

1. 背景
Java服务 堆内存设置2G, 进程内存飙升到5G, 触发机器内存阈值告警💥, 问题排查过程中(求指导)
- 吃饭回来路上一看飞书消息,有一个内存超过机器的90%告警,刚开始没注意,同事给我发信息截图了我的一段代码 new Gson()(每次都是重新创建),可能猜想是不是我下午上线的代码有问题(因为最近只有我改了那个服务代码 重启上线了😭),我重启的那个服务内存占用对比另一台机器翻了一倍,想了想啊我一个new Gson() 能占用多大的内存,使用完等待下次ygc被扫描清扫,看业务上的QPS量又不高,排查了一晚上 硬是没看出具体是什么问题,分享一下排查的过程吧,jmap dump文件scp传输跳板机下载真慢 (10kb/s让它下载一个晚上吧/明天上班再看dump分析)。
2. 过程
2.1 top -c 查看服务进程占用内存比例和大小
- 服务JVM参数
java -jar -Xms512M -Xmx512M物流内存3.3g大小对比另外一台机器多了一倍

- VIRT:进程申请的虚拟内存总大小。
- RES:进程在读写它申请的虚拟内存页面后,会触发Linux的内存缺页中断,进而导致Linux为该页分配实际内存,即RSS,在top中叫RES。
- SHR:进程间共享的内存,如libc.so这个C动态库,几乎会被所有进程加载到各自的虚拟内存空间并使用,但Linux实际只分配了一份内存,各个进程只是通过内存页表关联到此内存而已,注意,RSS指标一般也包含SHR。
2.2 top -Hp 20051 查看具体线程详情 (啥也看不出来)
- 对这个线程观察内部资源使用情况,不同的线程数据都是一样的,这也看不出来什么差异。

2.3 free -g
- 内存使用超过90% 亚马逊那边的机器发送告警通知,真危险啊 再来一点用户量打进来 这机器基本撑不住,苦的只有开发😭。

2.4 jstat -gcutil pid 1000 查看实时GC详情
- 主要看FullGC次数和累计时间,YGC次数和累计时间,年轻代和老年代每个区域占用的内存情况.查看M的值为 99.38,即Meta区使用率达到了99.38%。
FUllGC 肯定是有问题的 我当时看的那几个小时 还增长了 也有可能是我dump文件触发的。


jinfo -flag MetaspaceSize pid 查看默认Meta空间大小 21MB
XX:MetaspaceSize=22020096

java -XX:+PrintFlagsFinal -version |grep MetaspaceSize JVM参数的默认值查看
size_t MaxMetaspaceSize = 18446744073709551615 {product} {default}
size_t MetaspaceSize = 22020096 {product} {default}
java version "17.0.6" 2023-01-17 LTS
Java(TM) SE Runtime Environment (build 17.0.6+9-LTS-190)
Java HotSpot(TM) 64-Bit Server VM (build 17.0.6+9-LTS-190, mixed mode, sharing)
2.5 jstat -gcmetacapacity 20051 2000 20
-
对元数据具体详情观察 214080KB


2.6 jstat -gcoldcapacity 20051 2000 20
- 对老年代具体详情观察

2.7 jstat -gcnewcapacity 20051 2000 20
- 对年轻代具体详情观察

2.8 jcmd 20051 GC.heap_info
- jcmd 查看 G1垃圾回收器堆内存占用情况,已使用168123K 大概就是160MB。元空间225551K 大概是220MB,class 占用27619k 大概是22MB,除了元空间有点大(是不是这里有问题啊 我们启动参数没有设置MaxMetaspaceSize参数 默认Meta空间大小21MB 元空间绝对有问题),其他看起来都没有问题。
jcmd 20051 GC.heap_info 20051: garbage-first heap total 524288K, used 168123K
[0x00000000e0000000, 0x0000000100000000) region size 1024K, 15 young (15360K), 2 survivors (2048K)
Metaspace used 225551K, committed 227008K, reserved 1253376K
class space used 27619K, committed 28352K, reserved 1048576K

2.9 jmap -histo 20051 | head -20
- jmap 查看大小排前20的class name 都是一些底层数据结构并且bytes的大小不是很大,看不到有效的信息,只能dump一个快照下来,用MAT工具看了。

2.10 jmap -dump:live,format=b,file=business.hprof 20051 下载dump快照
- 这里dump下来的是live 活跃的内存对象?
Dumping heap to /home/centos/xxxxx/business2.hprof ...
Heap dump file created [226547686 bytes in 1.521 secs]

2.11 日志搜索内存泄漏/内存溢出(没搜到)
以前内存溢出/泄漏 都能在内存里面找到,可能这次不是相关场景触发的吧
- grep "OutOfMemoryError" xxxxxx.log.2024-06-05
- grep "Java heap space" xxxxxx.log.2024-06-05
2.12 MAT 分析dump文件 (堆内存)


内存泄漏捕捉
- MAT 提供的三个内存泄漏加起来才50MB 这对于3.3G 完全不对应啊,单位是bytes 没问题呀。要不是这个dump快照有问题,要么就是内存泄漏不会被记录在dump文件里面,要不就是堆外内存了。
LaunchedURLClassLoader Spring 32MB
24 instances of **"io.netty.buffer.PoolChunk"**, loaded
by **"org.springframework.boot.loader.LaunchedURLClassLoader
@0xe0f527b8"**occupy **33,713,088 (26.45%)** bytes.

