HashMap
HashMap 的数据结构是 数组 + 链表/红黑树
HashMap 的put和get 方法
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
/**
* The maximum capacity, used if a higher value is implicitly specified
* by either of the constructors with arguments.
* MUST be a power of two <= 1<<30.
*/
static final int MAXIMUM_CAPACITY = 1 << 30;
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
/**
* The bin count threshold for using a tree rather than list for a
* bin. Bins are converted to trees when adding an element to a
* bin with at least this many nodes. The value must be greater
* than 2 and should be at least 8 to mesh with assumptions in
* tree removal about conversion back to plain bins upon
* shrinkage.
*/
static final int TREEIFY_THRESHOLD = 8;
/**
* The bin count threshold for untreeifying a (split) bin during a
* resize operation. Should be less than TREEIFY_THRESHOLD, and at
* most 6 to mesh with shrinkage detection under removal.
*/
static final int UNTREEIFY_THRESHOLD = 6;
/**
* The smallest table capacity for which bins may be treeified.
* (Otherwise the table is resized if too many nodes in a bin.)
* Should be at least 4 * TREEIFY_THRESHOLD to avoid conflicts
* between resizing and treeification thresholds.
*/
static final int MIN_TREEIFY_CAPACITY = 64;
/**
* Implements Map.put and related methods.
*
* @param hash hash for key
* @param key the key
* @param value the value to put
* @param onlyIfAbsent if true, don't change existing value
* @param evict if false, the table is in creation mode.
* @return previous value, or null if none
*/
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;
//hash 冲突
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode) // 是否是树结点
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {//是链表结点
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
/**
* Implements Map.get and related methods.
*
* @param key the key
* @return the node, or null if none
*/
final Node<K,V> getNode(Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n, hash; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & (hash = hash(key))]) != null) {
if (first.hash == hash && // always check first node
((k = first.key) == key || (key != null && key.equals(k))))
return first;
if ((e = first.next) != null) {
if (first instanceof TreeNode)
return ((TreeNode<K,V>)first).getTreeNode(hash, key);
do {
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
} while ((e = e.next) != null);
}
}
return null;
}
-
hash 冲突: 耗时
数组通过下标查找
假如 hash = 17 % 16 = 1 下标 index = 1;
假如 hash = 1 % 16 = 1 下标 index = 1;
所以就出现hash 冲突的情况, 就引入链表;
-
装载因子 DEFAULT_LOAD_FACTOR = 0.75f;
-
扩容 16 * 0.75 = 12 如果达到 12 个结点,就会扩容, 空间浪费
ArrayMap
两个数组来存储;key的hash数据,key-value组成的数组;
通过index来映射,2倍位置为key, 2倍位置+1 为value;
mHashes数据,是从小到大有序存储的;
get 时通过二分查找来获取 hash 所在的索引位置

在ArrayMap中的使用场景
- 数组不为空,clear清空数组时
- put时发现需要扩容,先 allocArrays 再 freeArrays
- ensureCapacity时,如果当前容量小于预期容量,则先 allocArrays 再 freeArrays
- remove时发现数组只有一个元素
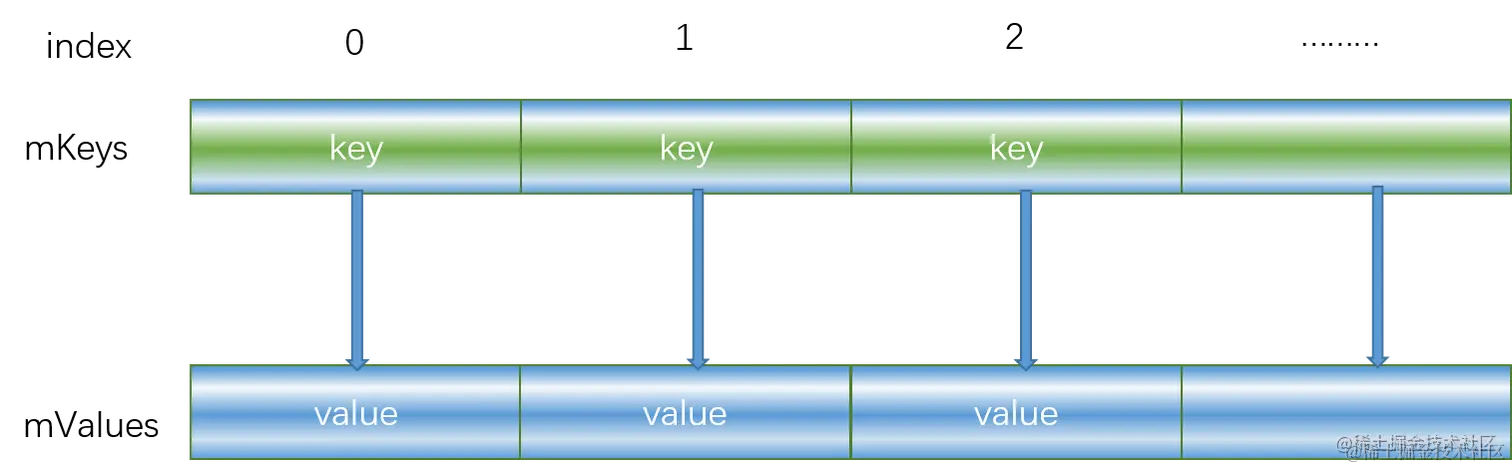
SparseArray
也是两个数组,存储数组索引的key,存储数据value,通过相等索引来映射;
mKeys是从小到大有序存储的
get 时通过二分查找来获取 hash 所在的索引位置
从图来看,我觉得是结构思想整体是一致的;但他们的实现思路还是存在不同的地方