以看到整个 HLL 的结构有 4 个字段组成的“头”,以及寄存器数组地址。头中有三个有意义的元素:
+------+---+-----+----------+
| HYLL | E | N/U | Cardin. |
+------+---+-----+----------+
- char magic[4]:魔术字符串,固定为 HYLL
- encoding:1字节,标识是何种编码方式
- card: 8 字节,以小端序存储的 64 位整数,用于存储最近计算的基数(Cardinality),其中有 1 bit用来标识基数估算值是否有效。
来实际观察一个 HLL 的 Header:
127.0.0.1:6379> PFADD test_key user1
(integer) 1
127.0.0.1:6379> PFCOUNT test_key
(integer) 1
127.0.0.1:6379> GETRANGE test_key 0 15
"HYLL\x01\x00\x00\x00\x01\x00\x00\x00\x00\x00\x00\x00"
根据前面的介绍可以看到 magic = “HYLL”, encoding = 1 表示是稀疏模式,而 card = 0x01(忽略了高位的0x00),表示基数估算值为 1。
3.2 寄存器数组存储
HLL 使用了 14 位作为寄存器的索引,50位用于计算连续0的个数。因此寄存器有 2^14 => 16384个,而每个寄存器大小 6bit 可以记录 063(实际只会是 051)。
寄存器的两种存储方式。其实稠密和稀疏描述的是寄存器的占用情况,如果16384 个寄存器中极少数有值而大部分是0就会使用稀疏模式,而大多数有值而极少数是0就会使用稠密模式。
3.2.1 稠密模式
稠密模式是为每个寄存器都分配空间,占用空间的总大小是 6 * 16384 / 8 = 12KB,在内存中分布如下:
* The dense representation used by Redis is the following:
*
* +--------+--------+--------+------// //--+
* |11000000|22221111|33333322|55444444 .... |
* +--------+--------+--------+------// //--+
每个字节先使用最低有效位(即从右侧开始使用)。如果一个寄存器会落在两个字节中,则前边一个字节放的是寄存器的低有效位,比如上边第一字节的 11 是 register[1] 的最低两位。前三个字节中寄存器的实际取值的获得方法是:
r0 = r[0] & 63;
r1 = (r[0] >> 6 | r[1] << 2) & 63;
r2 = (r[1] >> 4 | r[2] << 4) & 63;
r3 = (r[2] >> 2) & 63;
3.2.2 稀疏模式
在只有少量寄存器有值的场景中,稀疏模式可以极大地压缩空间,这对内存型数据库的 Redis 来说,非常重要。
来直观地感受一下,以前面只加入一个user1 的 test_key 来观察,总共长度是21,除去16字节头部,仅仅使用了5 字节来代替了 12KB 的存储空间。
127.0.0.1:6379> STRLEN test_key
(integer) 21
127.0.0.1:6379> GETRANGE test_key 16 20
"y\x00\x80F\xfd"
-- 0b01111001 0b00000000 0b10000000 0b01000110 0b11111101
稀疏模式的实现方式比较简单,其实就是将所有寄存器的值进行编码。有三种编码操作符
- ZERO:00xxxxxx,00是前缀,6bit表示连续0的长度。
- XZERO:01xxxxxx yyyyyyyy,01是前缀,14bit表示连续0的长度,最多可以表示16384个。
- VAL:1vvvvvxx,1是前缀,5bit表示要设成的值,2bit表示非0值的连续长度。VAL 能记录的最大值是 5 bit,也就是最大能记录 32,如果连续 0 的超过这个长度,就会转换成稠密模式。
XZERO 中的 X 是 eXtensible 的意思,表示对 ZERO 的扩展,可以处理更长。
根据上边的例子中的 5 个字节,我们可以解析成 3 条操作,即只有下标为 14593 的寄存器是 1:
XZERO: 14593 # 0b01111001 0b00000000
VAL: 1,1 # 0b10000000
XZERO: 1790 # 0b01000110 0b11111101
3.2.3 模式切换
除了上边提到的大数值无法用稀疏模式表示,还要考虑什么情况从稀疏模式切换成稠密模式。
源代码中有给出稀疏模式表示的计数值和存储空间的一个关系,是个大概关系:
| 基数估计值 | 稀疏模式占用空间 |
|---|---|
| 100 | 267 |
| 500 | 1033 |
| 1000 | 1882 |
| 2000 | 3480 |
| 3000 | 4879 |
| 5000 | 7138 |
| 10000 | 10591 |
上边可以看到,在基数是10000左右的时候,稀疏模式占用的空间已经快接近稠密模式的 12KB 了。那是不是在这时候做切换呢?*其实要更早,当稀疏模式所占空间接近稠密模式时,空间上的优势变得很小,但*编码/解码将会带来计算量的增加,相对于稠密模式明显地增加了 CPU 的负担。因此要取得比较明显的优势,需要将这个转换门槛设置的更低。
redis的配置项 hll_sparse_max_bytes 默认是 3000,也就是当稀疏表示的长度超过 3000 时,会转换成稠密模式。
3.3 算法辅助函数
这里所谓“辅助”是相对于后边的“封装”函数一节而言的,但是 HLL 的核心思想也有体现在这些函数中。比如 Hash、000..1 的长度、加入一个新元素等等。Redis 实现 HLL 是分为稠密和稀疏两种模式,两种只是存储方式的区别。因此,为了简洁清晰,这部分也只介绍稠密模式的相关函数。
3.3.1 Hash函数
HyperLogLog 需要一个64位 Hash 函数,Redis 的实现中采用了 MurmurHash2 的 64 位版本。MurmurHash2 是一种非加密的哈希算法,具有良好的分布性和较低的冲突率,同时在处理速度和哈希质量之间做了平衡。实现中进行了端序中立的修改——可以在大端和小端架构中提供相同的结果。
uint64_t MurmurHash64A (const void * key, int len, unsigned int seed)
const void * key, int len 用来表示需要做 Hash 的内容,是典型的 C 语言中表达方式。指针指向数据的起始位置,而长度表示数据的大小或长度。
unsigned int seed 用于初始化哈希算法的种子值,该函数实际被调用的时候,固定传入的是 0xadc83b19ULL。
3.3.2 HLLPatLen 函数
作用:将一个 字符串进行 Hash,获得 64bit Hash 值之后,计算:
-
对应寄存器索引(最低的 14bit。
-
pattern 000..1 的长度(高 50bit),计数是从1开始的,而不是从 0 开始,取值范围可能是 1
HLL_Q。这样做的好处是,寄存器中的值如果是 0 表示还没有进来过元素。这也决定了,后边的 RegHisto 直方统计数组得有 HLL_Q + 2 个元素(0,1HLL_Q)。在计算 pattern 的时候,其实是从最低有效位往最高有效位去判断的,也就是计算最右侧 10..00 连续0的长度。为了简化处理,源码中直接将第 51 位设置成了1(hash |= ((uint64_t)1<<HLL_Q);)
int hllPatLen(unsigned char *ele, size_t elesize, long *regp) {
uint64_t hash, bit, index;
int count;
/* Count the number of zeroes starting from bit HLL_REGISTERS
* (that is a power of two corresponding to the first bit we don't use
* as index). The max run can be 64-P+1 = Q+1 bits.
*
* Note that the final "1" ending the sequence of zeroes must be
* included in the count, so if we find "001" the count is 3, and
* the smallest count possible is no zeroes at all, just a 1 bit
* at the first position, that is a count of 1.