skywalking 12MB
15,290 instances of **"java.lang.Class"**, loaded by **"<system class loader>"** occupy **12,781,592 (10.03%)** bytes.
Biggest instances:
- class org.apache.skywalking.apm.dependencies.net.bytebuddy.dynamic.Nexus @ 0xe1106798 - 4,942,080 (3.88%) bytes.
**Keywords**
- java.lang.Class

Apollo 8MB

The classloader/component **"org.springframework.boot.loader.LaunchedURLClassLoader @ 0xe0f527b8"**occupies **12,748,728 (10.00%)** bytes. The memory is accumulated in one instance of **"java.lang.Object[]"** , loaded by **"<system class loader>"** , which occupies **9,009,152 (7.07%)** bytes.
Thread **"java.lang.Thread @ 0xe0ee0470 Apollo-ConfigServiceLocator-1"** has a local variable or reference to **"org.springframework.boot.loader.LaunchedURLClassLoader @ 0xe0f527b8"**which is on the shortest path to **"java.lang.Object[31618] @ 0xe5111b68"**. The thread **java.lang.Thread @ 0xe0ee0470 Apollo-ConfigServiceLocator-1** keeps local variables with total size **4,816 (0.00%)** bytes.
The stacktrace of this Thread is available. [See stacktrace](pages/24.html).
**Keywords**
- org.springframework.boot.loader.LaunchedURLClassLoader
- java.lang.Object[]
[Details »](pages/18.html)
2.13 Jprofiler 分析dump文件
- 没啥用,这个软件还是收费的,我换了一个邮箱免费试用了几天,多体验体验里面的功能吧。

2.14 jcmd pid VM.native_memory summary 查看堆外内存
Native memory tracking is not enabled 启动参数没加看不了
- java -XX:NativeMemoryTracking=summary -XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics -jar your-app.jar
2.15 pmap -x 14350 |sort -k 3 -n -r

3. 后续排查补充 (持续追踪问题)
2024 06/05 马上处理方式
解决方案: 先重启释放掉不可GC的内存,恢复内存正常状态,添加HeapDumpOnOutOfMemoryError参数 监控内存泄漏的dump文件,现场(dump/log)保留,继续分析问题触发的原因,持续监控该服务器在机器中的内存占用情况。
-
内存占用对比昨天少了一半,再观察一下内存使用变化吧。

- 一个服务xmx/xms设置的512mb 在机器上占用了3.3g(是另外一台机器的两倍) 日志中没有出现OOM关键字(java.lang.OutOfMemoryError: Java heap space), Full GC次数个位数 累计时间小于1s,Metadata元空间大小正常,native内存参数没加看不了(Native memory tracking is not enabled)。jmap dump下来的快照 内存占用120mb 正常 看不出来什么异常 不知道3.3g占用在哪里,难受 没有排查思路了,把昨天上的代码都重新看了一遍,基本都是新接口(客户端新版本还没有上线 当前线上用户调用不到,除了那个new Gson()的改动)。
- 猜想
- 有点像内存泄漏 导致那段时间一直堆积 GC回收不掉,后面恢复正常, 已经泄漏内存一直占着内存空间。(但是dump快照又找不到泄漏原因)
- 还有一个点猜测就是堆外内存占用(元数据空间/native)。
- 不知道是哪一块业务流量打到eu的第一台机器, QPS增加 触发了某个内存有问题的BUG(暂时没发现出来)。
- skywalking 日志收集 可能有影响。
- 查看M的值为99.38,即Meta区使用率达到了99.38%。metaspacesize=220MB,默认20MB, 扩容过程中发生FULLGC。
- 我们这边真的是 一点监控都没有,全靠硬命令去物理机上看,好想拥有一套Prometheus和Grafana监控啊。
- JVM知识点真的全都忘记了, 校招的时候看了很多,2年没有实践和复习, dump的文件是堆内存相关的,还有虚拟机栈/本地方法栈/方法区等等这些内存占用怎么排查也是一个问题。
- 在服务启动参数后面添加 -XX:+HeapDumpOnOutOfMemoryError, 在下次内存溢出的时候会自动产生对应的dump文件。
- 看新版IDEA自带dump文件分析工具 还能追踪到代码 有时间升级一下IDEA。
- 自己写一个堆外内存demo,学习排查问题流程。
2024/06/07( 排查记录 怀疑是堆外内存 netty那块的buffer +元空间 造成的)
- jhsdb jmap --heap --pid 709 命令使用
- 元空间大小设置 `-XX:MetaspaceSize`和`-XX:MaxMetaspaceSize`
- **jmap** -dump:live,format=b,file=business.hprof 709 (live 是不是只dump活跃的内存对象)
- jcmd 709 VM.metaspace 查看元空间
- 猜测堆外内存 netty iobuffer内存溢出 测试环境添加参数 `-XX:NativeMemoryTracking=detail` jcmd pid VM.native_memory detail
- pmap -x 709 |sort -k 3 -n -r 内存分布 有很多64MB内存块
- `jstack 709`查看线程栈
- jcmd 709 VM.flags 查看JVM参数
jcmd 709 VM.flags
709:
-XX:CICompilerCount=3 -XX:CompressedClassSpaceSize=218103808
-XX:ConcGCThreads=1 -XX:G1ConcRefinementThreads=4
-XX:G1EagerReclaimRemSetThreshold=8 -XX:G1HeapRegionSize=1048576
-XX:GCDrainStackTargetSize=64 -XX:InitialHeapSize=2147483648
-XX:MarkStackSize=4194304 -XX:MaxHeapSize=2147483648
-XX:MaxMetaspaceSize=268435456 -XX:MaxNewSize=1287651328
-XX:MetaspaceSize=268435456 -XX:MinHeapDeltaBytes=1048576
-XX:MinHeapSize=2147483648 -XX:NativeMemoryTracking=summary
-XX:NonNMethodCodeHeapSize=5832780 -XX:NonProfiledCodeHeapSize=122912730
-XX:ProfiledCodeHeapSize=122912730 -XX:ReservedCodeCacheSize=251658240
-XX:+SegmentedCodeCache -XX:SoftMaxHeapSize=2147483648
-XX:+UseCompressedClassPointers -XX:+UseCompressedOops -XX:+UseG1GC
真是无语死了 测试环境机器添加了 -XX:NativeMemoryTracking=summary /detail 再去访问native_memory还是没开启 我没错啊

