一、算法描述
小华负责公司知识图谱产品,现在要通过新词挖掘完善知识图谱。
新词挖掘:给出一个待挖掘文本内容字符串Content和一个词的字符串word,找到content中所有word的新词。
新词:使用词word的字符串排列形成的字符串。
请帮小华实现新词挖掘,返回发现的新词的数量。
输入描述:第一行输入待挖掘的文本内容content;
第二行输入为词word;
输出描述:在content中找到的所有word的新词的数量。
补充说明:0 <= content的长度 <= 10000000;
1 <= word的长度 <= 2000
示例1
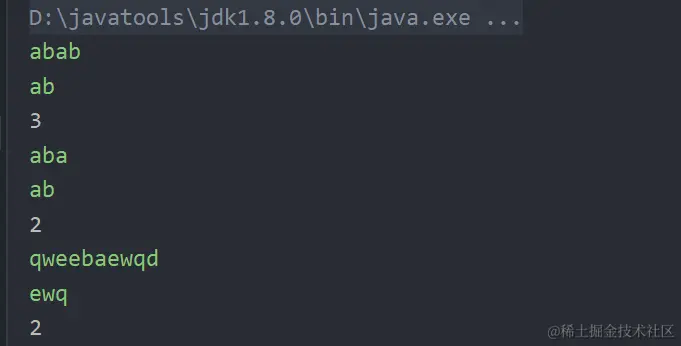
输入:
qweebaewqd
qwe
输出:2
说明:起始索引等于0的子串是"qwe",它是word的新词。
起始索引等于6的子串是"ewq",它是word的新词。
示例2
输入:
abab
ab
输出:3
说明:起始索引等于0的子串"ab",它是 word的新词.
起始索引等于1的子串"ba",它是 word的新词。
起始索引等于2的字串"ab",它是 word的新词
二、算法实现(Java)
public class NewWordFind {
public static void main(String[] args) {
Scanner scanner = new Scanner(System.in)
while (scanner.hasNextLine()) {
String content = scanner.nextLine()
String word = scanner.nextLine()
System.out.println(newWordFind(content, word))
}
}
public static int newWordFind(String content, String word) {
int left = 0, right = 0
int wordCount = word.length()
int total = 0
StringBuilder builder = new StringBuilder()
char[] wordArr = word.toCharArray()
Arrays.sort(wordArr)
while (right <= content.length() - 1) {
builder.append(content.charAt(right))
if (right - left + 1 == wordCount) { // 左右之间字符数等于目标word字符数
String sourceStr = builder.toString()
char[] strArr = sourceStr.toCharArray()
Arrays.sort(strArr)
if (Arrays.toString(strArr).equals(Arrays.toString(wordArr))) {
total++
}
// 左移指针时,删除最左边字符
List<Character> list = new ArrayList<>()
for (char c : sourceStr.toCharArray()) {
list.add(c)
}
list.remove(0)
// 将删除后的字符串重新放入builder,以便下次比较
builder = new StringBuilder()
list.forEach(builder::append)
left++
}
right++
}
return total
}
}
三、运行结果