*
* This may sound like inefficient, but actually in the average case
* there are high probabilities to find a 1 after a few iterations. */
hash = MurmurHash64A(ele,elesize,0xadc83b19ULL);
index = hash & HLL_P_MASK; /* Register index. */
hash >>= HLL_P; /* Remove bits used to address the register. */
hash |= ((uint64_t)1<<HLL_Q); /* Make sure the loop terminates
and count will be <= Q+1. */
bit = 1;
count = 1; /* Initialized to 1 since we count the "00000...1" pattern. */
while((hash & bit) == 0) {
count++;
bit <<= 1;
}
*regp = (int) index;
return count;
}
3.3.3 hllDenseSet / hllDenseAdd
作用:在给定的稠密 HLL 寄存器数组中,将指定索引的寄存器的值设置为 count 值,前提是当前值小于给定值。寄存器中存储的,是落到这个寄存器的所有值的最大 hllPatLen 的值。所以假设寄存器原来的值是 4,我们要设置进去一个 2,是不起作用的;只有设置进去一个比 4 大的才会起作用。
而只有当寄存器的值发生变化,计算的近似基数才会发生变化。所以这个函数通过返回 1or0,来表示寄存器是否发生变化,来进一步决定后边是否更新 “Cardin.” 中存储的近似基数。
hllDenseAdd 是对 hllPatLen + hllDenseSet 做了一个简单封装,可以直接通过传入内容,来更新寄存器。
int hllDenseSet(uint8_t *registers, long index, uint8_t count) {
uint8_t oldcount;
HLL_DENSE_GET_REGISTER(oldcount,registers,index);
if (count > oldcount) {
HLL_DENSE_SET_REGISTER(registers,index,count);
return 1;
} else {
return 0;
}
}
3.3.3 hllDenseRegHisto
作用是计算在密集表示中的寄存器直方图。两个入参分别是:
-
registers是包含所有寄存器的数组,总共有 16384 个 6 bits的寄存器 -
reghisto是个数组,用来存储各寄存器的数值的频率;因为每个寄存器 6bit,取值0~63,所以 reghisto 的长度只有 64。但实际上寄存器中的值,只会存0HLL_Q(051),后边的一些bit一定会是0void hllDenseRegHisto(uint8_t *registers, int* reghisto)
3.4 算法实现
依然只关注 稠密模式的处理逻辑。
这个函数实际估算基数值。其实现是使用了 《New cardinality estimation algorithms for HyperLogLog sketches》 一文中的算法 6:

算法中涉及到三个系数:
- hllSigma(),函数
- hllTau(),函数
HLL_ALPHA_INF,宏定义
3.5 Redis命令相关函数
以下两个函数不会被 Redis 命令直接调用,但是会在 HLL 相关指令调用时,被间接用到:
- createHLLObject:创建 HLL 对象,因为是个新的空对象,所以是直接创建一个稀疏模式的对象。
- isHLLObjectOrReply: 判断对象是否是 HLL 对象
3.5.1 pfaddCommand
/* PFADD var ele ele ele … ele => :0 or :1 */
- 检查对象,如不存在则创建,如果存在且非 HLL 对象报错退出
- 针对key,对每个要加入的元素调用
hllAdd,记录更新的次数 - 如果存在更新,将基数 cache 位设置为无效
3.5.2 pfcountCommand
PFCOUNT 支持传入多个key,其作用是计算这多个 key 合并后的基数。因此,单个 key 和多个 key 的逻辑处理不一样。
单个 key 的处理,同样先进行常规的检查。然后计算计数:
- 如果 cache 有效,直接返回 cached 基数
- 如果 cache 失效(由于上边 pfadd 导致的),需要重新计算基数并 cache,返回
3.5.3 pfmergeCommand
/* PFMERGE dest src1 src2 src3 … srcN => OK */
首先创建一个数组,用来存储合并之后的16324 个寄存器的计数值。
然后处理每一个 HLL,调用 hllMerge 计算每个索引寄存器的最大值。
最后将合并之后的寄存器数组转换成 HLL 对象,存储到 dest。
3.6 Cache 的设计
因为基数估算值是根据后边的所有寄存器计算出来的,只寄存器中的值没有发生变化,这个值就不会变,可以直接使用上次计算的结果。
基于此,Redis 的实现中,HLL Header 中的 uint8_t card[8] 实际是个 Cache 值,而其中有一位就是用来标记 Cache 是否失效的(card[7] 的最高位):
#define HLL_VALID_CACHE(hdr) (((hdr)->card[7] & (1<<7)) == 0)
而当调用 PFADD 并且导致寄存器更新的时候,这个有效位会被置成无效,直到下次 PFCOUNT 时,判断需要重新计算,并将有效位置成有效。
该逻辑我们也可以通过 redis-cli 的指令清晰的观察到:
- 调用 PFADD 向空的 HLL 中加入一个元素之后,可以看到 card[7] 的值是 0x80,也就是 0b1000000,此时的估算值cache 是0,但是失效位是1,表示已经失效
- 调用一次 PFCOUNT 之后,card 变成了 1,而最高位变成了0,表示这里边的1是有效的基数估计值的Cache
127.0.0.1:6379> PFADD test_key user1
(integer) 1
127.0.0.1:6379> GETRANGE test_key 8 15
"\x00\x00\x00\x00\x00\x00\x00\x80"
127.0.0.1:6379> PFCOUNT test_key
(integer) 1
127.0.0.1:6379> GETRANGE test_key 8 15
"\x01\x00\x00\x00\x00\x00\x00\x00"
通过重复使用之前计算的基数值,可以节省计算时间和资源,并在实际数据结构没有修改的情况下提供近似的基数估计。这对于需要频繁进行基数估计、频繁进行新值插入的场景都非常有用:
PFADD远多于PFCOUNT,在每次PFADD之后,只是简单的将 chach 标志置为失效,不需要计算PFCOUNT远多于PFADD,在绝大部分PFCOUNT都是直接读取的缓存值,而无需计算
在以上三个函数中,我们都能看到,如果 HLL 对象发生变化,都会调用一段类似于这样的代码:
signalModifiedKey(c,c->db,c->argv[1]);
notifyKeyspaceEvent(NOTIFY_STRING,"pfadd",c->argv[1],c->db->id);
server.dirty += updated;
其中,c->db 是数据库的引用,c->db->id 是对应数据库的 ID。
这三个函数在Redis中的作用如下:
signalModifiedKey(c,c->db,c->argv[1]):用于通知 Redis 系统,一个键(c->argv[1])已经被修改了。这是Redis内部用于维护数据一致性的一种机制。notifyKeyspaceEvent(NOTIFY_STRING,"pfadd",c->argv[1],c->db->id):用于触发一个键空间事件,通知所有订阅了这个事件的客户端。在这个例子中,事件类型是NOTIFY_STRING,事件名称是pfadd,关联的键是c->argv[1]。server.dirty++;:这个语句用于增加服务器的 dirty 寄存器。在Redis中,该寄存器用于跟踪自上次保存以来数据库被修改的次数。每当一个写命令成功执行,这个寄存器就会增加。这个寄存器用于决定何时触发自动保存(AOF 或 RDB)。
另外,还有两个在函数进入时可能会调用的指令:
robj *o = lookupKeyWrite(c->db,c->argv[1]);
robj *o = lookupKeyRead(c->db,c->argv[j]);
这两个函数用于在数据库中查找一个键,并准备对它进行写/读操作。如果键存在,它返回一个指向该键的对象的指针。如果键不存在,它返回NULL。
两个函数的主要区别在于:lookupKeyWrite 会对键进行写入前的准备(例如,如果键被设置为只读,该函数会返回错误),而 lookupKeyRead 则不会。
附录
-
带部分注释的源码:
/*hyperloglog.c -Redis HyperLogLog 概率基数近似。 *该文件实现了算法和导出的Redis命令。 * *版权所有 (c) 2014 年至今,Redis Ltd. *版权所有。 * *根据您选择的 Redis 源可用许可证 2.0 获得许可 *(RSALv2) 或服务器端公共许可证 v1 (SSPLv1)。 */ #include "server.h" #include <stdint.h> #include <math.h> /*Redis HyperLogLog 实现基于以下思想: * **使用[1]中提出的64位散列函数,以估计 *基数大于 10^9,每个基数仅需要 1 个额外位 * 登记。 **使用 16384 个 6 位寄存器来实现很高的精度,使用 *每个键总共 12k。 **使用Redis字符串数据类型。没有引入新的类型。 **没有尝试像[1]中那样压缩数据结构。还有 *使用的算法是[2]中原始的HyperLogLog算法,其中 *唯一的区别是使用了 64 位哈希函数,因此无需更正 *对于接近 2^32 的值执行,如 [1] 中所示。 * *[1] Heule、Nunkesser、Hall:HyperLogLog 实践:算法 *最先进的基数估计算法的工程。 * *[2] P. Flajolet、Éric Fusy、O. Gandouet 和 F. Meunier。超级日志: *近乎最优基数估计算法的分析。 * *Redis使用两种表示方式: * *1)“密集”表示,其中每个条目都由 *6 位整数。 *2) 使用合适的游程压缩的“稀疏”表示 *用于表示 HyperLogLogs,其中许多寄存器设置为 0 *一种有效的内存方式。 * * *HLL 标头 *=== * *密集表示和稀疏表示都有一个 16 字节的标头,如下所示: * *+------+---+-----+----------+ *|希尔 |电子|不适用 |卡丹。 | *+------+---+-----+----------+ * *前 4 个字节是设置为字节“HYLL”的魔术字符串。 *“E”是一字节编码,当前设置为HLL_DENSE或 *HLL_SPARSE。 N/U 是三个未使用的字节。 * *“卡丹”。字段是以小端格式存储的 64 位整数 *计算出最新的基数,如果数据可以重用 *自上次计算以来结构没有被修改(这很有用 *因为 HLLADD 操作很可能不会 *修改实际的数据结构,从而修改近似的基数)。 * *当缓存的最高有效字节中的最高有效位 *设置了基数,意味着数据结构被修改了 *我们不能重用必须重新计算的缓存值。 * *密集表示 *=== * *Redis使用的密集表示如下: * *+--------+--------+--------+--------////--+ *|11000000|22221111|33333322|55444444 .... | *+--------+--------+--------+--------////--+ * *6 位计数器从 1 开始依次编码 *LSB 到 MSB,并根据需要使用接下来的字节。 * *稀疏表示 *=== * *稀疏表示使用游程长度对寄存器进行编码 *编码由三个操作码组成,两个使用一个字节,一个使用 *两个字节。操作码称为 ZERO、XZERO 和 VAL。 * *零操作码表示为 00xxxxxx。表示的6位整数 *由六位'xxxxxx'加1,表示有N个寄存器设置 *到 0。该操作码可以代表 1 到 64 个连续的寄存器集 *为 0 值。 * *XZERO 操作码由两个字节 01xxxxxx yyyyyyyy 表示。 14位 *由位“xxxxxx”表示的整数作为最高有效位,并且 *'yyyyyyyy' 作为最低有效位,加 1,表示有 N *寄存器设置为0。该操作码可以表示从0到16384的连续 *寄存器的值设置为 0。 * *VAL 操作码表示为 1vvvvvxx。它包含一个5位整数 *代表寄存器的值,2位整数代表 *设置为该值“vvvvv”的连续寄存器的数量。 *要获取值和游程长度,整数 vvvvv 和 xx 必须是 *加一。该操作码可以表示从 1 到 32 的值, *重复 1 至 4 次。 * *稀疏表示不能表示数值更大的寄存器 *大于 32,但是我们不太可能在某个寄存器中找到这样的寄存器 *HLL 具有基数,其中稀疏表示仍然更多 *比密集表示的内存效率更高。当这种情况发生时 *HLL 转换为稠密表示。 * *稀疏表示纯粹是位置性的。例如稀疏 *空 HLL 的表示就是:XZERO:16384。 * *HLL 在位置 1000、1020、1021 处仅具有 3 个非零寄存器 *分别设置为2、3、3,则用以下三个表示 *操作码: * *XZERO:1000(寄存器0-999设置为0) *VAL:2,1(1个寄存器设置为值2,即寄存器1000) *ZERO:19(寄存器1001-1019设置为0) *VAL:3,2(2个寄存器设置为值3,即寄存器1020,1021) *XZERO:15362(寄存器1022-16383设置为0) * *在示例中,稀疏表示仅使用 7 个字节 *12k 以便表示 HLL 寄存器。一般情况下对于低 *基数在空间效率方面有很大的胜利,可交易 *与 CPU 时间有关,因为稀疏表示的访问速度较慢。 * *下表显示平均基数与使用的字节数,100 *每个基数的样本(当集合不可表示时,因为 *对于值太大的寄存器,使用了密集表示大小 *作为示例)。 * *100267 *200 485 *300 678 *400 859 *500 1033 *600 1205 *700 1375 *800 1544 *900 1713 *1000 1882 *2000 3480 *3000 4879 *4000 6089 *5000 7138 *6000 8042 *7000 8823 *8000 9500 *9000 10088 *10000 10591 * *密集表示使用 12288 字节,因此有一个很大的胜利 *基数约为 2000-3000。对于更大的基数,常数倍 *参与更新稀疏表示是不合理的 *节省内存。稀疏表示的确切最大长度 *当这个实现切换到密集表示时是 *通过定义 server.hll_sparse_max_bytes 配置。 */ struct hllhdr { char magic[4]; /* "HYLL" */ uint8_t encoding; /* HLL_DENSE or HLL_SPARSE. */ uint8_t notused[3]; /*保留供将来使用,必须为零。*/ uint8_t card[8]; /*缓存基数,小端。*/ uint8_t registers[]; /* Data bytes. */ }; /*缓存的基数 MSB 用于指示缓存值的有效性。*/ #define HLL_INVALIDATE_CACHE(hdr) (hdr)->card[7] |= (1 << 7) #define HLL_VALID_CACHE(hdr) (((hdr)->card[7] & (1 << 7)) == 0) #define HLL_P 14 /*P越大,误差越小。*/ #define HLL_Q (64 - HLL_P) /*用于的哈希值的位数 \ 确定前导零的数量。*/ #define HLL_REGISTERS (1 << HLL_P) /*当 P=14 时,16384 个寄存器。*/ #define HLL_P_MASK (HLL_REGISTERS - 1) /* Mask to index register. */ #define HLL_BITS 6 /* Enough to count up to 63 leading zeroes. */ #define HLL_REGISTER_MAX ((1 << HLL_BITS) - 1) #define HLL_HDR_SIZE sizeof(struct hllhdr) #define HLL_DENSE_SIZE (HLL_HDR_SIZE + ((HLL_REGISTERS * HLL_BITS + 7) / 8)) #define HLL_DENSE 0 /* Dense encoding. */ #define HLL_SPARSE 1 /* Sparse encoding. */ #define HLL_RAW 255 /* Only used internally, never exposed. */ #define HLL_MAX_ENCODING 1 static char *invalid_hll_err = "-INVALIDOBJ Corrupted HLL object detected"; /*============================= 低级位宏 ================= ======== */ /*用于访问密集表示的宏。 * *我们需要在 8 位字节数组中获取和设置 6 位计数器。 *我们使用宏来确保代码内联,因为速度至关重要 *特别是为了计算近似基数 *HLLCOUNT,我们需要一次访问所有寄存器。 *出于同样的原因,我们也希望避免在此代码路径中出现条件。 * *+--------+--------+--------+--------// *|11000000|22221111|33333322|55444444 *+--------+--------+--------+--------// * *注:以上表示中最高有效位(MSB) 每个字节的 *位于左侧。我们开始使用从 LSB 到 MSB 的位, *等等传递到下一个字节。 * *例如,我们想要访问 pos = 1 处的计数器(“111111” *上图)。 * *包含我们数据的第一个字节 b0 的索引是: * *b0 = 6 *位置 /8 = 0 * *+--------+ *|11000000| <-我们的字节位于 b0 *+--------+ * *字节中第一位(从 LSB = 0 开始计数)的位置 *是(谁)给的: * *FB = 6 *POS % 8 -> 6 * *右移“fb”位的 b0。 * *+--------+ *|11000000| <-b0 的初始值 *|00000011| <-右移 6 位后。 *+--------+ * *位 8-fb 位左移 b1 位(2 位) * *+--------+ *|22221111| <-b1 的初始值 *|22111100| <-左移 2 位后。 *+--------+ * *两位或,最后与 111111(十进制 63)进行与 *清理我们不感兴趣的高阶位: * *+--------+ *|00000011| <-b0 右移 *|22111100| <-b1 左移 *|22111111| <-b0 或 b1 *| 111111| <-(b0 OR b1) AND 63,我们的值。 *+--------+ * *我们可以尝试使用不同的示例,例如 pos = 0。在本例中 *6 位计数器实际上包含在一个字节中。 * *b0 = 6 *位置 /8 = 0 * *+--------+ *|11000000| <-我们的字节位于 b0 *+--------+ * *FB = 6 *POS % 8 = 0 * *所以我们右移 0 位(实际上没有移位)并且 *左移下一个8位字节,即使我们不使用它, *但这具有清除位的效果,因此结果 *OR 后不会受到影响。 * *------------------------------------------------------------------------- * *设置寄存器有点复杂,我们假设'val' *是我们要设置的值,已经在正确的范围内了。 * *我们需要两个步骤,第一步我们需要清除这些位,第二步 *我们需要对新位进行按位或运算。 * *让我们尝试使用 'pos' = 1,因此 'b' 处的第一个字节是 0, * *在本例中“fb”为 6。 * *+--------+ *|11000000| <-我们的字节位于 b0 *+--------+ * *要创建一个 AND 掩码来清除该位置的位,我们只需 *用值 63 初始化掩码,左移“fs”位, *最后将结果取反。 * *+--------+ *|00111111| <-“面具”从 63 开始 *|11000000| <-“ls”位左移后的“掩码”。 *|00111111| <-反转后的“掩码”。 *+--------+ * *现在我们可以将“b”处的字节与掩码进行按位与,然后按位或 *它与“val”左移“ls”位来设置新位。 * *现在让我们关注下一个字节b1: * *+--------+ *|22221111| <-b1 的初始值 *+--------+ * *为了构建 AND 掩码,我们再次从 63 值开始,右移 *将其乘以 8-fb 位,并将其反转。 * *+--------+ *|00111111| <-“掩码”设置为 2&6-1 *|00001111| <-右移 8-fb = 2 位后的“掩码” *|11110000| <-按位非后的“掩码”。 *+--------+ * *现在我们可以用 b+1 屏蔽它以清除旧位,然后按位或 *将“val”左移“rs”位以设置新值。 */ /*注意:如果我们访问最后一个计数器,我们还将访问 b+1 字节 *不在数组中,但 sds 字符串总是有一个隐式 null *term,所以该字节存在,我们可以跳过条件句(或者需要 *更明确地分配 1 个字节)。*/ /*将位置“regnum”处的寄存器值存储到变量“target”中。 *'p' 是无符号字节数组。*/ #define HLL_DENSE_GET_REGISTER(target, p, regnum) \ do \ { \ uint8_t *_p = (uint8_t *)p; \ unsigned long _byte = regnum * HLL_BITS / 8; \ unsigned long _fb = regnum * HLL_BITS & 7; \ unsigned long _fb8 = 8 - _fb; \ unsigned long b0 = _p[_byte]; \ unsigned long b1 = _p[_byte + 1]; \ target = ((b0 >> _fb) | (b1 << _fb8)) & HLL_REGISTER_MAX; \ } while (0) /*将位置“regnum”处的寄存器的值设置为“val”。 *'p' 是无符号字节数组。*/ #define HLL_DENSE_SET_REGISTER(p, regnum, val) \ do \ { \ uint8_t *_p = (uint8_t *)p; \ unsigned long _byte = (regnum) * HLL_BITS / 8; \ unsigned long _fb = (regnum) * HLL_BITS & 7; \ unsigned long _fb8 = 8 - _fb; \ unsigned long _v = (val); \ _p[_byte] &= ~(HLL_REGISTER_MAX << _fb); \ _p[_byte] |= _v << _fb; \ _p[_byte + 1] &= ~(HLL_REGISTER_MAX >> _fb8); \ _p[_byte + 1] |= _v >> _fb8; \ } while (0) /*用于访问稀疏表示的宏。 *宏参数应该是一个 uint8_t 指针。*/ #define HLL_SPARSE_XZERO_BIT 0x40 /* 01xxxxxx */ #define HLL_SPARSE_VAL_BIT 0x80 /* 1vvvvvxx */ #define HLL_SPARSE_IS_ZERO(p) (((*(p)) & 0xc0) == 0) /* 00xxxxxx */ #define HLL_SPARSE_IS_XZERO(p) (((*(p)) & 0xc0) == HLL_SPARSE_XZERO_BIT) #define HLL_SPARSE_IS_VAL(p) ((*(p)) & HLL_SPARSE_VAL_BIT) #define HLL_SPARSE_ZERO_LEN(p) (((*(p)) & 0x3f) + 1) #define HLL_SPARSE_XZERO_LEN(p) (((((*(p)) & 0x3f) << 8) | (*((p) + 1))) + 1) #define HLL_SPARSE_VAL_VALUE(p) ((((*(p)) >> 2) & 0x1f) + 1) #define HLL_SPARSE_VAL_LEN(p) (((*(p)) & 0x3) + 1) #define HLL_SPARSE_VAL_MAX_VALUE 32 #define HLL_SPARSE_VAL_MAX_LEN 4 #define HLL_SPARSE_ZERO_MAX_LEN 64 #define HLL_SPARSE_XZERO_MAX_LEN 16384 #define HLL_SPARSE_VAL_SET(p, val, len) \ do \ { \ *(p) = (((val)-1) << 2 | ((len)-1)) | HLL_SPARSE_VAL_BIT; \ } while (0) #define HLL_SPARSE_ZERO_SET(p, len) \ do \ { \ *(p) = (len)-1; \ } while (0) #define HLL_SPARSE_XZERO_SET(p, len) \ do \ { \ int _l = (len)-1; \ *(p) = (_l >> 8) | HLL_SPARSE_XZERO_BIT; \ *((p) + 1) = (_l & 0xff); \ } while (0) #define HLL_ALPHA_INF 0.721347520444481703680 /*0.5/ln(2) 的常数*/ /*========================= HyperLogLog算法 ===================== ==== */ /*我们的哈希函数是 MurmurHash2,64 位版本。 *为了在 Redis 中提供相同的结果,对其进行了修改 *大字节序和小字节序拱门(字节序中立)。