换个项目还是不行 JDK17是不支持吗?

java -XX:NativeMemoryTracking=detail -jar 调整参数在 -jar的前面生效了 这什么原理真奇怪(有时间补下这个知识点)


- 测试环境内存分析 (xms初始堆的大小直接分配两个g 物理机器直接占用两个g吗?) -Xms2048M -Xmx2048M -XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M
- 2.5个g,堆内内存Java Heap(2g 初始内存申请 正常)还剩50w kb 其他加起来正好、Class区域(2w kb正常)、Code区域(4w kb正常)、Metaspace(18wkb=180MB正常), Thread(1.5w 正常)、GC(12w kb正常)、Symbol(4w kb正常)、Other (6w kb正常)、
-XX:MetaspaceSize=256M -XX:MaxMetaspaceSize=256M 元空间大小调整 heap_info reserved也改变了。
jcmd 709 GC.heap_info
709:
garbage-first heap total 2097152K, used 877701K [0x0000000080000000, 0x0000000100000000)
region size 1024K, 759 young (777216K), 75 survivors (76800K)
Metaspace used 229668K, committed 231232K, reserved 417792K
class space used 28260K, committed 29056K, reserved 212992K
- 下一步就是给线上加上 -XX:NativeMemoryTracking=detail 参数 继续监控
2024/06/12 排查记录
- 线上加上NativeMemory参数追踪 当进程内存达到3.8g时进行分析。
- jcmd 1671 VM.native_memory detail
- 发现命令显示的committed=2875139KB(2.7g)的内存小于物理内存3.8g(top -c/pmap查看到的),jcmd能看到
堆内存/code/class/元空间/DirectByteBuffer,看不到堆外内存,还有1.1内存跑哪里去了,线索又断了,打算用gperftools工具去看下进程内存是否泄漏。
2024/06/21-06/24 两台机器数据总结 排查记录
去掉skywalking 现象 开NMT
- 周五 business cn第一台 把skywalking关了 加上NMT参数监控,一直保持在内存1.2g左右,jcmd native_memory占用1g 还有200mb 知道内存地址0000561b05bf0000 ,不在jcmd内存映射地址里面, 现在还不知道是什么东西, jcmd 1g包括(512MB 堆内存+170MB 元空间+70MB GC+17MB Class文件+ 17MBNMT开启+20MB Thread), 数据看起来都是正常的
- 周一 通过pmap 内存比较 上涨 1271860-1245388= 26472kb (25MB) 数据正常
不去skywalking 现象 开NMT
-
周五是1.2g 到了周一上涨到1.5g 内存占用 通过pmap 1539536-1268736=270800 (上涨260MB),jcm 总共提交的内存是(1g) 1152483-1066854 =85629 (83MB) 260MB-83MB=180MB 都是一些00007xxxx的堆外内存块数据上涨。
-
相同服务 两台机器 内存占用不一致 (可能是数据流量太小了 负载不均衡 体现不出来差异)
-
和其他服务一样 项目xmx大小一样的服务内存占用基本都是一样的 说明堆外内存申请可能是公共的组件导致的
-
流量进来的越多的机器,占用的RES 内存越高(比如最近两天 mall服务第一台机器有流量进来2.1g 内存占用/ 第二台只有一点流量进来1.7g 内存占用)
测试环境找内存地址里面对应的数据
-
通过pmap找到内存地址,通过gdb将内存dump出来,再通过string转换为可读,看下里面是什么内容 看下是哪块代码分配的内存
- (gdb) dump binary memory memory_dump2.bin 0x00007f1130000000 0x00007f1130000000 + 65536
- strings memory_dump2.bin (堆内存正常显示/堆外内存乱码)
- gdb -batch -pid=15171 -ex "call malloc_trim()"
