

九、Transformer 江山一统

9.1、**消除恐惧:**我们亲手写一个 Transformer
9.1.1、Embeddings
#%% import torch.nn as nn import torch
class PositionalEmbedding(nn.Module):
def __init__(self, embed_size, max_len=512):
super().__init__()
# Compute the positional encodings once in log space.
pe = torch.zeros(max_len, embed_size).float()
pe.require_grad = False
position = torch.arange(0, max_len).float().unsqueeze(1)
div_term = (torch.arange(0, embed_size, 2).float()
* -(math.log(10000.0) / embed_size)).exp()
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
pe = pe.unsqueeze(0)
self.register_buffer('pe', pe)
def forward(self, x):
return self.pe[:, :x.size(1)]
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, embed_size, dropout=0.1):
"""
:param vocab_size: 词表大小
:param embed_size: embedding维度768
:param dropout: dropout概率
"""
super().__init__()
self.token_embedding = nn.Embedding(
vocab_size, embed_size, padding_idx=0)
self.position_embedding = PositionalEmbedding(
embed_size=embed_size, max_len=512)
self.token_type_embedding = nn.Embedding(2, embed_size, padding_idx=0)
self.dropout = nn.Dropout(p=dropout)
self.embed_size = embed_size
def forward(self, input_ids, token_type_ids):
x = self.token_embedding(input_ids) + self.position_embedding(
input_ids) + self.token_type_embedding(token_type_ids)
return self.dropout(x)
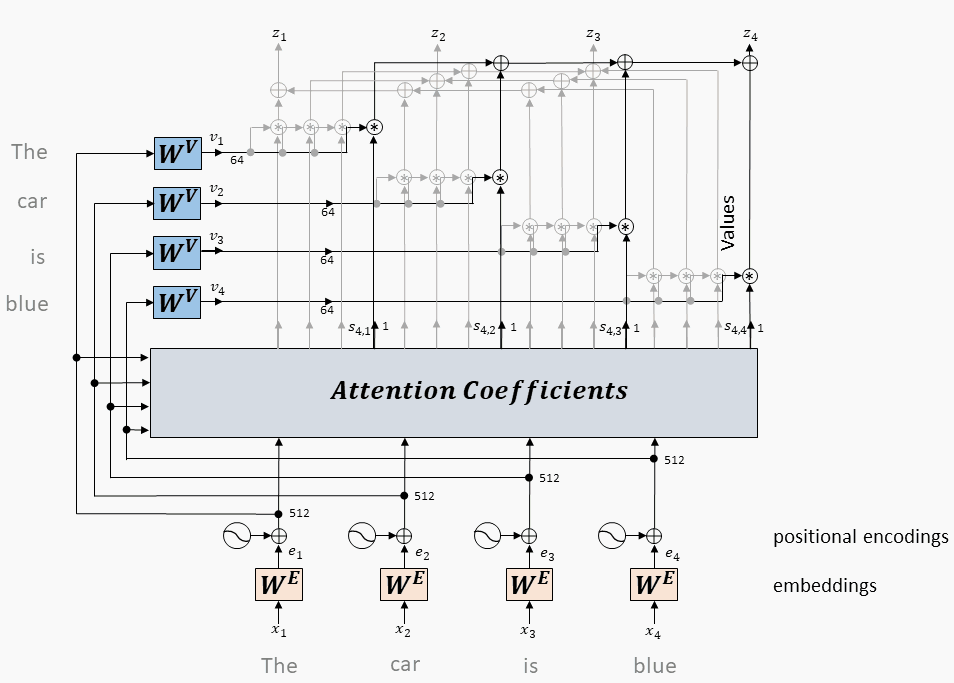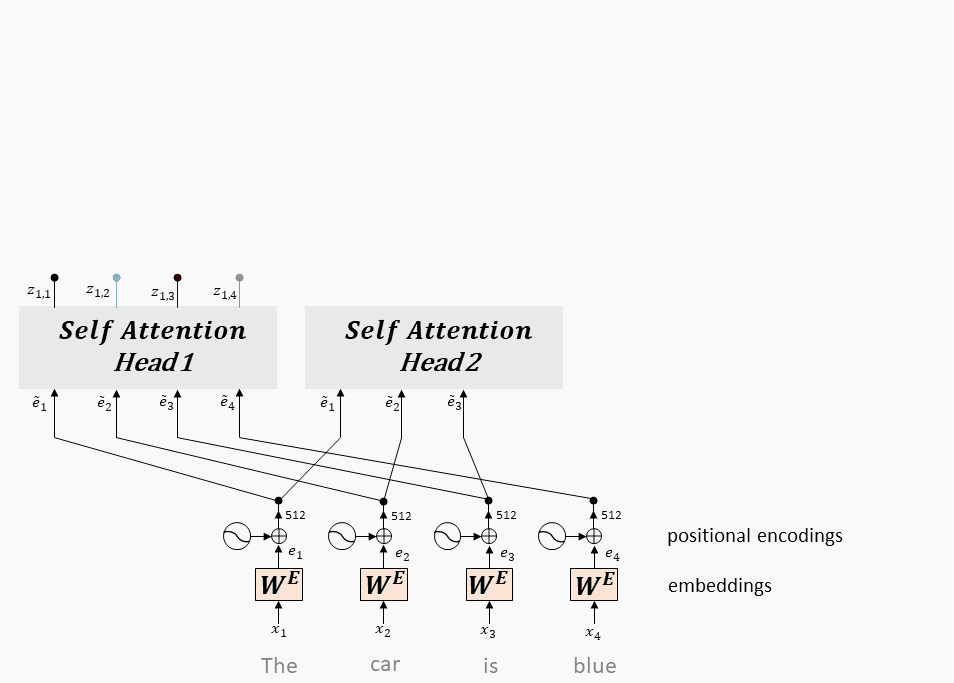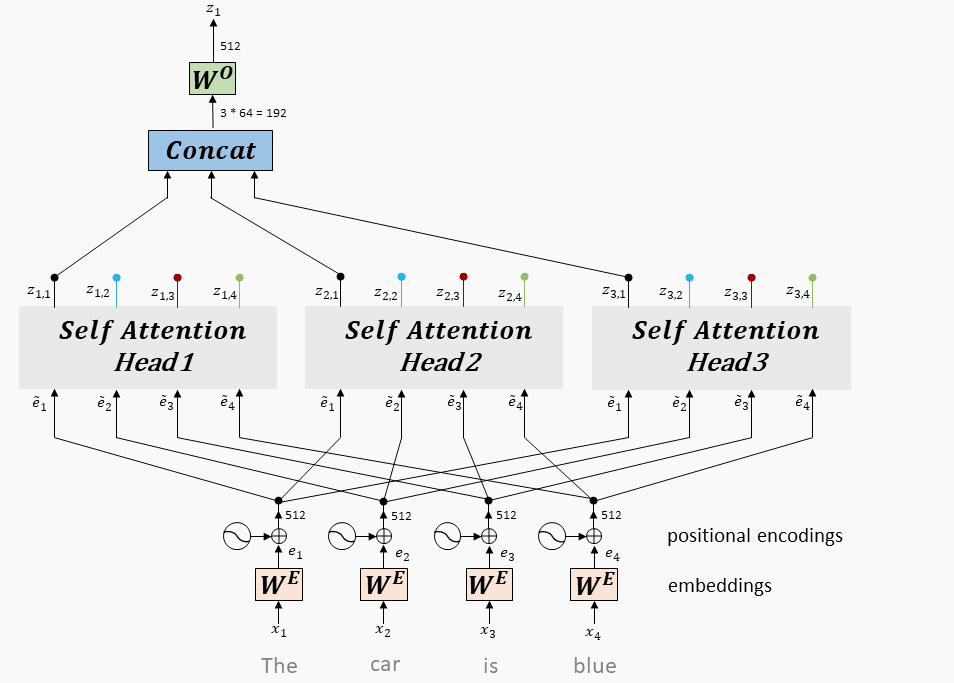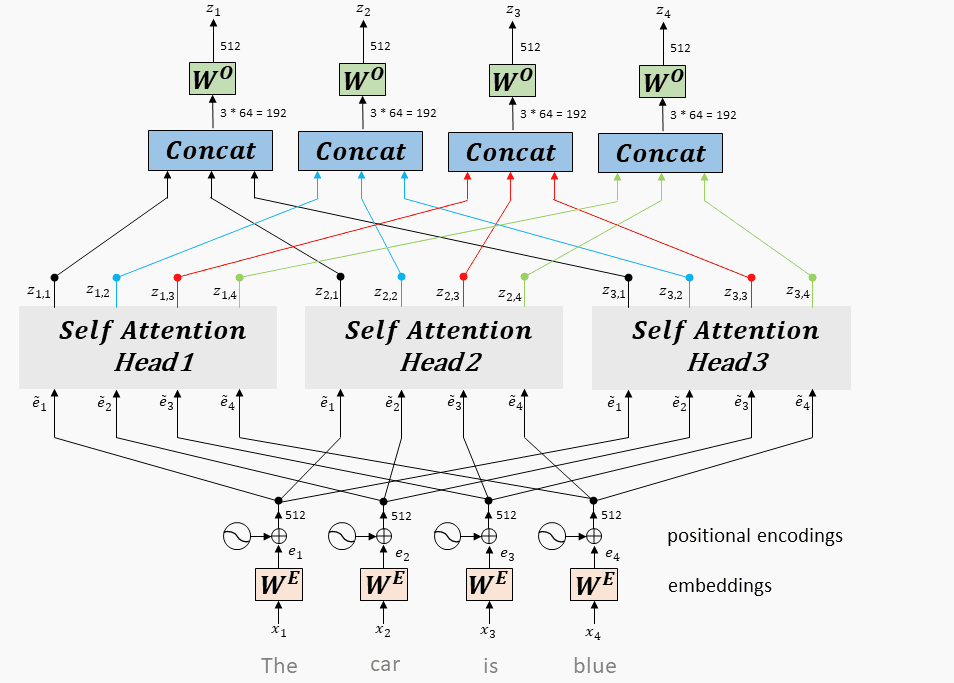
9.1.2、单头 Attention
#%% import torch.nn as nn import torch.nn.functional as F import torch
import math
''' query = query_linear(x) key = key_linear(x) value = value_linear(x) '''
单个头的注意力计算
class Attention(nn.Module):
def forward(self, query, key, value, mask=None, dropout=None):
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(query.size(-1))
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
每个token对应的query向量与每个token对应的key向量做内积
