

本期概要
欢迎来到第四期的双周精选!在2023的最后两周里,AutoMQ for Kafka和AutoMQ for RocketMQ项目依然在持续进展。
AutoMQ for Kafka: 实现了 Metrics 大盘和 Trace 集成,并进行了单机大规模分区关闭和异常关机恢复的性能优化.
AutoMQ for RocketMQ: 在 Remoting 协议可观测性和 Store 层队列状态机方面进行了完善和重构。这些更新将进一步提升 AutoMQ 在分布式消息队列领域的功能和性能,让我们一同探索这些令人振奋的发展!
AutoMQ for Kafka 主干动态
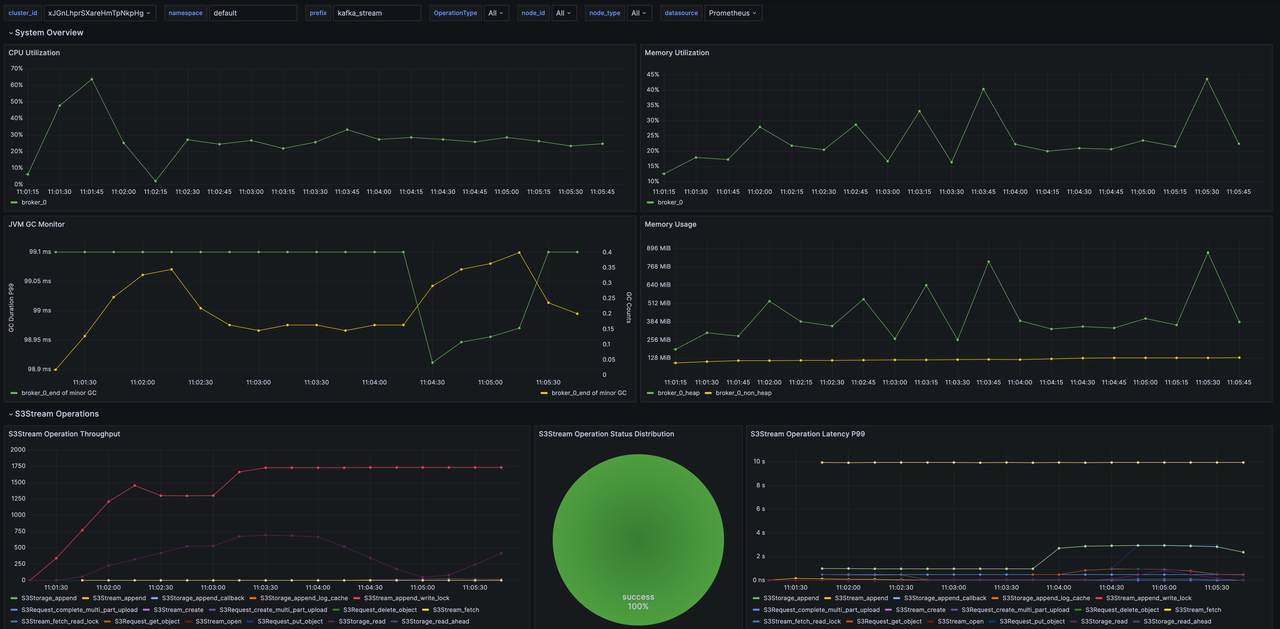
Metrics 大盘 & Trace 集成
新增 Prometheus、Grafana 一键拉起脚本,并自动导入 AutoMQ Kafka 大盘 github.com/AutoMQ/auto… 丰富存储层的 Metrics github.com/AutoMQ/auto… github.com/AutoMQ/auto…
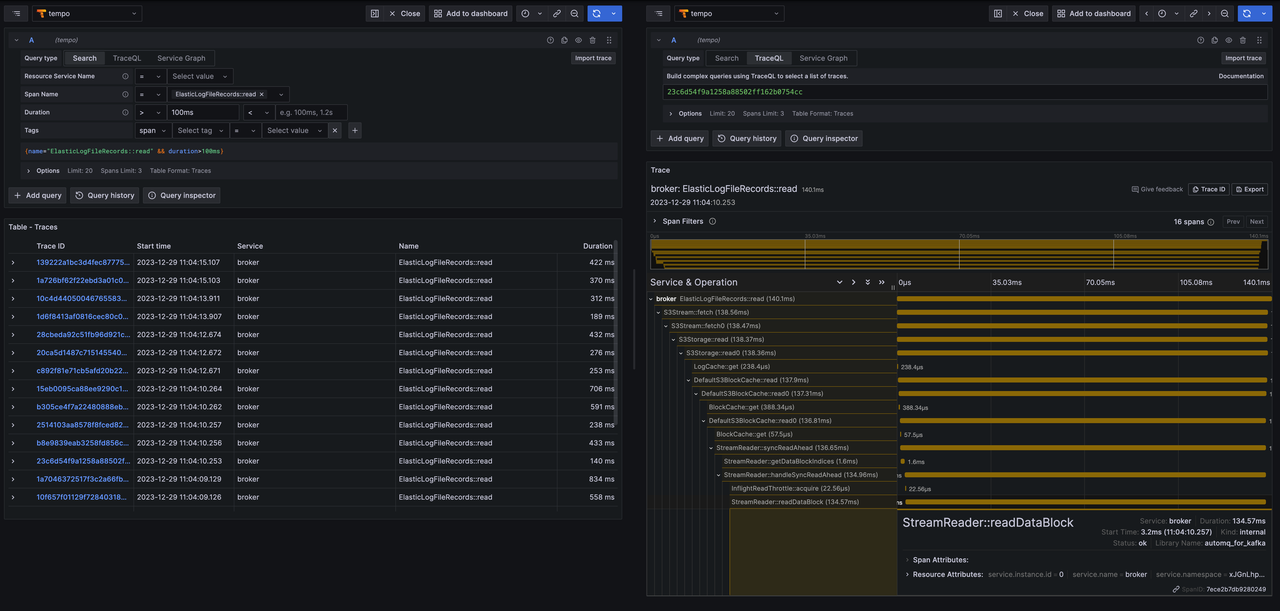
核心读写链路 Trace 支持 github.com/AutoMQ/auto… github.com/AutoMQ/auto…
单机大规模分区关闭加速
**分区并行化关闭优化:**从原来节点 shutdown 超时优化到 45s 完成 shutdown。 github.com/AutoMQ/auto… **Stream 关闭加速:**关闭过程中精细化等待上传 S3 的任务,整体 shutdown 耗时从 45s 优化到 17s。 github.com/AutoMQ/auto… 通过两项优化,最终 17s 即可完成 5000 分区关闭。
异常关机恢复加速