-
通过strace命令 追踪下是哪块代码调用的malloc方法
- strace -e trace=mmap,munmap,brk -p 32448
-
gperftools 安装失败
-
arthas 看到的都是堆内存相关的
-
valgrind 用不来
- (valgrind --tool=memcheck --leak-check=full java -jar)
2024/07/05 排查记录
这些是怀疑grpc-java或者netty 出现堆外溢出问题了的记录
-verbose:class 查看类加载情况
-verbose:gc 查看虚拟机中内存回收情况
-verbose:jni 查看本地方法调用的情况
- pmap -x 28235 |sort -k 3 -n -r
- jcmd 28235 VM.native_memory detail scale=MB
- jstat -gcutil 28235 1000 10
jhsdb jmap --heap --pid 18400
jmap -clstats 18400
jstat -gcutil 18400 1000 10
pmap -x 18400 |sort -k 3 -n -r
jcmd 18400 VM.native_memory detail scale=MB
jstat -gcmetacapacity 18400 2000 20
jcmd 18400 GC.heap_info
jcmd 18400 VM.flags
jcmd 18400 VM.metaspace
jmap -dump:live,format=b,file=business.hprof 20051
- 上次CN环境去掉skywalking 跑了三天的数据量(周一被重启了) business 一台是1.5g 一台是1.2g 相差300MB 区别不大 。后面使用gdb dump去看内存地址块里面是什么(什么都有 很杂 看不出来什么) 现在主要怀疑在netty/grpc-java这里 grpc-spring使用的是2.14.0版本 内置java-grpc 1.51.0版本,有个issue 场景很像github.com/grpc/grpc-j… 找不到具体原因。
2024/07/15 排查记录 skywalking 已关闭 没有影响
- 每周有时间就看下这个问题 人都快崩溃了
- pmap 时,发现 java 进程分配了大量 64 MB 大小的内存块 。在Linux 中,glibc 对具有大量并发线程的程序进行了优化,通过避免竞争调高了程序运行速度。而提速是通过为每一个核来维护一个内存池达到的。
- JVM 等原生应用程序调用的 malloc、free 函数,实际是由基础 C 库 glibc 提供的,而 linux 系统则提供了 brk、mmap、munmap 这几个系统调用来分配虚拟内存,所以 libc 的 malloc、free 函数实际是基于这些系统调用实现的。
- 由于系统调用有一定的开销,为减小开销,glibc 实现了一个类似内存池的机制,在 free 函数调用时将内存块缓存起来不归还给 linux,直到缓存内存量到达一定条件才会实际执行归还内存的系统调用。
- 如果应用程序拥有很多的线程数量,并且执行程序的机器CPU核数也很多,那么通过分配 arena 这种方式占用的内存总量可能非常大。比如在CPU核数为8的机器上,每个 CPU-Core 至多可以分配一定数量的 arena,默认是 8 个,arena 占用的内存量会达到 8 * 8 * 64 MB = 4GB。
线上 cn-1 第一台 堆外内存堆积在一个块里面 因为 MALLOC_ARENA_MAX=1 内存块占用了大概一个1G的内存 一直没有释放 堆内存设置的是1G top 看到的rss是2.2g
这个1g的内存块 从上周四 到现在一直占用 他也不变化 都怀疑是缓存占用
- jcmd pid GC.run 手动FULL GC 都清除不掉这一个G占用的内存 它们都被glibc缓存起来了,并没有归还给操作系统。
通过jstack 去看 有很多内存地址前缀一致的线程id 我现在怀疑线程使用的内存 是机器的内存
gdp -pid pid进入GDB- dump memory mem.bin startAddress endAddress
- 使用
strings mem.bin查看 dump 的内容。
gdb dump 看过几段内存数据 太杂了 什么都有 区分不了
prometheus +grafana终于在自己的推动下 也是搭建起来了 太痛苦了 监控到的堆内存+堆外内存+直接内存 prometheus监控不到堆外内存很多地方比如thread+GC区域 它和arthas看到的内存情况是一样的 看不到NMT能监控到的一些地方