*/ REDIS_NO_SANITIZE("alignment") uint64_t MurmurHash64A(const void *key, int len, unsigned int seed) { const uint64_t m = 0xc6a4a7935bd1e995; const int r = 47; uint64_t h = seed ^ (len * m); const uint8_t *data = (const uint8_t *)key; const uint8_t *end = data + (len - (len & 7)); while (data != end) { uint64_t k; #if (BYTE_ORDER == LITTLE_ENDIAN) #ifdef USE_ALIGNED_ACCESS memcpy(&k, data, sizeof(uint64_t)); #else k = *((uint64_t *)data); #endif #else k = (uint64_t)data[0]; k |= (uint64_t)data[1] << 8; k |= (uint64_t)data[2] << 16; k |= (uint64_t)data[3] << 24; k |= (uint64_t)data[4] << 32; k |= (uint64_t)data[5] << 40; k |= (uint64_t)data[6] << 48; k |= (uint64_t)data[7] << 56; #endif k *= m; k ^= k >> r; k *= m; h ^= k; h *= m; data += 8; } switch (len & 7) { case 7: h ^= (uint64_t)data[6] << 48; /* fall-thru */ case 6: h ^= (uint64_t)data[5] << 40; /* fall-thru */ case 5: h ^= (uint64_t)data[4] << 32; /* fall-thru */ case 4: h ^= (uint64_t)data[3] << 24; /* fall-thru */ case 3: h ^= (uint64_t)data[2] << 16; /* fall-thru */ case 2: h ^= (uint64_t)data[1] << 8; /* fall-thru */ case 1: h ^= (uint64_t)data[0]; h *= m; /* fall-thru */ }; h ^= h >> r; h *= m; h ^= h >> r; return h; } /*给定要添加到 HyperLogLog 的字符串元素,返回长度 *元素哈希的模式 000..1。作为副作用“regp”是 *设置为该元素散列到的寄存器索引。*/ int hllPatLen(unsigned char *ele, size_t elesize, long *regp) { uint64_t hash, bit, index; int count; /*计算从 HLL_REGISTERS 位开始的零的数量 *(这是对应于我们不使用的第一位的二的幂 *作为索引)。最大运行可以是 64-P+1 = Q+1 位。 * *请注意,结束零序列的最后一个“1”必须是 *包含在计数中,因此如果我们找到“001”,则计数为 3,并且 *可能的最小计数根本没有零,只有 1 位 *在第一个位置,即计数为 1。 * *这听起来似乎效率很低,但实际上在平均情况下 *经过几次迭代后,很有可能找到 1。*/ hash = MurmurHash64A(ele, elesize, 0xadc83b19ULL); index = hash & HLL_P_MASK; /* Register index. */ hash >>= HLL_P; /* Remove bits used to address the register. */ hash |= ((uint64_t)1 << HLL_Q); /* Make sure the loop terminates and count will be <= Q+1. */ bit = 1; count = 1; /* Initialized to 1 since we count the "00000...1" pattern. */ while ((hash & bit) == 0) { count++; bit <<= 1; } *regp = (int)index; return count; } /*================== 密集表示实现 ================== */ /*将密集 HLL 寄存器设置为“索引”的低级函数 *如果当前值小于“count”,则指定值。 * *“寄存器”预计有空间容纳 HLL_REGISTERS 加上一个 *右侧附加字节。 sds 字符串满足此要求 *自动,因为它们隐式以 null 终止。 * *该函数总是成功,但是如果作为操作的结果 *近似基数发生变化,返回1。否则 0 *被返回。*/ int hllDenseSet(uint8_t *registers, long index, uint8_t count) { uint8_t oldcount; HLL_DENSE_GET_REGISTER(oldcount, registers, index); if (count > oldcount) { HLL_DENSE_SET_REGISTER(registers, index, count); return 1; } else { return 0; } } /*在密集的 hyperloglog 数据结构中“添加”元素。 *实际上什么也没添加,只是子集的最大0模式计数器 *如果需要,元素所属的元素会递增。 * *这只是 hllDenseSet() 的包装,执行哈希 *元素以检索索引和零游程计数。*/ int hllDenseAdd(uint8_t *registers, unsigned char *ele, size_t elesize) { long index; uint8_t count = hllPatLen(ele, elesize, &index); /* Update the register if this element produced a longer run of zeroes. */ return hllDenseSet(registers, index, count); } /* Compute the register histogram in the dense representation. */ void hllDenseRegHisto(uint8_t *registers, int *reghisto) { int j; /*Redis 默认使用 16384 个寄存器,每个寄存器 6 位。代码有效 *通过修改定义使用其他值,但对于我们的目标值 *我们采用展开循环的更快路径。*/ if (HLL_REGISTERS == 16384 && HLL_BITS == 6) { uint8_t *r = registers; unsigned long r0, r1, r2, r3, r4, r5, r6, r7, r8, r9, r10, r11, r12, r13, r14, r15; for (j = 0; j < 1024; j++) { /* Handle 16 registers per iteration. */ r0 = r[0] & 63; r1 = (r[0] >> 6 | r[1] << 2) & 63; r2 = (r[1] >> 4 | r[2] << 4) & 63; r3 = (r[2] >> 2) & 63; r4 = r[3] & 63; r5 = (r[3] >> 6 | r[4] << 2) & 63; r6 = (r[4] >> 4 | r[5] << 4) & 63; r7 = (r[5] >> 2) & 63; r8 = r[6] & 63; r9 = (r[6] >> 6 | r[7] << 2) & 63; r10 = (r[7] >> 4 | r[8] << 4) & 63; r11 = (r[8] >> 2) & 63; r12 = r[9] & 63; r13 = (r[9] >> 6 | r[10] << 2) & 63; r14 = (r[10] >> 4 | r[11] << 4) & 63; r15 = (r[11] >> 2) & 63; reghisto[r0]++; reghisto[r1]++; reghisto[r2]++; reghisto[r3]++; reghisto[r4]++; reghisto[r5]++; reghisto[r6]++; reghisto[r7]++; reghisto[r8]++; reghisto[r9]++; reghisto[r10]++; reghisto[r11]++; reghisto[r12]++; reghisto[r13]++; reghisto[r14]++; reghisto[r15]++; r += 12; } } else { for (j = 0; j < HLL_REGISTERS; j++) { unsigned long reg; HLL_DENSE_GET_REGISTER(reg, registers, j); reghisto[reg]++; } } } /*================== 稀疏表示实现 ================= */ /*将稀疏表示转换为稠密表示形式作为输入 *代表。两种表示形式均由 SDS 字符串表示,并且 *作为副作用,输入表示被释放。 * *如果稀疏表示有效,该函数返回 C_OK, *否则,如果表示损坏,则返回 C_ERR。*/ int hllSparseToDense(robj *o) { sds sparse = o->ptr, dense; struct hllhdr *hdr, *oldhdr = (struct hllhdr *)sparse; int idx = 0, runlen, regval; uint8_t *p = (uint8_t *)sparse, *end = p + sdslen(sparse); /* If the representation is already the right one return ASAP. */ hdr = (struct hllhdr *)sparse; if (hdr->encoding == HLL_DENSE) return C_OK; /* Create a string of the right size filled with zero bytes. * Note that the cached cardinality is set to 0 as a side effect * that is exactly the cardinality of an empty HLL. */ dense = sdsnewlen(NULL, HLL_DENSE_SIZE); hdr = (struct hllhdr *)dense; *hdr = *oldhdr; /* This will copy the magic and cached cardinality. */ hdr->encoding = HLL_DENSE; /* Now read the sparse representation and set non-zero registers * accordingly. */ p += HLL_HDR_SIZE; while (p < end) { if (HLL_SPARSE_IS_ZERO(p)) { runlen = HLL_SPARSE_ZERO_LEN(p); idx += runlen; p++; } else if (HLL_SPARSE_IS_XZERO(p)) { runlen = HLL_SPARSE_XZERO_LEN(p); idx += runlen; p += 2; } else { runlen = HLL_SPARSE_VAL_LEN(p); regval = HLL_SPARSE_VAL_VALUE(p); if ((runlen + idx) > HLL_REGISTERS) break; /* Overflow. */ while (runlen--) { HLL_DENSE_SET_REGISTER(hdr->registers, idx, regval); idx++; } p++; } } /* If the sparse representation was valid, we expect to find idx * set to HLL_REGISTERS. */ if (idx != HLL_REGISTERS) { sdsfree(dense); return C_ERR; } /* Free the old representation and set the new one. */ sdsfree(o->ptr); o->ptr = dense; return C_OK; } /*将稀疏 HLL 寄存器设置为“索引”的低级函数 *如果当前值小于“count”,则指定值。 * *对象“o”是保存 HLL 的 String 对象。该功能需要 *对对象的引用,以便能够放大字符串,如果 *需要。 * *成功时,如果基数发生变化,函数返回 1,否则返回 0 *如果该元素的寄存器未更新。 *出错时(如果表示无效)返回-1。 * *作为副作用,该函数可能会提升 HLL 表示形式 *稀疏到密集:当寄存器需要设置一个值时会发生这种情况 *无法用稀疏表示来表示,或者当结果 *大小将大于 server.hll_sparse_max_bytes。*/ int hllSparseSet(robj *o, long index, uint8_t count) { struct hllhdr *hdr; uint8_t oldcount, *sparse, *end, *p, *prev, *next; long first, span; long is_zero = 0, is_xzero = 0, is_val = 0, runlen = 0; /*如果计数太大而无法用稀疏表示表示 *切换到密集表示。