**800MiB 分区 unclean shutdown 恢复速度耗时从 19s 优化到 1.5s:**原版 Apache Kafka 在 unclean shutdown 后,分区恢复会将所有满足 segment.endOffset > recoverPoint 条件的 segments 都清除索引,并大量从磁盘中读取数据进行索引构建。恢复的数据较多导致恢复时间较长。 AutoMQ Kafka 优化了异常恢复流程,仅从 recoverPoint 开始恢复,并且辅以更加频繁的 checkpoint,将 unclean shutdown 单分区需要恢复的数据量限制在 50MiB 以内,提供可预期的 1.5s 的恢复耗时。 github.com/AutoMQ/auto…
集群10w Partition&200TB存储支持 PART1
优化大规模分区集群的 Kraft 元数据内存占用,元数据内存占用下降 80%,10w Partition & 200TB 的集群元数据内存占用预期为 120MiB。
github.com/AutoMQ/auto…
github.com/AutoMQ/auto…
AutoMQ for RocketMQ 主干动态
完善 Remoting 协议可观测性
补充生产消费的 Metrics 和 Trace github.com/AutoMQ/auto…
重构 Store 层队列状态机
以上是第四期《双周精选》的内容,欢迎关注我们的公众号,我们会定期更新 AutoMQ 社区的进展。同时,也诚邀各位开源爱好者持续关注我们社区,跟我们一起构建云原生消息中间件!
END
关于我们
AutoMQ 是一家专业的消息队列和流存储软件服务供应商。AutoMQ 开源的 AutoMQ Kafka 和 AutoMQ RocketMQ 基于云对 Apache Kafka、Apache RocketMQ 消息引擎进行重新设计与实现,在充分利用云上的竞价实例、对象存储等服务的基础上,兑现了云设施的规模化红利,带来了下一代更稳定、高效的消息引擎。此外,AutoMQ 推出的 RocketMQ Copilot 专家系统也重新定义了 RocketMQ 消息运维的新范式,赋能消息运维人员更好的管理消息集群。
🌟 GitHub 地址:github.com/AutoMQ/auto…
💻 官网:www.automq.com
👀 B站:AutoMQ官方账号
🔍 视频号:AutoMQ
👉 扫二维码加入我们的社区群

关注我们,一起学习更多云原生干货