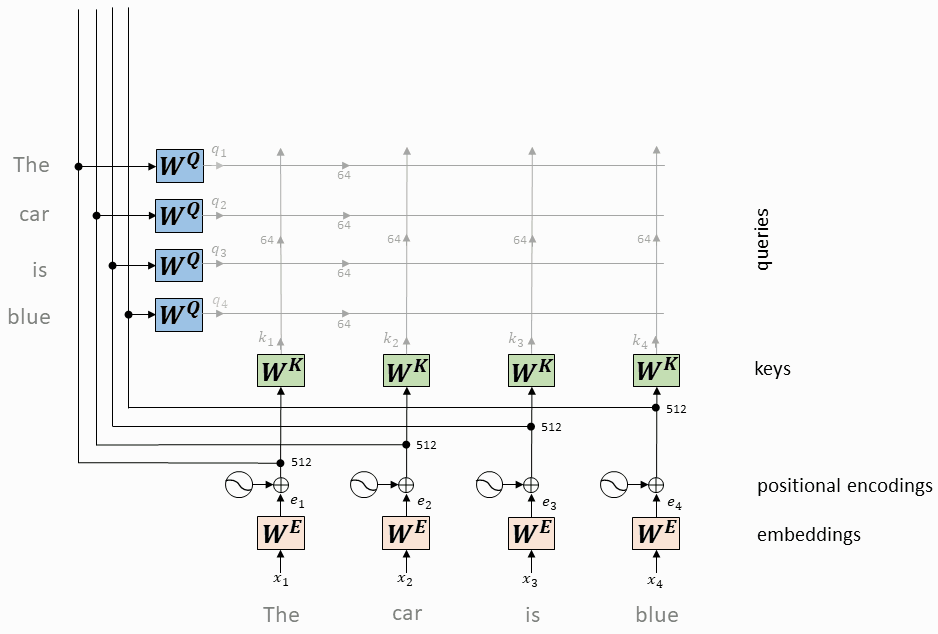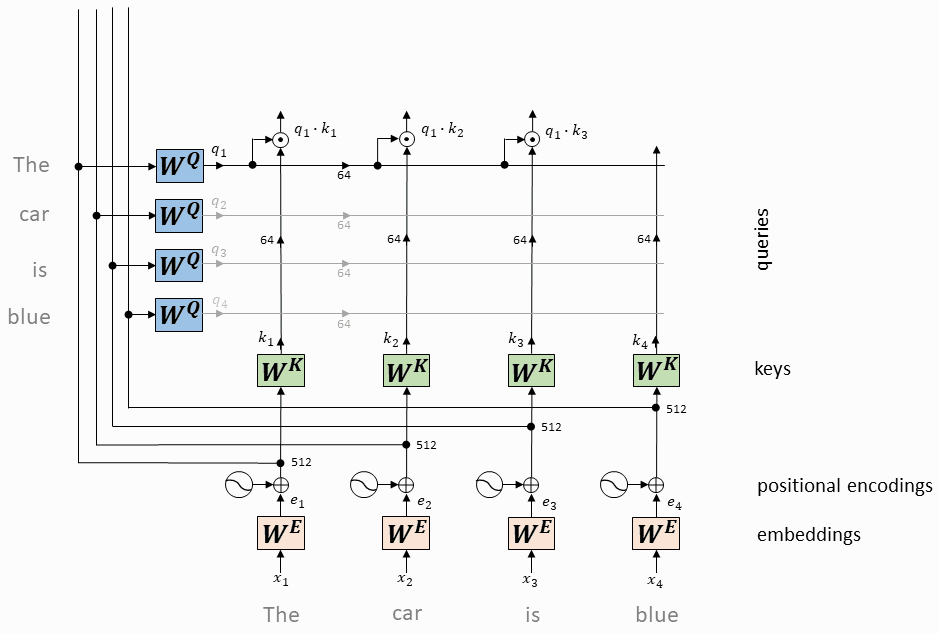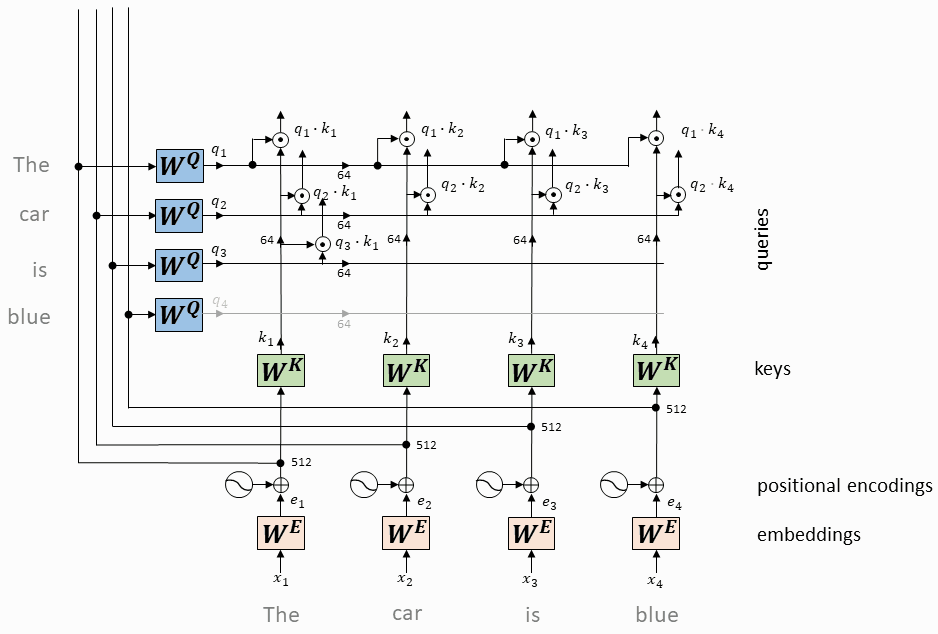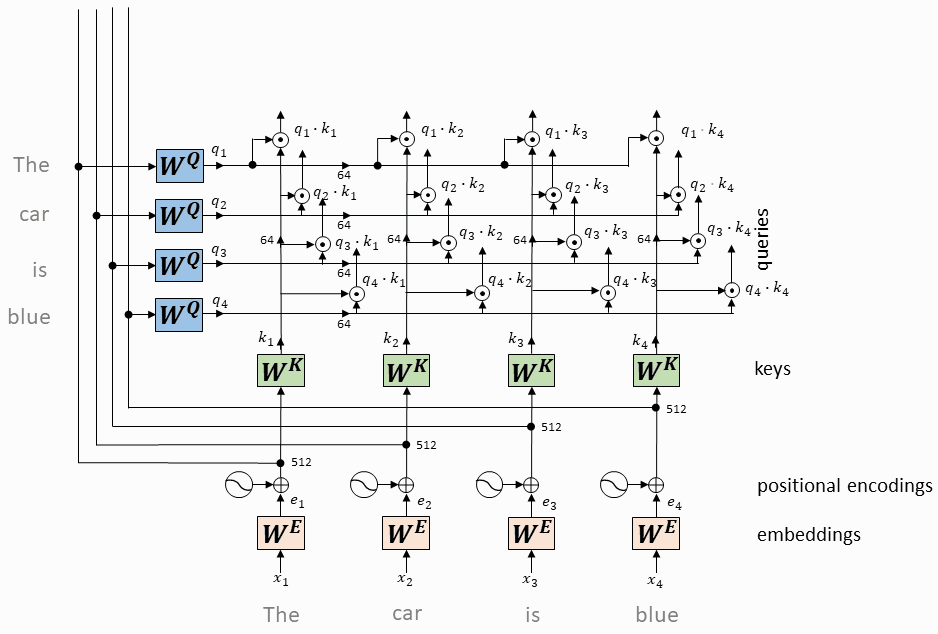
将上述内积取softmax(得到0~1之间的值,即为attention权重)
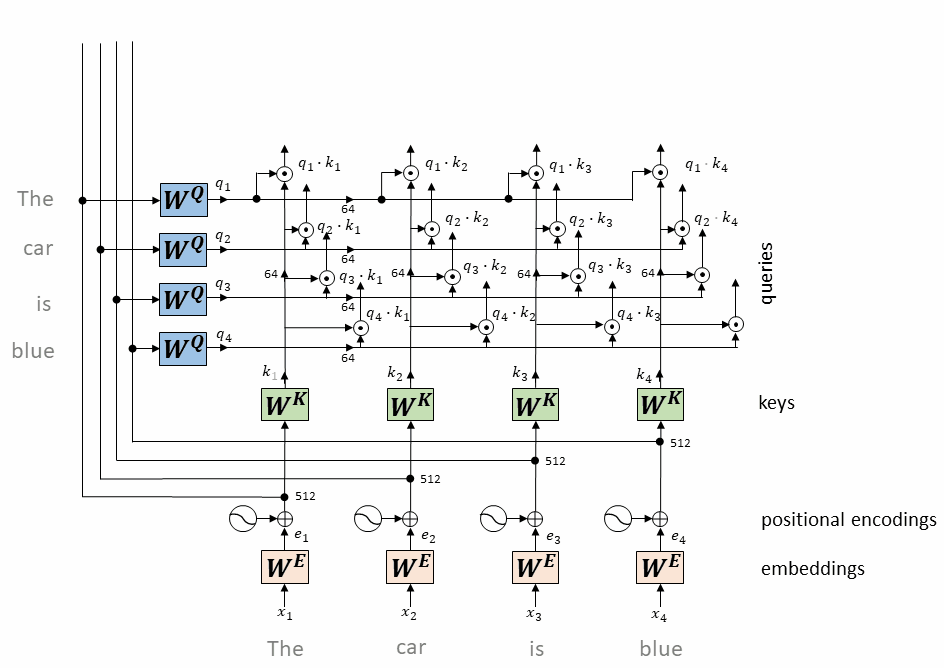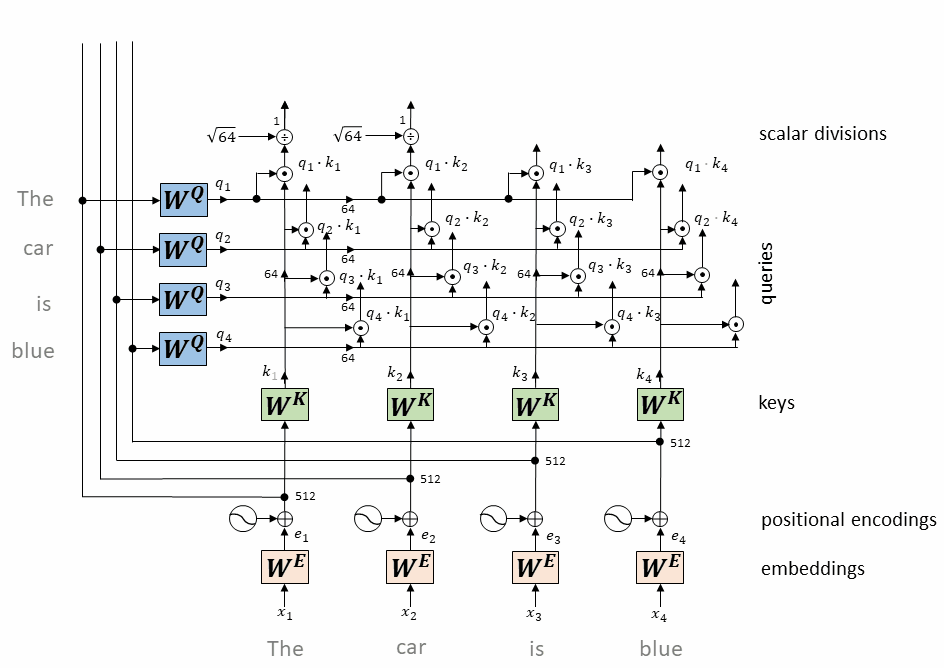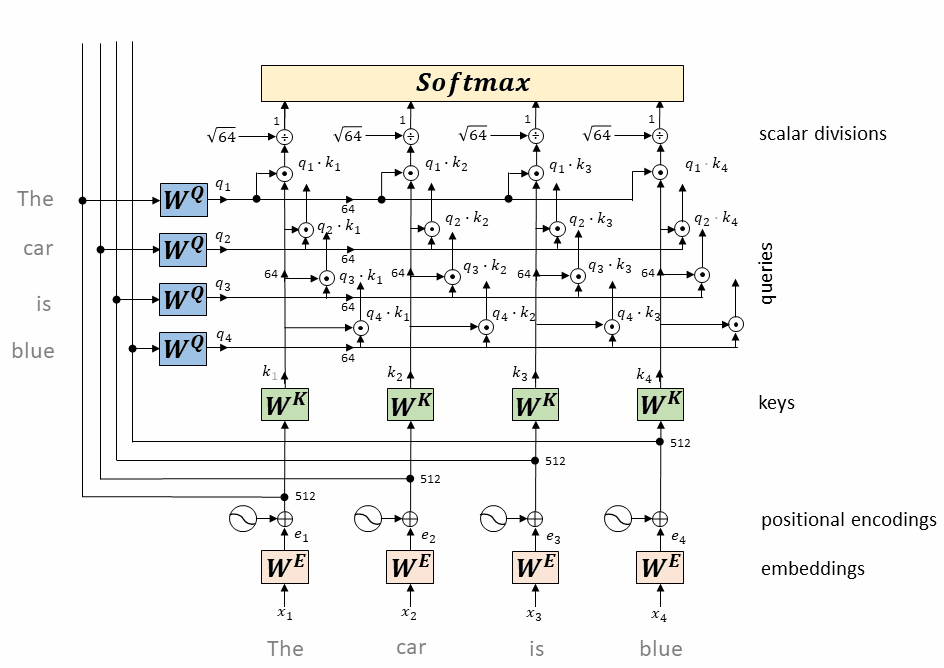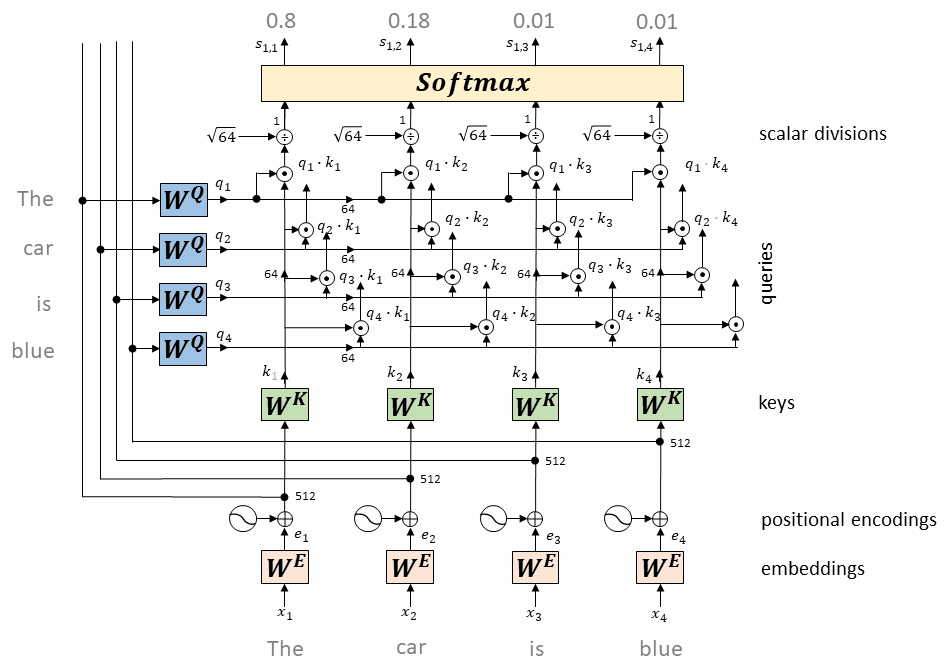
计算每个token相对于所有其它token的attention权重(最终构成一个$L\times L$的attention矩阵)
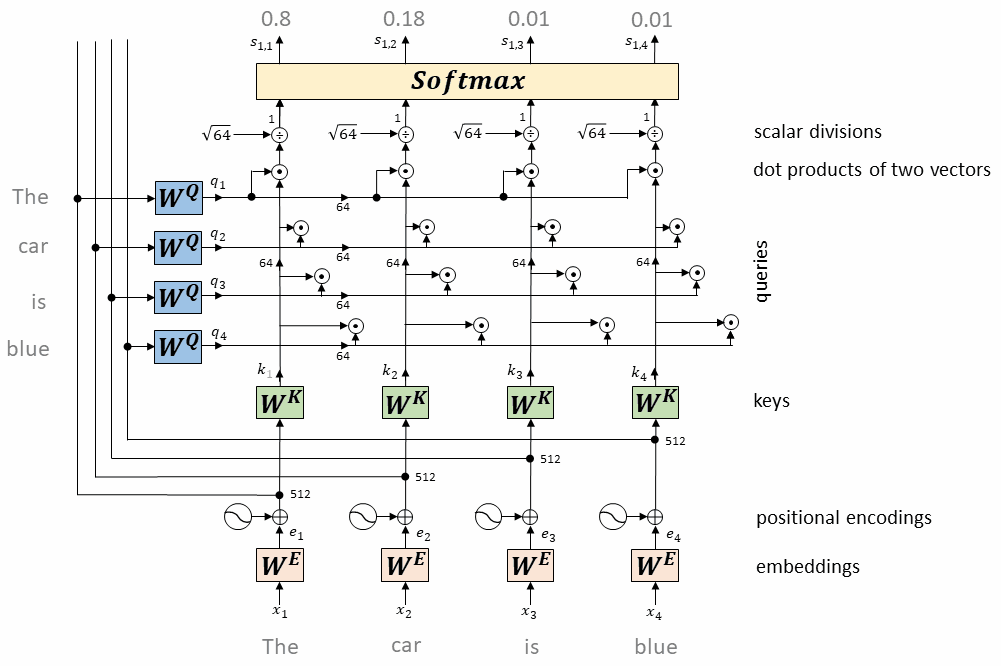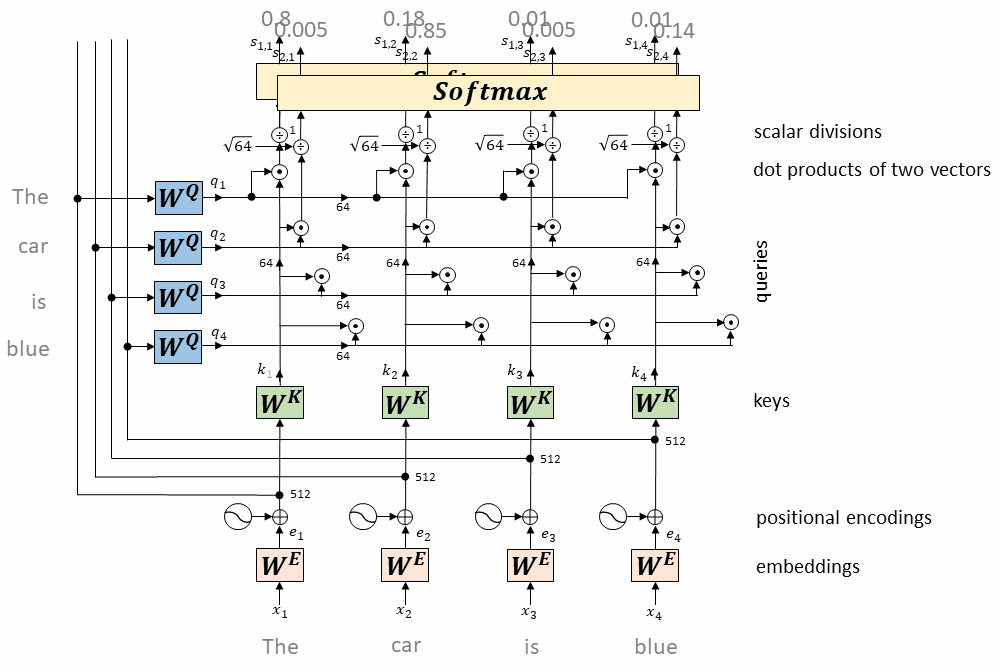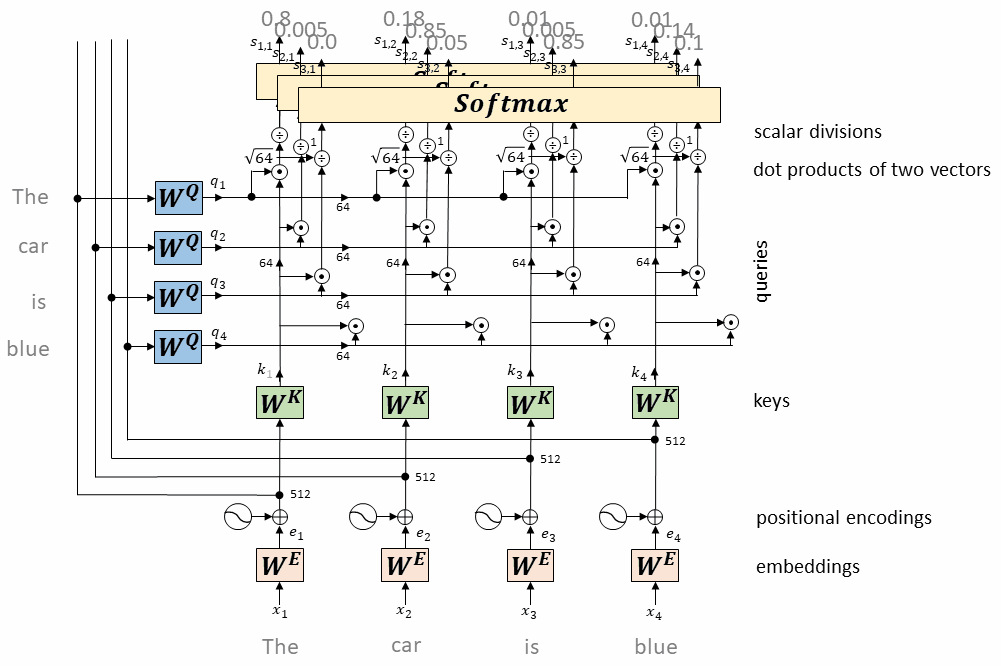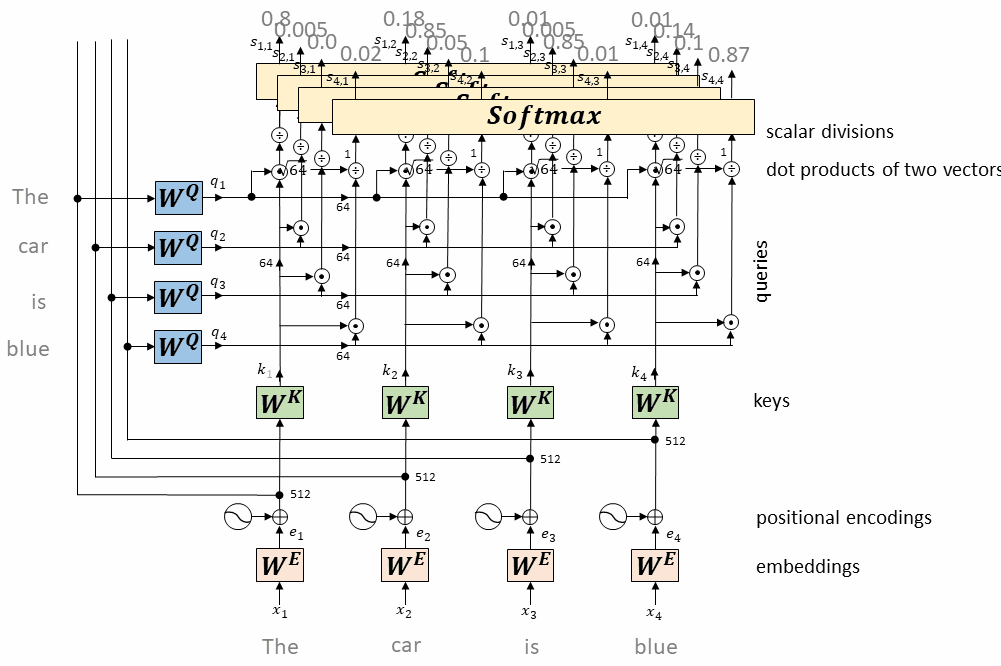
每个token对应的value向量乘以attention权重,并相加,得到当前token的self-attention value向量
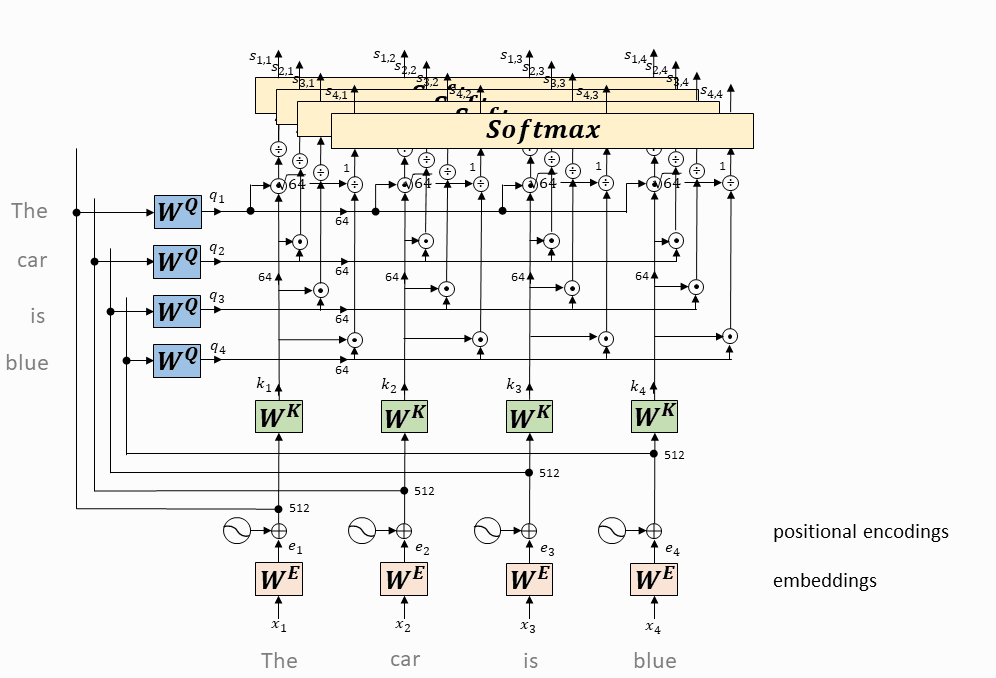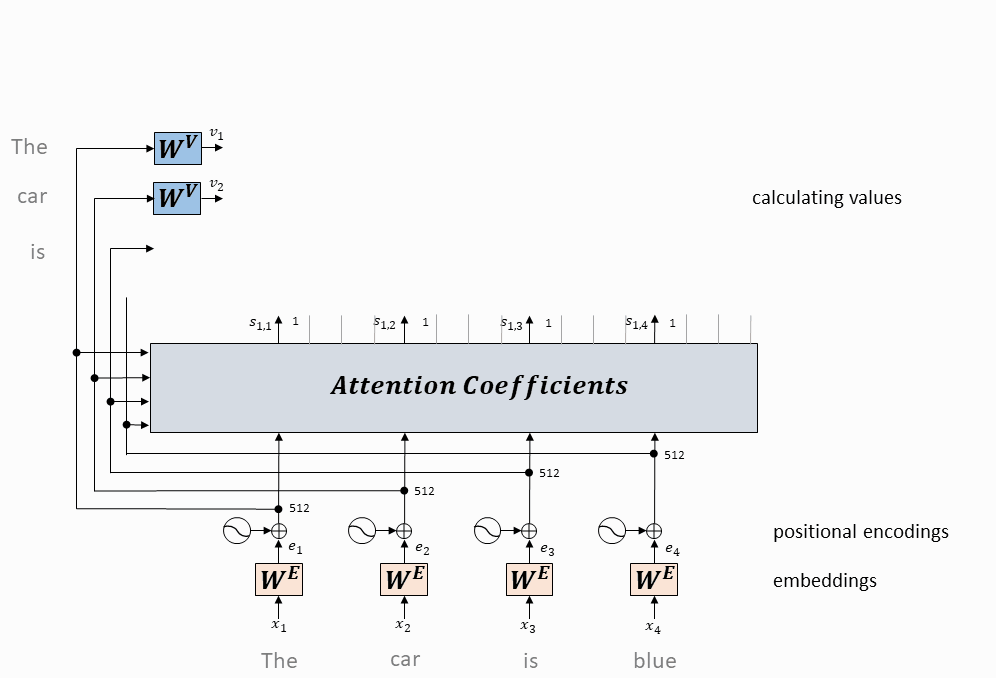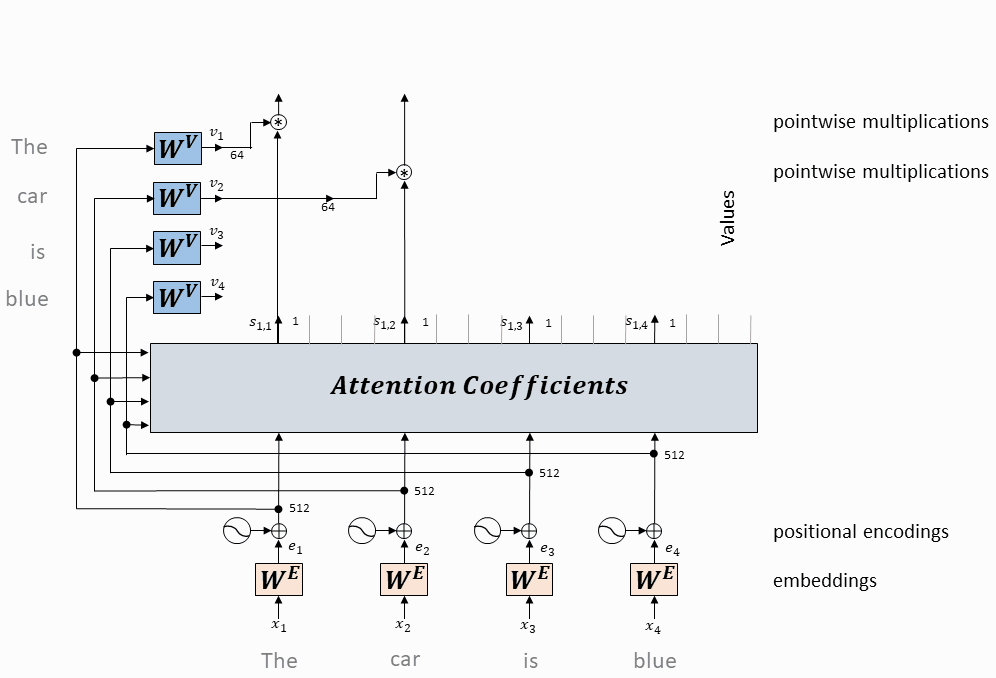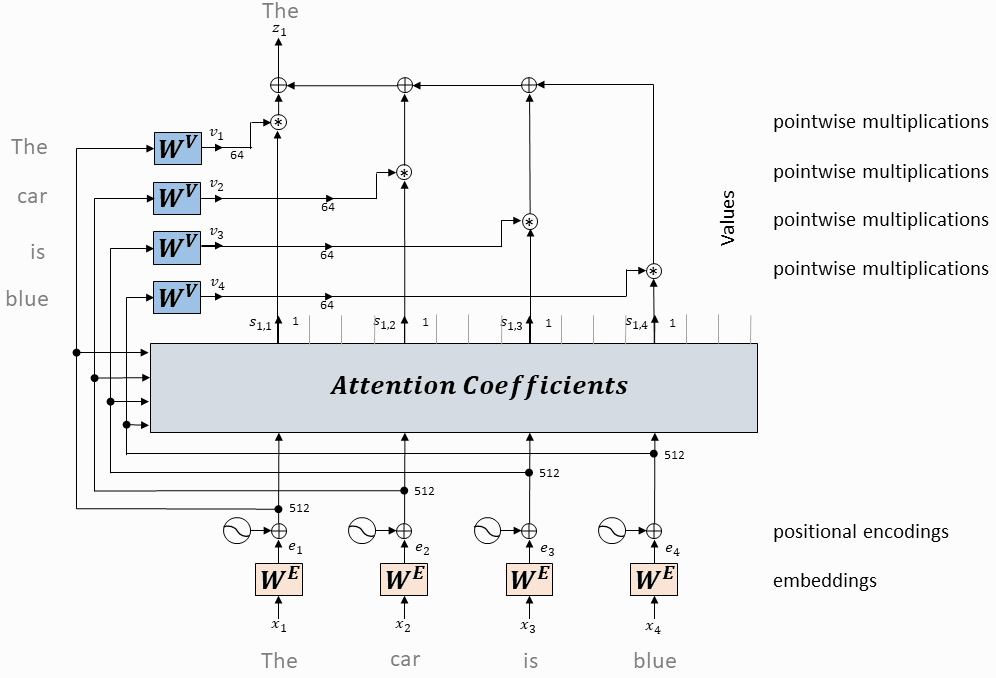
将上述操作应用于每个token
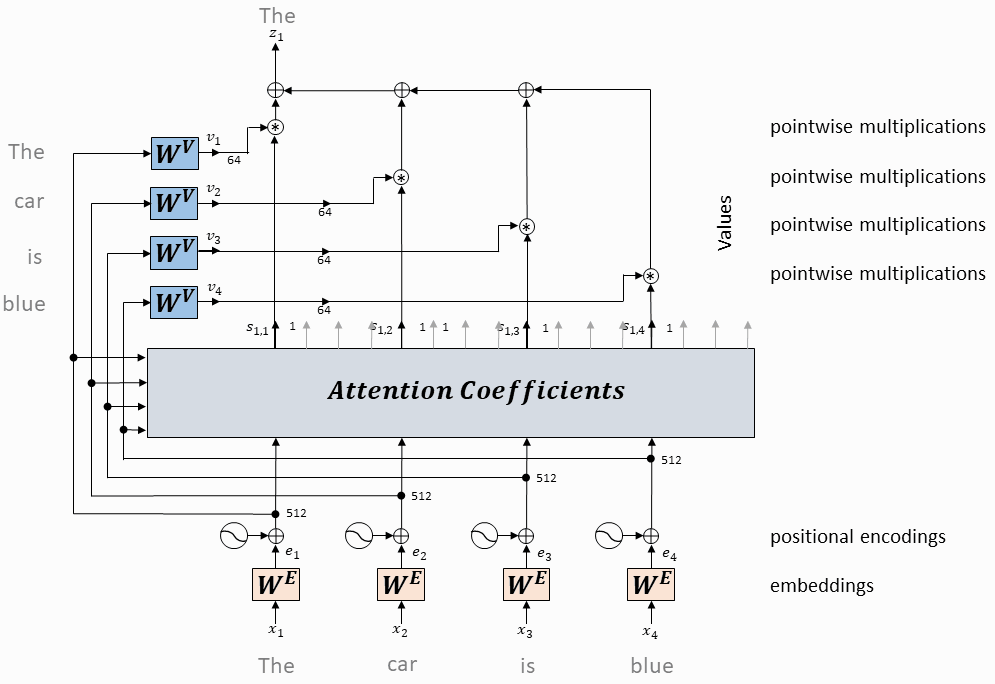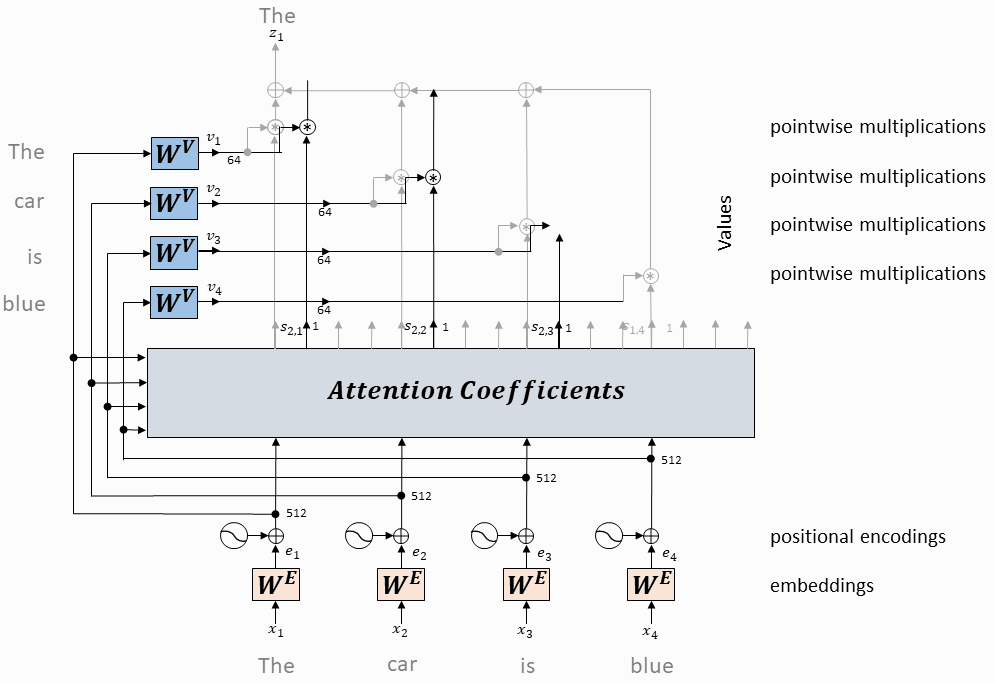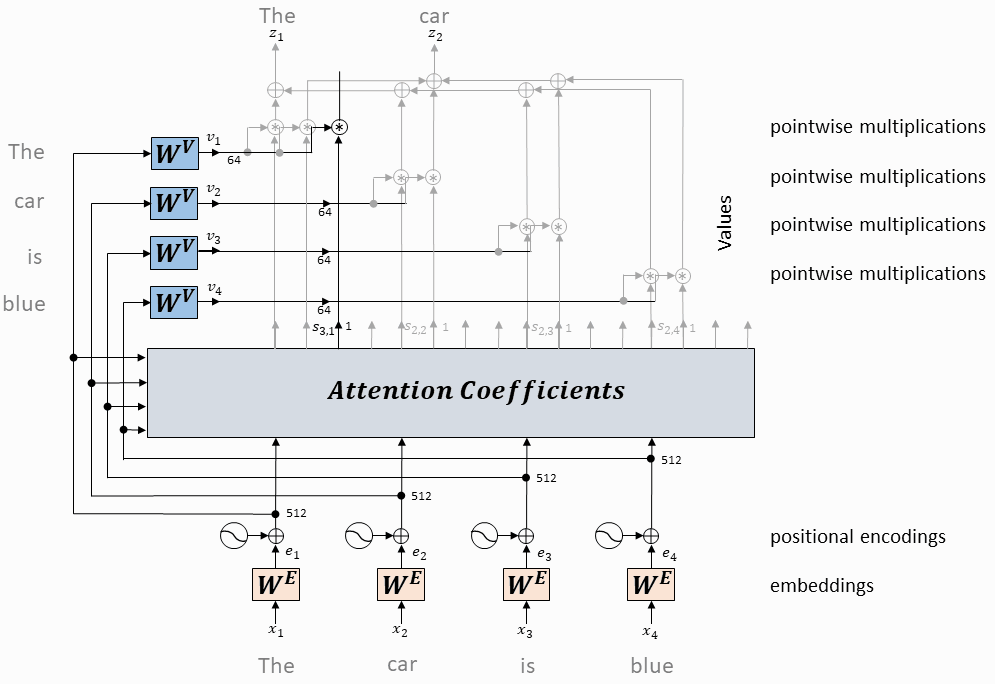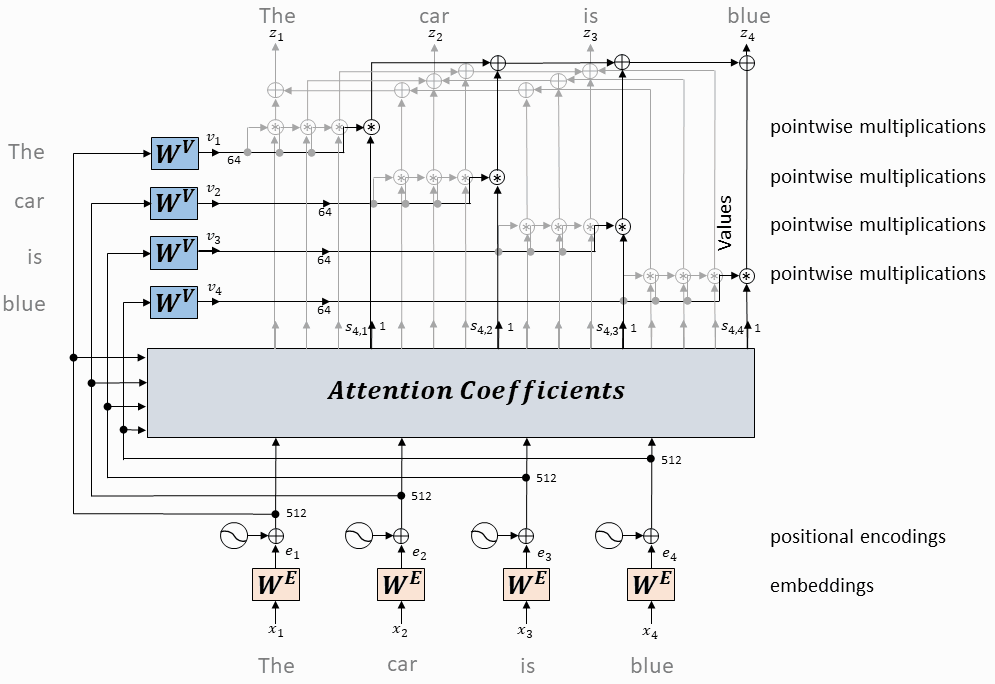