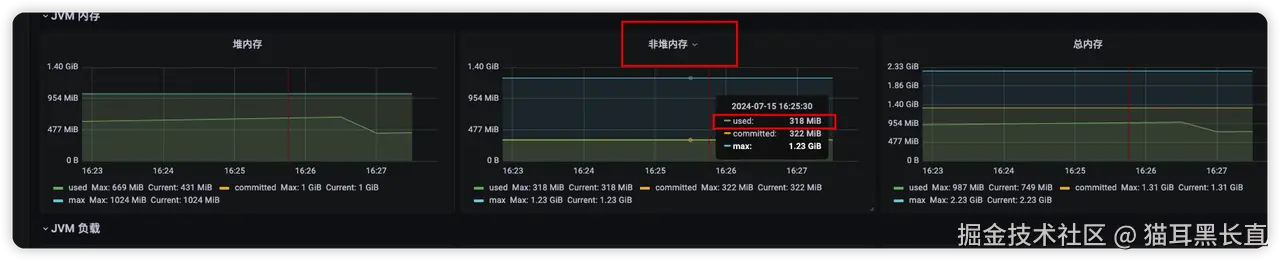
- Java堆,-Xmx选项限制的就是Java堆的大小,可通过jcmd命令观测。
- Java非堆,包含Metaspace、Code Cache、直接内存(DirectByteBuffer、MappedByteBuffer)、Thread、GC,它可通过arthas memory命令或NMT原生内存追踪观测。
- native分配内存,即直接调用malloc分配的,如JNI调用、磁盘与网络io操作等,可通过pmap命令、malloc_stats函数观测,或使用tcmalloc检测泄露点。
- glibc缓存的内存,即JVM调用free后,glibc库缓存下来未归还给操作系统的部分,可通过pmap命令、malloc_stats函数观测。
gdb命令暂时不敢尝试 线上机器 测试环境试了下
# 检查被glibc内存分配器缓存的内存
# 查看glibc内存分配情况,会输出到进程标准错误中
gdb -q -batch -ex 'call malloc_stats()' -p pid
# glibc 实现了 malloc_trim 函数,通过 brk 或 madvise 系统调用,归还被 glibc 缓存的内存,如下:
# 回收glibc缓存的内存
gdb -q -batch -ex 'call malloc_trim(0)' -p pid
- 有很多内存地址前缀一致的线程id 我现在怀疑线程栈使用的内存是机器的内存
- 面板里的 800MB+440M + 100多M 的线程 + glibc 缓存未归还的内存(gc 掉的内存不会真还给 os,而是被 glibc 缓存起来,因此 rss 不会降) + 其他七七八八非堆内存(symbolTable)之类的,加起来等于 2.2G
- 我的堆内存占0.8g, 2.2-0.8=1.4g 减去0.4g 。(还有1g glibc+NMT监控的+其他的 这里太多了 有点说服不了我)
线上 cn-2 第二台 默认的MALLOC_ARENA_MAX
接下来 线上两台机器再加上NMT监控参数 主要往线程栈/glibc/NMT一些非堆内存方向排查 缩小异常范围。
2024/07/16 加上NMT监控参数 排查记录
13993 work 20 0 4942992 2.8g 23580 S 1.0 9.0 5:22.11 java -XX:NativeMemoryTracking=detail -jar -Xms1024M -Xmx1024M /home/work/
jcmd 13993 VM.native_memory detail scale=MB
[work@bongmi-prod-srv01 log]$ jcmd 13993 VM.native_memory detail.diff scale=MB
13993:
Total: reserved=2932MB +107MB, committed=1591MB +99MB
- Java Heap (reserved=1024MB, committed=1024MB)
(mmap: reserved=1024MB, committed=1024MB)
- Class (reserved=1028MB +1MB, committed=28MB +4MB)
(classes #35404 +4197)
( instance classes #33912 +4018, array classes #1492 +179)
(malloc=4MB +1MB #80014 +21242)
(mmap: reserved=1024MB, committed=25MB +3MB)
: ( Metadata)
( reserved=176MB +24MB, committed=172MB +25MB)
( used=171MB +25MB)
( waste=1MB =0.44%)
: ( Class space)
( reserved=1024MB, committed=25MB +3MB)
( used=24MB +3MB)
( waste=1MB =3.24%)
- Thread (reserved=176MB +47MB, committed=17MB +5MB)
(thread #0)
(stack: reserved=176MB +47MB, committed=17MB +5MB)
- Code (reserved=247MB +2MB, committed=67MB +32MB)
(malloc=5MB +2MB #22745 +9566)
(mmap: reserved=242MB, committed=63MB +30MB)
- GC (reserved=91MB +1MB, committed=91MB +1MB)
(malloc=21MB +1MB #32904 +15284)
(mmap: reserved=70MB, committed=70MB)
- Compiler (reserved=1MB +1MB, committed=1MB +1MB)
(malloc=1MB +1MB #1842 +737)
- Internal (reserved=5MB, committed=5MB)
(malloc=5MB #31895 +12871)
- Other (reserved=114MB +25MB, committed=114MB +25MB)
(malloc=114MB +25MB #203 +86)
- Symbol (reserved=39MB +4MB, committed=39MB +4MB)
(malloc=37MB +3MB #928136 +85743)
(arena=2MB #1)
- Native Memory Tracking (reserved=18MB +3MB, committed=18MB +3MB)
(malloc=1MB #10449 +4954)
(tracking overhead=17MB +2MB)
- Shared class space (reserved=12MB, committed=12MB)
(mmap: reserved=12MB, committed=12MB)
- Arena Chunk (reserved=0MB -1MB, committed=0MB -1MB)
(malloc=0MB -1MB)
- Module (reserved=1MB, committed=1MB)
(malloc=1MB #4097 +1487)
- Metaspace (reserved=177MB +24MB, committed=173MB +26MB)
(malloc=1MB #988 +685)
(mmap: reserved=176MB +24MB, committed=172MB +25MB)
pmap -x 13993|sort -k 3 -n -r
[work@bongmi-prod-srv01 lollypop-v2-common-business-server]$ pmap -x 13993|sort -k 3 -n -r
total kB 4982060 2986860 2963116
00005584de921000 1771720 1771560 1771560 rw--- [ anon ]
00000000c0000000 1046528 788828 788828 rw--- [ anon ]
00007f9dd063c000 40192 40164 40164 rwx-- [ anon ]