*/ if (count > HLL_SPARSE_VAL_MAX_VALUE) goto promote; /*当更新稀疏表示时,有时我们可能需要放大 *最坏情况下最多可容纳 3 个字节的缓冲区(XZERO 拆分为 XZERO-VAL-XZERO), *下面的代码完成放大工作。 *实际上,我们使用贪心策略,放大超过3个字节以避免需要 *未来根据增量增长进行重新分配。但我们不会分配超过 *稀疏表示的“server.hll_sparse_max_bytes”字节。 *如果hyperloglog sds字符串的可用大小不足以增量 *我们需要,我们在“步骤 3”中将 hypreloglog 提升为密集表示。 */ if (sdsalloc(o->ptr) < server.hll_sparse_max_bytes && sdsavail(o->ptr) < 3) { size_t newlen = sdslen(o->ptr) + 3; newlen += min(newlen, 300); /* Greediness: double 'newlen' if it is smaller than 300, or add 300 to it when it exceeds 300 */ if (newlen > server.hll_sparse_max_bytes) newlen = server.hll_sparse_max_bytes; o->ptr = sdsResize(o->ptr, newlen, 1); } /* Step 1: we need to locate the opcode we need to modify to check * if a value update is actually needed. */ sparse = p = ((uint8_t *)o->ptr) + HLL_HDR_SIZE; end = p + sdslen(o->ptr) - HLL_HDR_SIZE; first = 0; prev = NULL; /* Points to previous opcode at the end of the loop. */ next = NULL; /* Points to the next opcode at the end of the loop. */ span = 0; while (p < end) { long oplen; /* Set span to the number of registers covered by this opcode. * * This is the most performance critical loop of the sparse * representation. Sorting the conditionals from the most to the * least frequent opcode in many-bytes sparse HLLs is faster. */ oplen = 1; if (HLL_SPARSE_IS_ZERO(p)) { span = HLL_SPARSE_ZERO_LEN(p); } else if (HLL_SPARSE_IS_VAL(p)) { span = HLL_SPARSE_VAL_LEN(p); } else { /* XZERO. */ span = HLL_SPARSE_XZERO_LEN(p); oplen = 2; } /* Break if this opcode covers the register as 'index'. */ if (index <= first + span - 1) break; prev = p; p += oplen; first += span; } if (span == 0 || p >= end) return -1; /* Invalid format. */ next = HLL_SPARSE_IS_XZERO(p) ? p + 2 : p + 1; if (next >= end) next = NULL; /* Cache current opcode type to avoid using the macro again and * again for something that will not change. * Also cache the run-length of the opcode. */ if (HLL_SPARSE_IS_ZERO(p)) { is_zero = 1; runlen = HLL_SPARSE_ZERO_LEN(p); } else if (HLL_SPARSE_IS_XZERO(p)) { is_xzero = 1; runlen = HLL_SPARSE_XZERO_LEN(p); } else { is_val = 1; runlen = HLL_SPARSE_VAL_LEN(p); } /*第 2 步:循环之后: * *'first' 存储到所覆盖的第一个寄存器的索引 *通过当前操作码,由“p”指向。 * *'next' 和 'prev' 分别存储下一个和上一个操作码, *如果“p”处的操作码分别是最后一个或第一个,则为 NULL。 * *'span' 设置为当前覆盖的寄存器数量 *操作码。 * *有不同情况才能更新数据结构 *就位,无需从头开始生成: * *A) 如果它是一个 VAL 操作码,其值已设置为 >= 我们的“计数” *无论 VAL 游程长度字段如何,都不需要更新。 *在这种情况下,PFADD 返回 0,因为没有执行任何更改。 * *B) 如果它是 VAL 操作码,len = 1(仅代表我们的 *register)并且该值小于'count',我们只是更新它 *因为这是一个微不足道的案例。*/ if (is_val) { oldcount = HLL_SPARSE_VAL_VALUE(p); /* Case A. */ if (oldcount >= count) return 0; /* Case B. */ if (runlen == 1) { HLL_SPARSE_VAL_SET(p, count, 1); goto updated; } } /* C) Another trivial to handle case is a ZERO opcode with a len of 1. * We can just replace it with a VAL opcode with our value and len of 1. */ if (is_zero && runlen == 1) { HLL_SPARSE_VAL_SET(p, count, 1); goto updated; } /*D) 一般情况。 * *其他情况更复杂:我们的寄存器需要更新 *并且当前由 len > 1 的 VAL 操作码表示, *通过 len > 1 的 ZERO 操作码,或通过 XZERO 操作码。 * *在这些情况下,原始操作码必须分成多个 *操作码。最坏的情况是中间的 XZERO 分裂导致 *XZERO -VAL -XZERO,因此得到的序列最大长度为 *5 字节。 * *我们执行分割,将新序列写入“新”缓冲区 *以“newlen”作为长度。随后将新序列插入到位 *旧的,可能将右侧的内容移动几个字节 *如果新序列比旧序列长。*/ uint8_t seq[5], *n = seq; int last = first + span - 1; /* Last register covered by the sequence. */ int len; if (is_zero || is_xzero) { /* Handle splitting of ZERO / XZERO. */ if (index != first) { len = index - first; if (len > HLL_SPARSE_ZERO_MAX_LEN) { HLL_SPARSE_XZERO_SET(n, len); n += 2; } else { HLL_SPARSE_ZERO_SET(n, len); n++; } } HLL_SPARSE_VAL_SET(n, count, 1); n++; if (index != last) { len = last - index; if (len > HLL_SPARSE_ZERO_MAX_LEN) { HLL_SPARSE_XZERO_SET(n, len); n += 2; } else { HLL_SPARSE_ZERO_SET(n, len); n++; } } } else { /* Handle splitting of VAL. */ int curval = HLL_SPARSE_VAL_VALUE(p); if (index != first) { len = index - first; HLL_SPARSE_VAL_SET(n, curval, len); n++; } HLL_SPARSE_VAL_SET(n, count, 1); n++; if (index != last) { len = last - index; HLL_SPARSE_VAL_SET(n, curval, len); n++; } } /* Step 3: substitute the new sequence with the old one. * * Note that we already allocated space on the sds string * calling sdsResize(). */ int seqlen = n - seq; int oldlen = is_xzero ? 2 : 1; int deltalen = seqlen - oldlen; if (deltalen > 0 && sdslen(o->ptr) + deltalen > server.hll_sparse_max_bytes) goto promote; serverAssert(sdslen(o->ptr) + deltalen <= sdsalloc(o->ptr)); if (deltalen && next) memmove(next + deltalen, next, end - next); sdsIncrLen(o->ptr, deltalen); memcpy(p, seq, seqlen); end += deltalen; updated: /* Step 4: Merge adjacent values if possible. * * The representation was updated, however the resulting representation * may not be optimal: adjacent VAL opcodes can sometimes be merged into * a single one. */ p = prev ? prev : sparse; int scanlen = 5; /* Scan up to 5 upcodes starting from prev. */ while (p < end && scanlen--) { if (HLL_SPARSE_IS_XZERO(p)) { p += 2; continue; } else if (HLL_SPARSE_IS_ZERO(p)) { p++; continue; } /* We need two adjacent VAL opcodes to try a merge, having * the same value, and a len that fits the VAL opcode max len. */ if (p + 1 < end && HLL_SPARSE_IS_VAL(p + 1)) { int v1 = HLL_SPARSE_VAL_VALUE(p); int v2 = HLL_SPARSE_VAL_VALUE(p + 1); if (v1 == v2) { int len = HLL_SPARSE_VAL_LEN(p) + HLL_SPARSE_VAL_LEN(p + 1); if (len <= HLL_SPARSE_VAL_MAX_LEN) { HLL_SPARSE_VAL_SET(p + 1, v1, len); memmove(p, p + 1, end - p); sdsIncrLen(o->ptr, -1); end--; /* After a merge we reiterate without incrementing 'p' * in order to try to merge the just merged value with * a value on its right. */ continue; } } } p++; } /* Invalidate the cached cardinality. */ hdr = o->ptr; HLL_INVALIDATE_CACHE(hdr); return 1; promote: /* Promote to dense representation. */ if (hllSparseToDense(o) == C_ERR) return -1; /* Corrupted HLL. */ hdr = o->ptr; /*我们需要调用hllDenseAdd()来执行后面的操作 *转换。然而结果必须是 1,因为如果我们需要 *从稀疏转换为密集需要更新寄存器。 * *请注意,这反过来意味着 PFADD 将确保该命令 *传播到slaves/AOF,所以如果有稀疏->密集 *转换,它也将在所有从站中执行。