以上是一个头的操作,同时(并行)应用于多个独立的头
9.1.3、多头 Attention
将每个头得到向量拼接在一起,最后乘一个线性矩阵,得到 multi-head attention 的输出
#%%
import torch.nn
class MultiHeadedAttention(nn.Module):
def __init__(self, head_num, hidden_size, dropout=0.1):
"""
:param head_num: 头的个数,必须能被hidden_size整除
:param hidden_size: 隐层的维度,与embed_size一致
"""
super().__init__()
assert hidden_size % head_num == 0
self.per_head_dim = hidden_size // head_num
self.head_num = head_num
self.hidden_size = hidden_size
self.query_linear = nn.Linear(hidden_size, hidden_size)
self.key_linear = nn.Linear(hidden_size, hidden_size)
self.value_linear = nn.Linear(hidden_size, hidden_size)
self.output_linear = nn.Linear(hidden_size, hidden_size)
self.attention = Attention()
self.dropout = nn.Dropout(p=dropout)
def reshape(self, x, batch_size):
# 拆成多个头
return x.view(batch_size, -1, self.head_num, self.per_head_dim).transpose(1, 2)
def forward(self, x, mask=None):
batch_size = x.size(0)
query = self.reshape(self.query_linear(x))
key = self.reshape(self.key_linear(x))
value = self.reshape(self.value_linear(x))
# 每个头计算attention
x, attn = self.attention(
query, key, value, mask=mask, dropout=self.dropout
)
# 把每个头的attention*value拼接在一起
x = x.transpose(1, 2).contiguous().view(
batch_size, -1, self.hidden_size)
# 乘一个线性矩阵
return self.output_linear(x)
#%% md
9.1.4、全连接网络(Feed-Forward Network)
#%% import torch.nn as nn
class FeedForward(nn.Module):
def __init__(self, hidden_size, dropout=0.1):
super(FeedForward, self).__init__()
self.input_layer = nn.Linear(hidden_size, hidden_size*4)
self.output_layer = nn.Linear(hidden_size*4, hidden_size)
self.dropout = nn.Dropout(dropout)
self.activation = nn.GELU()
def forward(self, x):
x = self.input_layer(x)
x = self.activation(x)
x = self.dropout(x)
x = self.output_layer(x)
return x
9.1.5、拼成一层 Transformer
#%% import torch.nn as nn
class TransformerBlock(nn.Module):