00007f9dcd55d000 35844 34460 34460 rw--- [ anon ]
00007f9dae0e5000 28700 28700 28700 rw--- [ anon ]
00007f9dd8105000 26880 26864 26864 rwx-- [ anon ]
00007f9de766e000 17612 11672 4 r-x-- libjvm.so
0000000801980000 11072 11012 11012 rw--- [ anon ]
00007f9db66f0000 9212 8300 8300 rw--- [ anon ]
00007f9db8303000 9204 8284 8284 rw--- [ anon ]
00007f9da8f03000 9204 8280 8280 rw--- [ anon ]
00007f9db2f03000 9204 8216 8216 rw--- [ anon ]
00007f9daab03000 9204 8216 8216 rw--- [ anon ]
00007f9dba6ff000 9220 8200 8200 rw--- [ anon ]
00007f9db46ff000 9220 8200 8200 rw--- [ anon ]
00007f9dbc7ff000 8196 8196 8196 rw--- [ anon ]
00007f9dbe400000 8192 8192 8192 rw--- [ anon ]
00007f9dbb800000 8192 8192 8192 rw--- [ anon ]
00007f9dbb000000 8192 8192 8192 rw--- [ anon ]
00007f9db9400000 8192 8192 8192 rw--- [ anon ]
0000000800459000 7720 7512 0 r---- classes.jsa
00007f9dbdc00000 7168 7168 7168 rw--- [ anon ]
00007f9dbfd00000 6144 6144 6144 rw--- [ anon ]
00007f9dbee40000 5888 5888 5888 rw--- [ anon ]
00000008013c0000 5632 5632 5632 rw--- [ anon ]
00007f9dcf85e000 12532 5392 5392 rw--- [ anon ]
00007f9dbd303000 6132 5208 5208 rw--- [ anon ]
00007f9dc1e00000 5120 5120 5120 rw--- [ anon ]
0000000800f00000 4864 4864 4864 rw--- [ anon ]
00007f9db9f80000 4608 4608 4608 rw--- [ anon ]
- 找到证据了 是 glibc 在堆上用 brk 分配的内存, 这些内存既可能包括 jvm 堆内内存,也可能包括 jvm 堆外内存
- rss 2.8G,其中 1.7G 是 glibc brk 申请的,里面包含了大量缓存,剩下的 1.1G 是正在使用的堆内+堆外内存
- cat /proc/13993/maps | grep -Fv ".so" | grep " 0 "
- 重大发现 gdb -q -batch -ex 'call malloc_trim(0)' -p 13993 执行malloc_trim 清除内存池里面已经分配的内存,我擦 内存占用从1771560->180200 直接释放了1.6g给操作系统。结果确实是glibc缓存内存 对 rss 的影响。😄😄😄
- 问题确实在进一步发展 我下一步不知道干啥 我觉得还是代码写的有问题 或者第三方组件,还好提前把dump memory 下来了
dd if=/proc/13993/mem bs=$( getconf PAGESIZE ) iflag=skip_bytes,count_bytes \
skip=$(( 0x5584de921000 )) count=$(( 0x55854ab53000 - 0x5584de921000 )) of="13993_mem_5584de921000.bin"
2024/07/23-24 排查
内存dump 文件 细查
00007f04d4000000 19252 10112 10112 rw--- [ anon ]
00007f04e8000000 49068 9748 9748 rw--- [ anon ]
dump binary memory memory_dump_00007f04d4000000.bin 0x00007f04d4000000 0x00007f04d4000000 + 10395648
dump binary memory memory_dump_00007f04e8000000.bin 0x00007f04e8000000 0x00007f04e8000000 + 9981952
dump binary memory memory_dump_00007ff174000000.bin 0x00007ff174000000 0x00007ff174000000 + 67055616
dump binary memory memory_dump_00007ff114000000.bin 0x00007ff114000000 0x00007ff114000000 + 67031040
dump binary memory memory_dump_00007ff1cc000000.bin 0x00007ff1cc000000 0x00007ff1cc000000 + 66994176
tail -c +$((0x00007ff174000000+1)) /proc/1/mem|head -c $((40308*1024))|strings|less -S
tail -c +$((0x00007f59cc000000+1)) /proc/15015/mem|head -c $((131024*1024))|strings|less -S
tail -c +$((0x00007f59f0000000+1)) /proc/15015/mem|head -c $((65532*1024))|strings|less -S
tail -c +$((0x00007f67c8000000+1)) /proc/15242/mem|head -c $((65536*1024))|strings|less -S
tail -c +$((0x00007f6794000000+1)) /proc/15242/mem|head -c $((65536*1024))|strings|less -S
00007fa070000000 65520 65520 65520 rw--- [ anon ]
00007fa068000000 65520 65520 65520 rw--- [ anon ]
00007fa064000000 65520 65520 65520 rw--- [ anon ]
00007fa060000000 65520 65520 65520 rw--- [ anon ]
00007fa05c000000 65520 65520 65520 rw--- [ anon ]
00007fa058000000 65520 65520 65520 rw--- [ anon ]