*/ int dense_retval = hllDenseSet(hdr->registers, index, count); serverAssert(dense_retval == 1); return dense_retval; } /*在稀疏 hyperloglog 数据结构中“添加”元素。 *实际上什么也没添加,只是子集的最大0模式计数器 *如果需要,元素所属的元素会递增。 * *该函数实际上是hllSparseSet()的包装,它只执行 *对元素进行散列以获得索引和零游程长度。*/ int hllSparseAdd(robj *o, unsigned char *ele, size_t elesize) { long index; uint8_t count = hllPatLen(ele, elesize, &index); /* Update the register if this element produced a longer run of zeroes. */ return hllSparseSet(o, index, count); } /* Compute the register histogram in the sparse representation. */ void hllSparseRegHisto(uint8_t *sparse, int sparselen, int *invalid, int *reghisto) { int idx = 0, runlen, regval; uint8_t *end = sparse + sparselen, *p = sparse; while (p < end) { if (HLL_SPARSE_IS_ZERO(p)) { runlen = HLL_SPARSE_ZERO_LEN(p); idx += runlen; reghisto[0] += runlen; p++; } else if (HLL_SPARSE_IS_XZERO(p)) { runlen = HLL_SPARSE_XZERO_LEN(p); idx += runlen; reghisto[0] += runlen; p += 2; } else { runlen = HLL_SPARSE_VAL_LEN(p); regval = HLL_SPARSE_VAL_VALUE(p); idx += runlen; reghisto[regval] += runlen; p++; } } if (idx != HLL_REGISTERS && invalid) *invalid = 1; } /*========================= HyperLogLog 计数 ======================= ======= *这是计算近似计数的算法的核心。 *该函数使用较低级别的hllDenseRegHisto()和hllSparseRegHisto() *作为帮助程序来计算寄存器值部分的直方图 *计算,这是特定于表示的,而其余的都是通用的。*/ /*实现uint8_t数据类型的寄存器直方图计算 *仅在内部用作具有多个键的 PFCOUNT 的加速。*/ void hllRawRegHisto(uint8_t *registers, int *reghisto) { uint64_t *word = (uint64_t *)registers; uint8_t *bytes; int j; for (j = 0; j < HLL_REGISTERS / 8; j++) { if (*word == 0) { reghisto[0] += 8; } else { bytes = (uint8_t *)word; reghisto[bytes[0]]++; reghisto[bytes[1]]++; reghisto[bytes[2]]++; reghisto[bytes[3]]++; reghisto[bytes[4]]++; reghisto[bytes[5]]++; reghisto[bytes[6]]++; reghisto[bytes[7]]++; } word++; } } /*辅助函数 sigma 定义于 *“HyperLogLog 草图的新基数估计算法” *奥特马尔·埃特尔,arXiv:1702.01284*/ double hllSigma(double x) { if (x == 1.) return INFINITY; double zPrime; double y = 1; double z = x; do { x *= x; zPrime = z; z += x * y; y += y; } while (zPrime != z); return z; } /*辅助函数 tau 定义于 *“HyperLogLog 草图的新基数估计算法” *奥特马尔·埃特尔,arXiv:1702.01284*/ double hllTau(double x) { if (x == 0. || x == 1.) return 0.; double zPrime; double y = 1.0; double z = 1 - x; do { x = sqrt(x); zPrime = z; y *= 0.5; z -= pow(1 - x, 2) * y; } while (zPrime != z); return z / 3; } /*根据谐波返回集合的近似基数 *寄存器值的平均值。 “hdr”指向 SDS 的开头 *表示保存 HLL 表示的 String 对象。 * *如果 HLL 对象的稀疏表示无效,则整数 *'invalid' 指向的值设置为非零,否则保持不变。 * *hllCount() 支持 HLL_RAW 的特殊内部编码,即 *是,hdr->registers 将指向 HLL_REGISTERS 元素的 uint8_t 数组。 *这对于在针对多个调用时加速 PFCOUNT 很有用 *键(无需使用 6 位整数编码)。*/ uint64_t hllCount(struct hllhdr *hdr, int *invalid) { double m = HLL_REGISTERS; double E; int j; /* Note that reghisto size could be just HLL_Q+2, because HLL_Q+1 is * the maximum frequency of the "000...1" sequence the hash function is * able to return. However it is slow to check for sanity of the * input: instead we history array at a safe size: overflows will * just write data to wrong, but correctly allocated, places. */ int reghisto[64] = {0}; /* Compute register histogram */ if (hdr->encoding == HLL_DENSE) { hllDenseRegHisto(hdr->registers, reghisto); } else if (hdr->encoding == HLL_SPARSE) { hllSparseRegHisto(hdr->registers, sdslen((sds)hdr) - HLL_HDR_SIZE, invalid, reghisto); } else if (hdr->encoding == HLL_RAW) { hllRawRegHisto(hdr->registers, reghisto); } else { serverPanic("Unknown HyperLogLog encoding in hllCount()"); } /* Estimate cardinality from register histogram. See: * "New cardinality estimation algorithms for HyperLogLog sketches" * Otmar Ertl, arXiv:1702.01284 */ double z = m * hllTau((m - reghisto[HLL_Q + 1]) / (double)m); for (j = HLL_Q; j >= 1; --j) { z += reghisto[j]; z *= 0.5; } z += m * hllSigma(reghisto[0] / (double)m); E = llroundl(HLL_ALPHA_INF * m * m / z); return (uint64_t)E; } /* Call hllDenseAdd() or hllSparseAdd() according to the HLL encoding. */ int hllAdd(robj *o, unsigned char *ele, size_t elesize) { struct hllhdr *hdr = o->ptr; switch (hdr->encoding) { case HLL_DENSE: return hllDenseAdd(hdr->registers, ele, elesize); case HLL_SPARSE: return hllSparseAdd(o, ele, elesize); default: return -1; /* Invalid representation. */ } } /*通过计算 MAX(registers[i],hll[i]) 合并 HyperLogLog 'hll' *具有由“max”指向的 uint8_t HLL_REGISTERS 寄存器数组。 * *hll 对象必须已经通过 isHLLObjectOrReply() 进行验证 *或以其他方式。 * *如果HyperLogLog稀疏,发现无效,C_ERR 返回 *,否则函数始终成功。*/ int hllMerge(uint8_t *max, robj *hll) { struct hllhdr *hdr = hll->ptr; int i; if (hdr->encoding == HLL_DENSE) { uint8_t val; for (i = 0; i < HLL_REGISTERS; i++) { HLL_DENSE_GET_REGISTER(val, hdr->registers, i); if (val > max[i]) max[i] = val; } } else { uint8_t *p = hll->ptr, *end = p + sdslen(hll->ptr); long runlen, regval; p += HLL_HDR_SIZE; i = 0; while (p < end) { if (HLL_SPARSE_IS_ZERO(p)) { runlen = HLL_SPARSE_ZERO_LEN(p); i += runlen; p++; } else if (HLL_SPARSE_IS_XZERO(p)) { runlen = HLL_SPARSE_XZERO_LEN(p); i += runlen; p += 2; } else { runlen = HLL_SPARSE_VAL_LEN(p); regval = HLL_SPARSE_VAL_VALUE(p); if ((runlen + i) > HLL_REGISTERS) break; /* Overflow. */ while (runlen--) { if (regval > max[i]) max[i] = regval; i++; } p++; } } if (i != HLL_REGISTERS) return C_ERR; } return C_OK; } /*============================ HyperLogLog 命令 ====================== ====== */ /*创建一个 HLL 对象。我们始终使用稀疏编码创建 HLL。 *这将根据需要升级为密集表示。