def __init__(self, hidden_size, head_num, dropout=0.1):
super().__init__()
self.multi_head_attention = MultiHeadedAttention(head_num, hidden_size)
self.feed_forward = FeedForward(hidden_size, dropout=dropout)
self.layer_norm1 = nn.LayerNorm(hidden_size)
self.dropout1 = nn.Dropout(dropout)
self.layer_norm2 = nn.LayerNorm(hidden_size)
self.dropout2 = nn.Dropout(dropout)
self.dropout = nn.Dropout(p=dropout)
def forward(self, x, mask):
x0 = x
# 多头注意力层
x = self.multi_head_attention(x, mask)
# 残差和LayerNorm层(1)
x = self.dropout1(x)
x = self.layer_norm1(x0+x)
# 前向网络层
x1 = x
x = self.feed_forward(x)
# 残差和LayerNorm层(2)
x = self.dropout2(x)
x = self.layer_norm2(x1+x)
return x
Multi-head attention的输出,经过残差和norm之后进入一个两层全连接网络
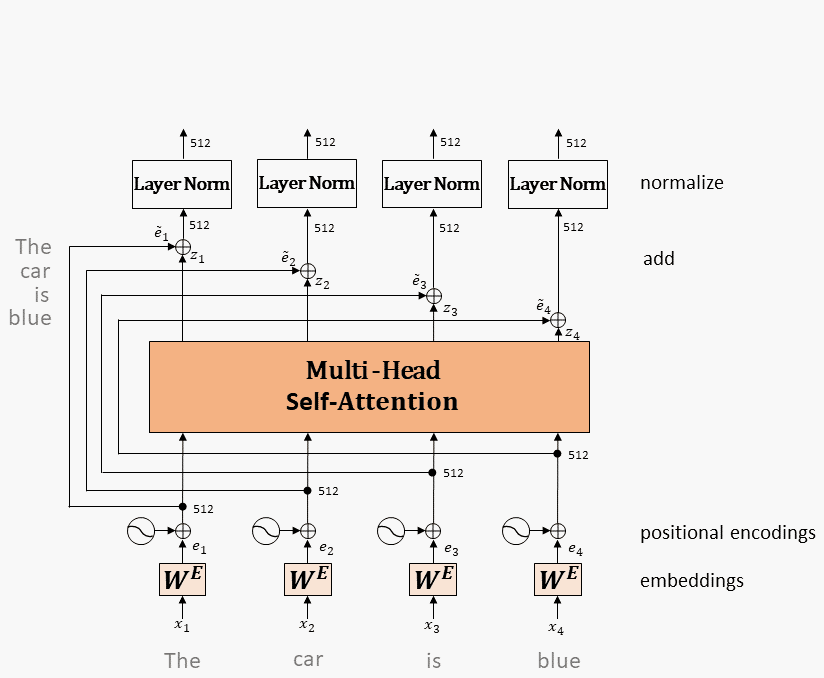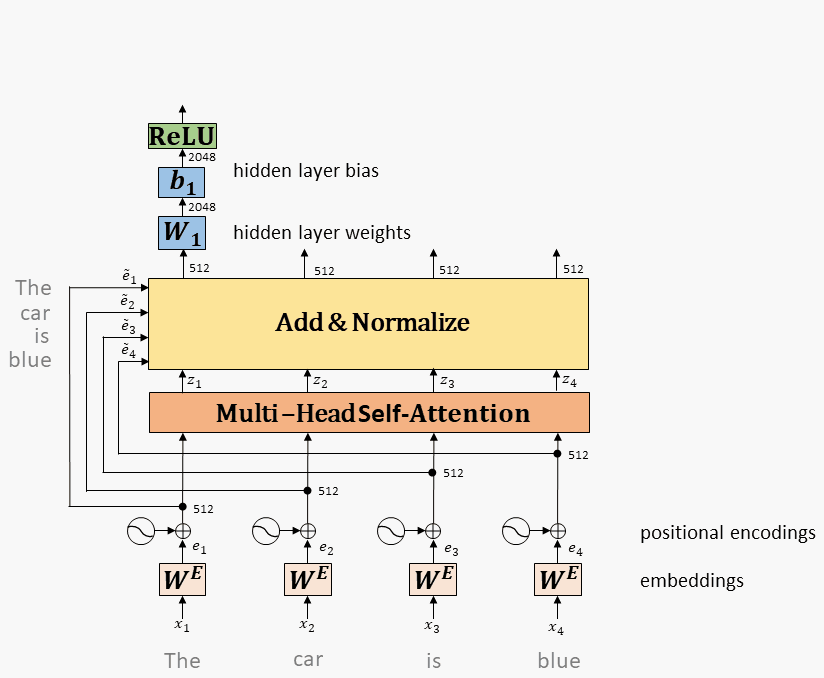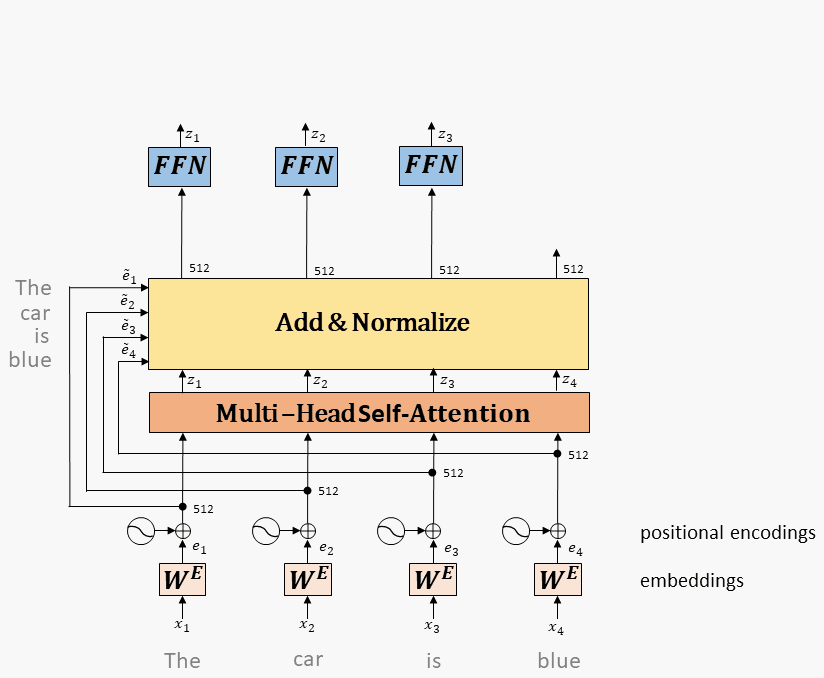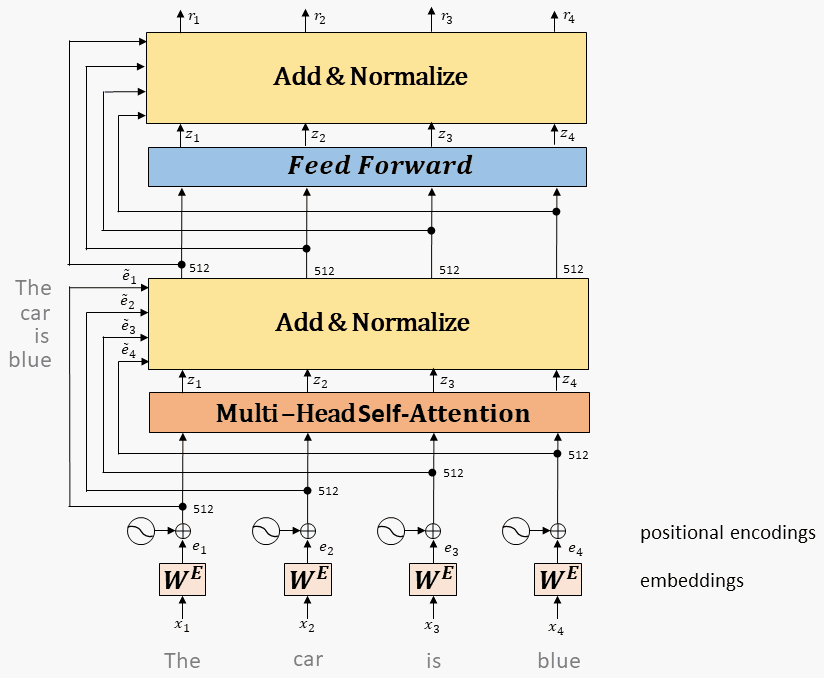
Layernorm:
其中 和 是可训练的参数,是超参,保持数值稳定性。
9.1.6、多层 Transformer 构成 BERT Encoder
#%% import torch.nn as nn