00007fa054000000 65520 65520 65520 rw--- [ anon ]
00007fa050000000 65520 65520 65520 rw--- [ anon ]
00007fa04c000000 65520 65520 65520 rw--- [ anon ]
00007fa074000000 65512 65512 65512 rw--- [ anon ]
00007fa078000000 65508 65508 65508 rw--- [ anon ]
00007fa06c000000 65496 65496 65496 rw--- [ anon ]
00007fa12c000000 65480 65348 65348 rw--- [ anon ]
00007fa0d4000000 65520 64132 64132 rw--- [ anon ]
tail -c +$((0x00007fa070000000+1)) /proc/18812/mem|head -c $((65520*1024))|strings|less -S
dump binary memory memory_dump_0x00007fa068000000.bin 0x00007fa068000000 0x00007fa068000000 + 67092480
dump binary memory memory_dump_0x00007fa05c000000.bin 0x00007fa05c000000 0x00007fa05c000000 + 67092480
gdb -q -batch -ex 'info symbol 0x00007fb2a0000000' -p 30775
gdb -q -batch -ex 'call malloc_trim(0)' -p 13993
gdb -q -batch -ex 'call malloc_stats()' -p 1
64MB 内存块 在malloc 内存 free 没有释放给操作系统
疑点
-
Gson
-
Elasticsearch
-
redis
-
xml
工具
-
gperftools && tcmalloc
- linux下搭建gperftools工具分析程序瓶颈_linux gperftools-CSDN博客
- 【亲测可行】error while loading shared libraries的解决方案_error while loading shared libraries: libmpfr.so.6-C
- Malloc技术原理解析以及在转转搜索业务上的实践
-
export LD_PRELOAD=/usr/local/lib/libtcmalloc.so export HEAP_PROFILE_ALLOCATION_INTERVAL=2000000000 export HEAPPROFILE=/home/work/heap_gperf.log export LD_LIBRARY_PATH=/usr/local/lib:$LD_LIBRARY_PATH LD_PRELOAD=/usr/local/lib/libtcmalloc.so java -jar xxx-v2-common-xxx-server-1.0-SNAPSHOT.jar LD_PRELOAD=/usr/local/lib/libtcmalloc.so java -XX:NativeMemoryTracking=detail -XX:MetaspaceSize=256M -jar -Xms512M -Xmx512M /home/work/xxx/xxx-server-v2/xxx-v2-common-xxx-server/target/xxx-v2-common-xxx-server-1.0-SNAPSHOT.jar -Dapp.id=xxx -Dcom.alibaba.nacos.naming.log.level=warn 1>start.txt 2>&1 & LD_PRELOAD=/home/work/xxx/xxx-server-v2/xxx-v2-common-xxx-server/my_malloc.so java -XX:NativeMemoryTracking=detail -XX:MetaspaceSize=256M -jar -Xms512M -Xmx512M /home/work/xxx/xxx-server-v2/xxx-v2-common-xxx-server/target/xxx-v2-common-xxx-server-1.0-SNAPSHOT.jar -Dapp.id=xxx -Dcom.alibaba.nacos.naming.log.level=warn 1>start.txt 2>&1 &
-
Strace 监控brk mmap munmap 内存操作
-
strace -f -e "brk,mmap,munmap" -p 29467
printf “%x\n” 6743 进制转换
-
-
Jemalloc
-
cat /proc/15063/maps | grep -Fv ".so" 查看进程内存映射
7fa1d1ae9000-7fa1d1afa000 r-xp 00000000 08:01 1182674 /tmp/libnetty_transport_native_epoll_x86_6411597651169074894056.so (deleted) 7fa1d1afa000-7fa1d1cf9000 ---p 00011000 08:01 1182674 /tmp/libnetty_transport_native_epoll_x86_6411597651169074894056.so (deleted) 7fa1d1cf9000-7fa1d1cfc000 r--p 00010000 08:01 1182674 /tmp/libnetty_transport_native_epoll_x86_6411597651169074894056.so (deleted) 7fa1d063d000-7fa1d064e000 r-xp 00000000 08:01 1183705 /tmp/libio_grpc_netty_shaded_netty_transport_native_epoll_x86_6410656436253598093352.so (deleted) 7fa1d064e000-7fa1d084d000 ---p 00011000 08:01 1183705 /tmp/libio_grpc_netty_shaded_netty_transport_native_epoll_x86_6410656436253598093352.so (deleted) 7fa1d084d000-7fa1d084f000 r--p 00010000 08:01 1183705 /tmp/libio_grpc_netty_shaded_netty_transport_native_epoll_x86_6410656436253598093352.so (deleted) -
Gdb
-
dump 64MB内存块xxx.bin strings查看 都是乱码
-
gdb -q -batch -ex 'call malloc_stats()' -p pid gdb -q -batch -ex 'call malloc_trim(0)' -p pid ``` -