*/ robj *createHLLObject(void) { robj *o; struct hllhdr *hdr; sds s; uint8_t *p; int sparselen = HLL_HDR_SIZE + (((HLL_REGISTERS + (HLL_SPARSE_XZERO_MAX_LEN - 1)) / HLL_SPARSE_XZERO_MAX_LEN) * 2); int aux; /* Populate the sparse representation with as many XZERO opcodes as * needed to represent all the registers. */ aux = HLL_REGISTERS; s = sdsnewlen(NULL, sparselen); p = (uint8_t *)s + HLL_HDR_SIZE; while (aux) { int xzero = HLL_SPARSE_XZERO_MAX_LEN; if (xzero > aux) xzero = aux; HLL_SPARSE_XZERO_SET(p, xzero); p += 2; aux -= xzero; } serverAssert((p - (uint8_t *)s) == sparselen); /* Create the actual object. */ o = createObject(OBJ_STRING, s); hdr = o->ptr; memcpy(hdr->magic, "HYLL", 4); hdr->encoding = HLL_SPARSE; return o; } /* Check if the object is a String with a valid HLL representation. * Return C_OK if this is true, otherwise reply to the client * with an error and return C_ERR. */ int isHLLObjectOrReply(client *c, robj *o) { struct hllhdr *hdr; /* Key exists, check type */ if (checkType(c, o, OBJ_STRING)) return C_ERR; /* Error already sent. */ if (!sdsEncodedObject(o)) goto invalid; if (stringObjectLen(o) < sizeof(*hdr)) goto invalid; hdr = o->ptr; /* Magic should be "HYLL". */ if (hdr->magic[0] != 'H' || hdr->magic[1] != 'Y' || hdr->magic[2] != 'L' || hdr->magic[3] != 'L') goto invalid; if (hdr->encoding > HLL_MAX_ENCODING) goto invalid; /* Dense representation string length should match exactly. */ if (hdr->encoding == HLL_DENSE && stringObjectLen(o) != HLL_DENSE_SIZE) goto invalid; /* All tests passed. */ return C_OK; invalid: addReplyError(c, "-WRONGTYPE Key is not a valid " "HyperLogLog string value."); return C_ERR; } /* PFADD var ele ele ele ... ele => :0 or :1 */ void pfaddCommand(client *c) { robj *o = lookupKeyWrite(c->db, c->argv[1]); struct hllhdr *hdr; int updated = 0, j; if (o == NULL) { /*使用精确长度的字符串值创建键 *保存我们的 HLL 数据结构。 sdsnewlen() 当传递 NULL 时 *保证返回初始化为零的字节。*/ o = createHLLObject(); dbAdd(c->db, c->argv[1], o); updated++; } else { if (isHLLObjectOrReply(c, o) != C_OK) return; o = dbUnshareStringValue(c->db, c->argv[1], o); } /* Perform the low level ADD operation for every element. */ for (j = 2; j < c->argc; j++) { int retval = hllAdd(o, (unsigned char *)c->argv[j]->ptr, sdslen(c->argv[j]->ptr)); switch (retval) { case 1: updated++; break; case -1: addReplyError(c, invalid_hll_err); return; } } hdr = o->ptr; if (updated) { HLL_INVALIDATE_CACHE(hdr); signalModifiedKey(c, c->db, c->argv[1]); notifyKeyspaceEvent(NOTIFY_STRING, "pfadd", c->argv[1], c->db->id); server.dirty += updated; } addReply(c, updated ? shared.cone : shared.czero); } /* PFCOUNT var -> approximated cardinality of set. */ void pfcountCommand(client *c) { robj *o; struct hllhdr *hdr; uint64_t card; /*情况 1:多键键,并集基数。 * *当指定多个key时,PFCOUNT实际计算 *指定的 N 个 HLL 的合并基数。*/ if (c->argc > 2) { uint8_t max[HLL_HDR_SIZE + HLL_REGISTERS], *registers; int j; /* Compute an HLL with M[i] = MAX(M[i]_j). */ memset(max, 0, sizeof(max)); hdr = (struct hllhdr *)max; hdr->encoding = HLL_RAW; /* Special internal-only encoding. */ registers = max + HLL_HDR_SIZE; for (j = 1; j < c->argc; j++) { /* Check type and size. */ robj *o = lookupKeyRead(c->db, c->argv[j]); if (o == NULL) continue; /* Assume empty HLL for non existing var.*/ if (isHLLObjectOrReply(c, o) != C_OK) return; /* Merge with this HLL with our 'max' HLL by setting max[i] * to MAX(max[i],hll[i]). */ if (hllMerge(registers, o) == C_ERR) { addReplyError(c, invalid_hll_err); return; } } /* Compute cardinality of the resulting set. */ addReplyLongLong(c, hllCount(hdr, NULL)); return; } /*情况 2:单个 HLL 的基数。 * *用户指定了一个键。要么返回缓存的值 *或计算一个并更新缓存。 * *由于 HLL 是常规 Redis 字符串类型值,因此更新缓存不会 *修改数值。无论如何,我们都会执行lookupKeyRead,因为这被标记为 *只读命令。不同之处在于,使用lookupKeyWrite,a *副本上逻辑过期的键被删除,同时使用lookupKeyRead *不是,但如果键在逻辑上是这样的,则查找无论如何都会返回 NULL *过期了,这才是重要的。*/ o = lookupKeyRead(c->db, c->argv[1]); if (o == NULL) { /* No key? Cardinality is zero since no element was added, otherwise * we would have a key as HLLADD creates it as a side effect. */ addReply(c, shared.czero); } else { if (isHLLObjectOrReply(c, o) != C_OK) return; o = dbUnshareStringValue(c->db, c->argv[1], o); /* Check if the cached cardinality is valid. */ hdr = o->ptr; if (HLL_VALID_CACHE(hdr)) { /* Just return the cached value. */ card = (uint64_t)hdr->card[0]; card |= (uint64_t)hdr->card[1] << 8; card |= (uint64_t)hdr->card[2] << 16; card |= (uint64_t)hdr->card[3] << 24; card |= (uint64_t)hdr->card[4] << 32; card |= (uint64_t)hdr->card[5] << 40; card |= (uint64_t)hdr->card[6] << 48; card |= (uint64_t)hdr->card[7] << 56; } else { int invalid = 0; /* Recompute it and update the cached value. */ card = hllCount(hdr, &invalid); if (invalid) { addReplyError(c, invalid_hll_err); return; } hdr->card[0] = card & 0xff; hdr->card[1] = (card >> 8) & 0xff; hdr->card[2] = (card >> 16) & 0xff; hdr->card[3] = (card >> 24) & 0xff; hdr->card[4] = (card >> 32) & 0xff; hdr->card[5] = (card >> 40) & 0xff; hdr->card[6] = (card >> 48) & 0xff; hdr->card[7] = (card >> 56) & 0xff; /* This is considered a read-only command even if the cached value * may be modified and given that the HLL is a Redis string * we need to propagate the change. */ signalModifiedKey(c, c->db, c->argv[1]); server.dirty++; } addReplyLongLong(c, card); } } /* PFMERGE dest src1 src2 src3 ... srcN => OK */ void pfmergeCommand(client *c) { uint8_t max[HLL_REGISTERS]; struct hllhdr *hdr; int j; int use_dense = 0; /* Use dense representation as target? */ /* Compute an HLL with M[i] = MAX(M[i]_j). * We store the maximum into the max array of registers. We'll write * it to the target variable later. */ memset(max, 0, sizeof(max)); for (j = 1; j < c->argc; j++) { /* Check type and size. */ robj *o = lookupKeyRead(c->db, c->argv[j]); if (o == NULL) continue; /* Assume empty HLL for non existing var. */ if (isHLLObjectOrReply(c, o) != C_OK) return; /* If at least one involved HLL is dense, use the dense representation * as target ASAP to save time and avoid the conversion step. */ hdr = o->ptr; if (hdr->encoding == HLL_DENSE) use_dense = 1; /* Merge with this HLL with our 'max' HLL by setting max[i] * to MAX(max[i],hll[i]). */ if (hllMerge(max, o) == C_ERR) { addReplyError(c, invalid_hll_err); return; } } /* Create / unshare the destination key's value if needed. */ robj *o = lookupKeyWrite(c->db, c->argv[1]); if (o == NULL) { /* Create the key with a string value of the exact length to * hold our HLL data structure. sdsnewlen() when NULL is passed * is guaranteed to return bytes initialized to zero. */ o = createHLLObject(); dbAdd(c->db, c->argv[1], o); } else { /* If key exists we are sure it's of the right type/size * since we checked when merging the different HLLs, so we * don't check again. */ o = dbUnshareStringValue(c->db, c->argv[1], o); } /* Convert the destination object to dense representation if at least * one of the inputs was dense. */ if (use_dense && hllSparseToDense(o) == C_ERR) { addReplyError(c, invalid_hll_err); return; } /* Write the resulting HLL to the destination HLL registers and * invalidate the cached value. */ for (j = 0; j < HLL_REGISTERS; j++) { if (max[j] == 0) continue; hdr = o->ptr; switch (hdr->encoding) { case HLL_DENSE: hllDenseSet(hdr->registers, j, max[j]); break; case HLL_SPARSE: hllSparseSet(o, j, max[j]); break; } } hdr = o->ptr; /* o->ptr may be different now, as a side effect of last hllSparseSet() call. */ HLL_INVALIDATE_CACHE(hdr); signalModifiedKey(c, c->db, c->argv[1]); /* We generate a PFADD event for PFMERGE for semantical simplicity * since in theory this is a mass-add of elements. */ notifyKeyspaceEvent(NOTIFY_STRING, "pfadd", c->argv[1], c->db->id); server.dirty++; addReply(c, shared.ok); } /*============================ 测试/调试 =================== ======= */ /*自我测试 *该命令执行 HLL 寄存器实现的自检。 *从外部不容易测试的东西。*/ #define HLL_TEST_CYCLES 1000 void pfselftestCommand(client *c) { unsigned int j, i; sds bitcounters = sdsnewlen(NULL, HLL_DENSE_SIZE); struct hllhdr *hdr = (struct hllhdr *)bitcounters, *hdr2; robj *o = NULL; uint8_t bytecounters[HLL_REGISTERS]; /*测试 1:访问寄存器。 *该测试旨在测试我们数据的不同计数器 *结构是可访问的并且设置它们的值都会导致 *正确的值被保留并且不影响相邻的值。*/ for (j = 0; j < HLL_TEST_CYCLES; j++) { /* Set the HLL counters and an array of unsigned byes of the * same size to the same set of random values. */ for (i = 0; i < HLL_REGISTERS; i++) { unsigned int r = rand() & HLL_REGISTER_MAX; bytecounters[i] = r; HLL_DENSE_SET_REGISTER(hdr->registers, i, r); } /* Check that we are able to retrieve the same values. */ for (i = 0; i < HLL_REGISTERS; i++) { unsigned int val; HLL_DENSE_GET_REGISTER(val, hdr->registers, i); if (val != bytecounters[i]) { addReplyErrorFormat(c, "TESTFAILED Register %d should be %d but is %d", i, (int)bytecounters[i], (int)val); goto cleanup; } } } /*测试 2:近似误差。 *测试添加独特元素并检查估计值 *始终是合理的界限。 * *我们检查误差比预期小几倍 *标准错误,使测试不太可能失败,因为 *“糟糕”的运行。 * *测试同时使用密集和稀疏 HLL 进行 *时间还验证计算的基数是否相同。*/ memset(hdr->registers, 0, HLL_DENSE_SIZE - HLL_HDR_SIZE); o = createHLLObject(); double relerr = 1.04 / sqrt(HLL_REGISTERS); int64_t checkpoint = 1; uint64_t seed = (uint64_t)rand() | (uint64_t)rand() << 32; uint64_t ele; for (j = 1; j <= 10000000; j++) { ele = j ^ seed; hllDenseAdd(hdr->registers, (unsigned char *)&ele, sizeof(ele)); hllAdd(o, (unsigned char *)&ele, sizeof(ele)); /* Make sure that for small cardinalities we use sparse * encoding. */ if (j == checkpoint && j < server.hll_sparse_max_bytes / 2) { hdr2 = o->ptr; if (hdr2->encoding != HLL_SPARSE) { addReplyError(c, "TESTFAILED sparse encoding not used"); goto cleanup; } } /* Check that dense and sparse representations agree. */ if (j == checkpoint && hllCount(hdr, NULL) != hllCount(o->ptr, NULL)) { addReplyError(c, "TESTFAILED dense/sparse disagree"); goto cleanup; } /* Check error. */ if (j == checkpoint) { int64_t abserr = checkpoint - (int64_t)hllCount(hdr, NULL); uint64_t maxerr = ceil(relerr * 6 * checkpoint); /* Adjust the max error we expect for cardinality 10 * since from time to time it is statistically likely to get * much higher error due to collision, resulting into a false * positive. */ if (j == 10) maxerr = 1; if (abserr < 0) abserr = -abserr; if (abserr > (int64_t)maxerr) { addReplyErrorFormat(c, "TESTFAILED Too big error. card:%llu abserr:%llu", (unsigned long long)checkpoint, (unsigned long long)abserr); goto cleanup; } checkpoint *= 10; } } /* Success! */ addReply(c, shared.ok); cleanup: sdsfree(bitcounters); if (o) decrRefCount(o); } /* Different debugging related operations about the HLL implementation. * * PFDEBUG GETREG <key> * PFDEBUG DECODE <key> * PFDEBUG ENCODING <key> * PFDEBUG TODENSE <key> */ void pfdebugCommand(client *c) { char *cmd = c->argv[1]->ptr; struct hllhdr *hdr; robj *o; int j; o = lookupKeyWrite(c->db, c->argv[2]); if (o == NULL) { addReplyError(c, "The specified key does not exist"); return; } if (isHLLObjectOrReply(c, o) != C_OK) return; o = dbUnshareStringValue(c->db, c->argv[2], o); hdr = o->ptr; /* PFDEBUG GETREG <key> */ if (!strcasecmp(cmd, "getreg")) { if (c->argc != 3) goto arityerr; if (hdr->encoding == HLL_SPARSE) { if (hllSparseToDense(o) == C_ERR) { addReplyError(c, invalid_hll_err); return; } server.dirty++; /* Force propagation on encoding change. */ } hdr = o->ptr; addReplyArrayLen(c, HLL_REGISTERS); for (j = 0; j < HLL_REGISTERS; j++) { uint8_t val; HLL_DENSE_GET_REGISTER(val, hdr->registers, j); addReplyLongLong(c, val); } } /* PFDEBUG DECODE <key> */ else if (!strcasecmp(cmd, "decode")) { if (c->argc != 3) goto arityerr; uint8_t *p = o->ptr, *end = p + sdslen(o->ptr); sds decoded = sdsempty(); if (hdr->encoding != HLL_SPARSE) { sdsfree(decoded); addReplyError(c, "HLL encoding is not sparse"); return; } p += HLL_HDR_SIZE; while (p < end) { int runlen, regval; if (HLL_SPARSE_IS_ZERO(p)) { runlen = HLL_SPARSE_ZERO_LEN(p); p++; decoded = sdscatprintf(decoded, "z:%d ", runlen); } else if (HLL_SPARSE_IS_XZERO(p)) { runlen = HLL_SPARSE_XZERO_LEN(p); p += 2; decoded = sdscatprintf(decoded, "Z:%d ", runlen); } else { runlen = HLL_SPARSE_VAL_LEN(p); regval = HLL_SPARSE_VAL_VALUE(p); p++; decoded = sdscatprintf(decoded, "v:%d,%d ", regval, runlen); } } decoded = sdstrim(decoded, " "); addReplyBulkCBuffer(c, decoded, sdslen(decoded)); sdsfree(decoded); } /* PFDEBUG ENCODING <key> */ else if (!strcasecmp(cmd, "encoding")) { char *encodingstr[2] = {"dense", "sparse"}; if (c->argc != 3) goto arityerr; addReplyStatus(c, encodingstr[hdr->encoding]); } /* PFDEBUG TODENSE <key> */ else if (!strcasecmp(cmd, "todense")) { int conv = 0; if (c->argc != 3) goto arityerr; if (hdr->encoding == HLL_SPARSE) { if (hllSparseToDense(o) == C_ERR) { addReplyError(c, invalid_hll_err); return; } conv = 1; server.dirty++; /* Force propagation on encoding change. */ } addReply(c, conv ? shared.cone : shared.czero); } else { addReplyErrorFormat(c, "Unknown PFDEBUG subcommand '%s'", cmd); } return; arityerr: addReplyErrorFormat(c, "Wrong number of arguments for the '%s' subcommand", cmd); }