class BERT(nn.Module):
def __init__(self, vocab_size, hidden_size=768, layer_num=12, head_num=12, dropout=0.1):
super().__init__()
# Embedding层
self.embedding = BERTEmbedding(
vocab_size=vocab_size, embed_size=hidden_size)
# N层Transformers
self.transformer_blocks = nn.ModuleList(
[TransformerBlock(hidden_size, head_num, dropout)
for _ in range(layer_num)]
)
def forward(self, input_ids, token_type_ids):
"""
tokenizer(["你好吗","你好"], text_pair=["我很好","我好"], max_length=10, padding='max_length',truncation=True)
[CLS]你好吗[SEP]我很好[SEP][PAD]
[CLS]你好[SEP]我好[SEP][PAD][PAD][PAD]
input_ids: [
[101, 872, 1962, 1408, 102, 2769, 2523, 1962, 102, 0],
[101, 872, 1962, 102, 2769, 1962, 102, 0, 0, 0]
]
token_type_ids:[
[0, 0, 0, 0, 0, 1, 1, 1, 1, 0],
[0, 0, 0, 0, 1, 1, 1, 0, 0, 0]
]
"""
attention_mask = (x > 0).unsqueeze(
1).repeat(1, x.size(1), 1).unsqueeze(1)
# 计算embedding
x = self.embedding(input_ids, token_type_ids)
# 逐层代入Tranformers
for transformer in self.transformer_blocks:
x = transformer.forward(x, attention_mask)
return x
9.2 Transformer 怎么用
9.2.1. Encoder-Only LM 用于文本表示
针对不同下游任务,在 Encoder 上面添加不同的输出层
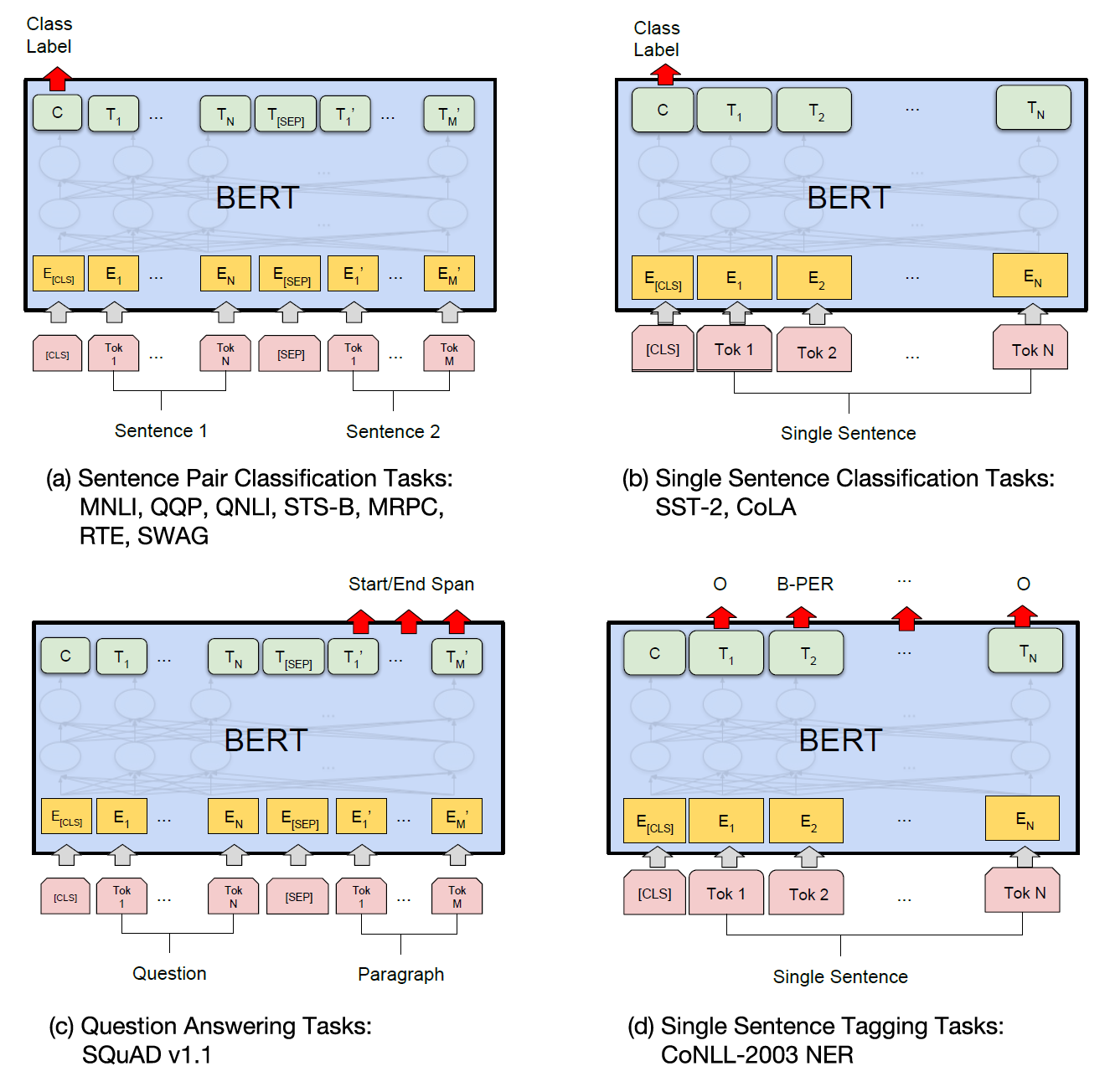
BERT-BiLSTM-CRF一个序列标注的经典网络结构
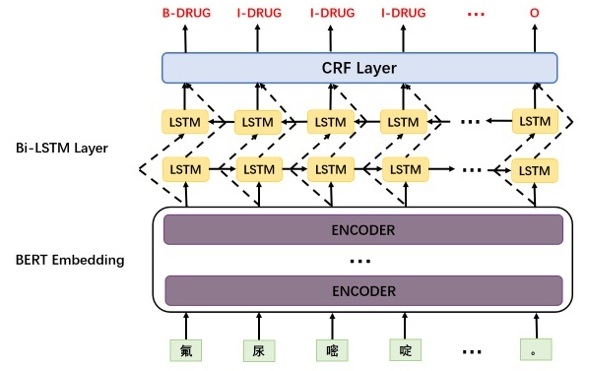
9.2.2. Encoder-Decoder LM,机器翻译/文本生成(大语言模型的一种形态)
- Decoder 也是 N 层 transformer 结构
- 生成一个 token,把它加入上文,再生成下一个 token,以此类推
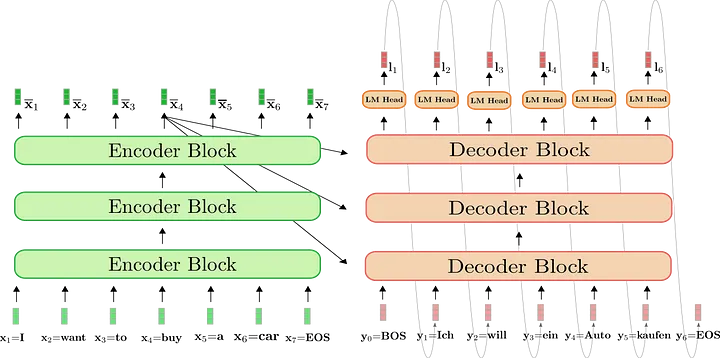
Decoder 的每个 token 与 encoder 最后一层的输出和 decoder 上文的 token 一起做 attention
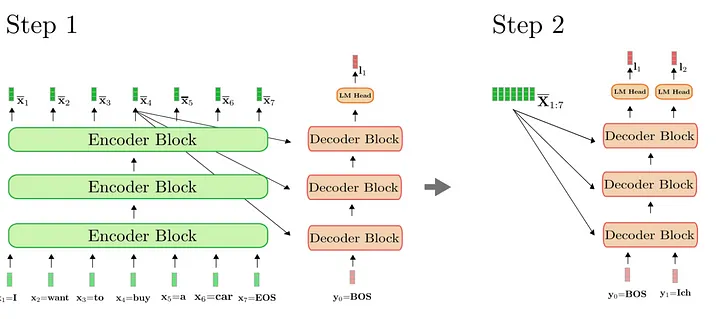
Decoder 的 token 只能 attend 到上文的 token(因为此时下文还没有出现)
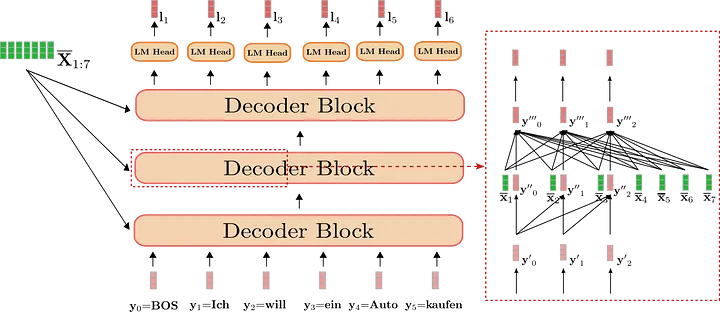
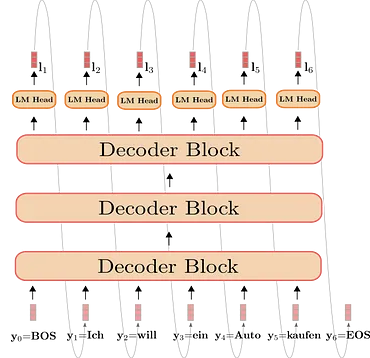
9.2.3. Decoder-Only LM 也叫 Causal LM 或 Left-to-right LM(GPT 家族)
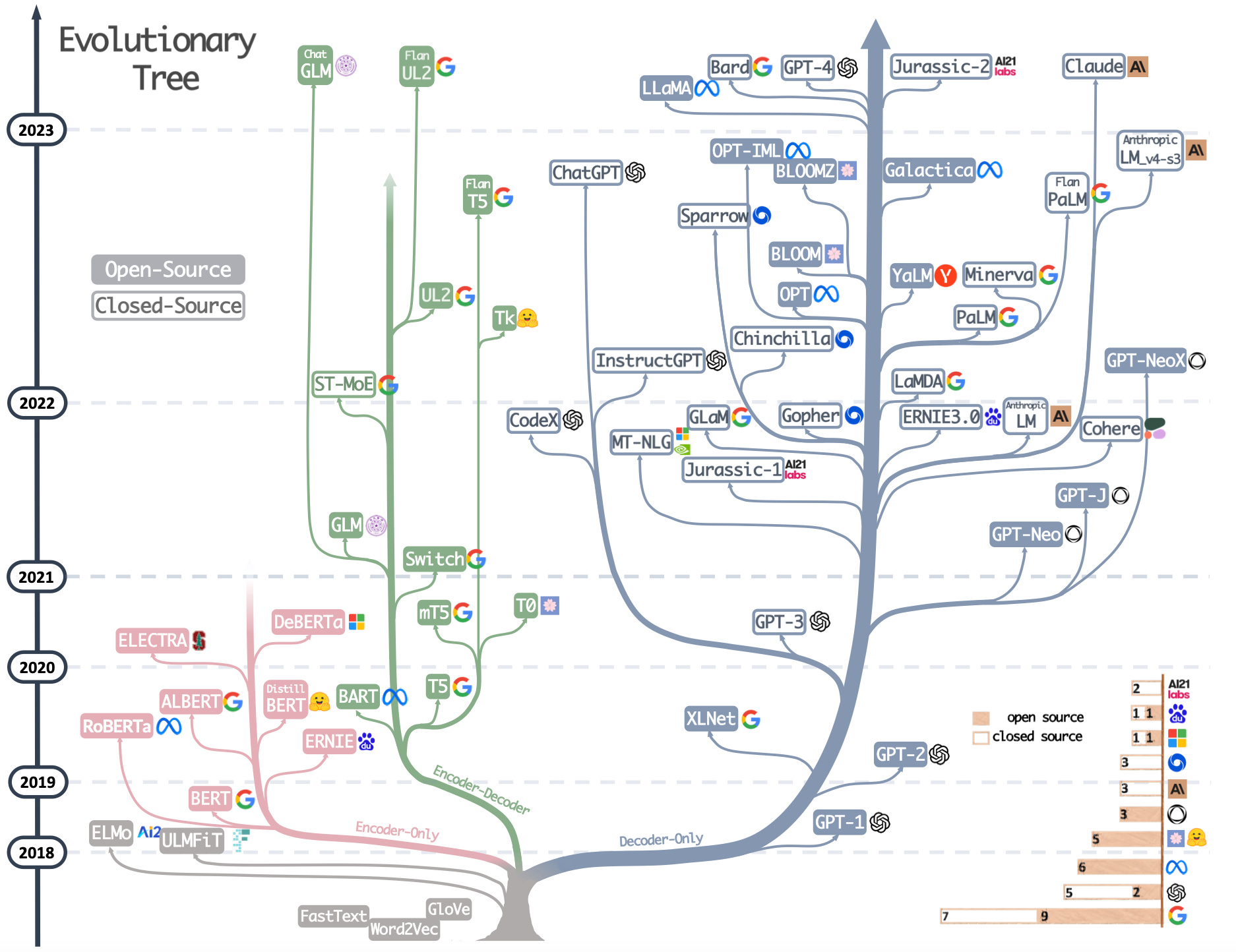
9.2.4. 大语言模型族谱
后记
📢博客主页:manor.blog.csdn.net
📢欢迎点赞 👍 收藏 ⭐留言 📝 如有错误敬请指正!
📢本文由 Maynor 原创,首发于 CSDN博客🙉
📢不能老盯着手机屏幕,要不时地抬起头,看看老板的位置⭐
📢专栏持续更新,欢迎订阅:blog.csdn.net/xianyu120/c…
本文由mdnice多平台发布