Valgrind C++程序检测 Java服务启动 失败 无效 nacos服务注册失败 测试不了
valgrind --tool=memcheck --leak-check=full --error-limit=no --log-file=/home/work/xxx/xxx-server-v2/xxx-v2-cbt-server/valgrind_report.log java -XX:NativeMemoryTracking=detail -jar -Xms128M -Xmx128M -XX:MetaspaceSize=128M xxx-v2-xxx-server-1.0-SNAPSHOT.jar -Dapp.id=xxx -Dcom.alibaba.nacos.naming.log.level=warn -
dmesg | grep -i kill | less 查看oom killer记录
[Thu Nov 30 23:25:56 2023] systemd-journal invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0 [Thu Nov 30 23:25:56 2023] [<ffffffff9af980c4>] oom_kill_process+0x254/0x3d0 [Thu Nov 30 23:25:56 2023] [<ffffffff9af97b6d>] ? oom_unkillable_task+0xcd/0x120 [Thu Nov 30 23:25:56 2023] Out of memory: Kill process 23843 (java) score 87 or sacrifice child [Thu Nov 30 23:25:56 2023] Killed process 23843 (java) total-vm:7116280kB, anon-rss:2033068kB, file-rss:0kB, shmem-rss:0kB [Tue Jun 25 17:40:23 2024] sa-async-task-3 invoked oom-killer: gfp_mask=0x201da, order=0, oom_score_adj=0 [Tue Jun 25 17:40:23 2024] [<ffffffff9af980c4>] oom_kill_process+0x254/0x3d0 [Tue Jun 25 17:40:23 2024] [<ffffffff9af97b6d>] ? oom_unkillable_task+0xcd/0x120 [Tue Jun 25 17:40:23 2024] Out of memory: Kill process 21483 (java) score 172 or sacrifice child
2024/07/24 排查记录 jemolloc 内存稳定
-
测试环境 安装jemolloc 替换默认的malloc 解决内存碎片回收异常场景
-
Jemalloc
Jemolloc 替换默认malloc能解决当前内存碎片问题
- Glibc 在内存回收方面做得不太好,常见的一个问题,申请很多内存,然后又释放,只是有一小块 没释放,这时候 Glibc 就必须要等待这一小块也释放了,也把整个大块释放,极端情况下, 可能会造成几个 G 的浪费。
- 因为 ptmalloc 收缩内存是从top chunk开始,如果与top chunk相邻的chunk不能释放,top chunk以下都不能释放
- 这其实不是内存泄露而是内存空洞的现象,在我们的系统资源捉襟见肘时候就比较致命.
- 但是我可能还是考虑到我们服务堆内/堆外 大量请求的时候,有一个峰值 导致内存频繁申请和释放,一个默认的库 很多地方都在用这个库, 我觉得还是业务代码有问题 扛不住测试api频繁请求 但是找不到证据。
- 如果服务能稳定xx.g,其实也无所谓,只需要确认的是,它不释放,做的缓存是不是真的有用(默认库既然有这个设计 缓存不释放 也是为了下一次申请 直接利用)。
wget https://github.com/jemalloc/jemalloc/releases/download/5.3.0/jemalloc-5.3.0.tar.bz2
yum install bzip2
tar -xvjf jemalloc-5.3.0.tar.bz2
cd jemalloc-5.3.0
./autogen.sh
make -j 6
make install
LD_PRELOAD=/usr/local/lib/libjemalloc.so java -jar xxxx.jar
使用jemalloc替换默认malloc内存管理器 稳定900MB状态。
内存排查思路流程 形成自己的方法论
-
首先结合异常信息看 promethues+grafana 面板,定位是不是堆内存的问题
-
如果是堆内存的问题 按照堆内存排查思路——后续补
-
如果是直接内存问题 DirectMemory 按照直接内存排查思路——后续补
-
如果不是堆内存也不是 直接内存DirectMemory 使用NMT分析堆外内存分配各项内存占用 按照NMT分析内存排查思路——后续补
-
如果不是堆内存和堆外内存原因 可以考虑看下是不是操作系统内存分配机制的问题 glibc默认是ptmalloc,你可以去了解下tcmalloc和jemalloc.
-
不知道有哪位掘友看看我的问题或者遇到过相同的问题,可以一起探讨交流一下 wx:hakusai22。😍
5. 参考
- 一次Java内存占用高的排查案例,解释了我对内存问题的所有疑问_java内存不断增加怎么排查-CSDN博客
- JVM 七. GC日志分析 与 内存泄漏 与 OOM案例_gc oom-CSDN博客
- 【转载】top命令详解-CSDN博客
- Linux 内存top命令详解_top命令显示内存信息-CSDN博客
- Linux查看jvm的GC情况_linux jvm cg-CSDN博客
- 一次Java内存占用高的排查案例,解释了我对内存问题的所有疑问
- 调试排错 - Java 内存分析之堆外内存
- 内存泄漏(memory leak)的理解与应用-CSDN博客
- jvm内存溢出排查(使用idea自带的内存泄漏分析工具)_idea分析hprof文件-CSDN博客
- MAT dump 软件下载地址 (记得换成cn源头 不然太慢了)
- Jprofiler 软件工具下载地址
- JAVA8 元空间使用查看 JVM 参数 MetaspaceSize 和 MaxMetaspaceSize 的讲解
- JVM Metaspace内存溢出排查与总结
- Jhsdb整合的故障处理工具
- Spring Boot引起的“堆外内存泄漏”排查及经验总结
- 全网最硬核 JVM 内存解析 - 1.从 Native Memory Tracking 说起
- JVM诊断命令jcmd介绍
- 一次 Java 进程 OOM 的排查分析(glibc 篇
- Java 进程内存占用及可观测性调研&内存异常排查最佳实践
- 被free回收的内存是立即返还给操作系统吗_free 回收-CSDN博客
- free()后内存不释放问题 - 内存缓冲池技术(转) - Dufe王彬 - 博客园
- 4.2 malloc 是如何分配内存的?
- 最全的JVM堆外内存排查思路 | HeapDump性能社区
- Centos7 perf、FlameGraph、perf-map-agent安装使用-CSDN博客
