

关键字:
KingbaseES、IN、EXISTS、子查询
1.多表查询-子查询
在KingbaseES数据库中,子查询的定义就是将一个查询的结果作为另一个查询的数据来源或判断条件的查询。子查询中所指定了的一个派生表必须利用圆括号进行包裹。而在本篇中着重介绍KES中子查询的概念以及IN与EXISTS的语法说明。
2.IN / NOT IN
IN运算符的主要作用是用来判断表达式的值是否位于给出的列表中;如果是则返回值为1即true,否则返回值为0即false。而NOT IN的作用则和IN恰好相反,NOT IN用于判断表达式的值是否不存在于给定的列表中;如果不是则返回值为1。否则返回值为0。 主要的使用语法为:
Expression IN (subquery);
Expression NOT IN (subquery);
其中Expression表达为要判断的表达式,subquery则表示为子查询,那么利用IN/NOT IN运算符就会将Expression中的值与子查询中的值进行逐一对比,并且subquery必须返回一列。当子查询没有返回任何行的情况下,IN会返回false。
对NULL的处理情况,IN运算符会根据两侧表达式进行判断,当存在空值NULL时,如果找不到与之相匹配的内容,则返回值为NULL,如果找到了匹配项,那么其返回值为1。以下是关于IN运算符对NULL值存在的处理情况示例:

在上例中,可以看到当IN两侧出现NULL值时,查询输出结果也为NULL,当一侧查询结果可以匹配时输出为t即true。 而NOT IN运算符则恰好与IN运算符相反,当NOT IN 运算符的两侧表达式存在空值NULL时,如果找不到匹配项时就会返回则会返回NULL值,如果可以找到匹配项就会返回0。以下是关于NOT IN运算符对NULL值存在的处理情况示例:

在上例中,可以看到当NOT IN两侧出现NULL值时,查询输出结果也为NULL,当一侧查询结果可以匹配时输出为f即false。
3.EXISTS / NOT EXISTS
EXISTS与NOT EXISTS的返回值是一个BOOL值,EXISTS子句主要根据其内查询语句的结果集空或者非空,返回一个BOOL值,如果内查询所返回的结果为非空,那么EXISTS运算符所执行子句就会返回true,那么这一行就可以作为外查询的结果行,否则就返回false,使其不能作为结果行。 主要的使用语法为:
EXISTS (subquery);
SELECT things FROM fdt WHERE EXISTS (SELECT t1 FROM t2);
在EXISTS运算符的运行过程中,其仅判断子查询能否返回至少一行内容为止,即并不判断整个子查询列表。这是由于这个子查询的输出列表并不影响EXISTS,的返回值,其返回值仅与能否返回行有关,而不取决于这些行的内容。下面为一个EXISTS判断的简单示例:
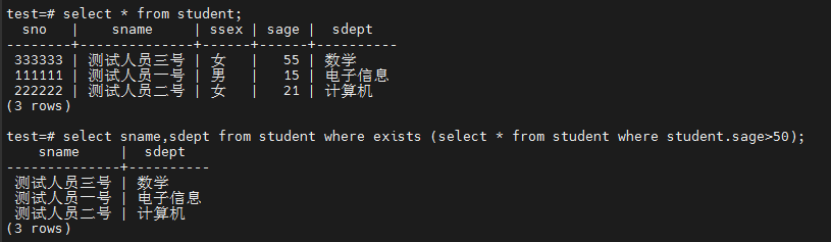
在这个示例中,首先创建了一个简单的学生表并具有对应的学号,年龄,性别,以及名字和专业,那么通过EXISTS来判断是否有年龄大于50岁的学生存在,并将其作为子查询条件来对外查询进行判断,可以看到EXISTS仅返回true即返回存在有大于50岁的学生,那么这个查询语句就等效于SELECT sname,sdept FROM student WHER TRUE;
4.关于IN / NOT IN 与EXISTS / NOT EXISTS知识扩展
IN 与 EXISTS查询的速度比较:为了了解这两个运算符的查询性能比较,首先就需要明白两种运算符的查询机制。
IN运算符在查询时,首先查询子查询的表,然后将内表与外表做一个笛卡尔积的形式,并按照条件语句进行筛选,因此相对于内表较小的时候,IN的查询速度更快一些。例如:当外表t1有10000条记录,内表t2有1000000条记录时,那么最多有可能遍历的次数为100001000000次,效果较差而当内表t2有100条记录时,这时最多可能的遍历次数就是10000100次,遍历次数大大减少,而查询效率得到了很大的提高。
EXISTS运算符指定一个子查询并检测行为是否存在,因此仅遍历外表,然后看外表中的数据记录有没有和内表中相同的,然后如果匹配上就直接放入结果集中,例如当外表t1有10000条记录时,内表t2表有10000000条记录时,执行EXISTS()会执行10000次去判断外表中与内表中所查数据是否匹配。当内表t2有100条记录时,其依然仅执行10000次即t1.length()次,因此可见当内表数据越多的时候EXISTS更加能发挥效果,这时由于EXISTS在执行过程中并不缓存结果集,它对结果集的内容并不重要而重要的是结果集中是否有记录,如果有则返回TRUE,否则返回FALSE。而这种情况下使用IN遍历更好,这时因为IN是在内存里遍历,而EXISTS需要查询数据库,而查询数据库所消耗的性能更高,内存遍历则比较块。
因此如果子查询得出结果集记录较少,主查询中的表较大且有索引时应该使用IN,反之若外层查询记录较少,子查询的表又大,有索引的时则使用EXISTS。 NOT IN 与NOT EXISTS查询速度比较:
如果查询语句使用了NOT IN 那么内外表都需要进行全表扫描并且不会用到索引,而NOT EXISTS的子查询依然可以使用表上的索引,因此无论哪个表大,NOT EXISTS都比NOT IN快。
5.总结
以上,对KES子查询过程中常用的关键运算符IN / NOT IN与EXISTS / NOT EXISTS的概念、语法以及示例拓展进行详细的说明介绍。对IN与EXISTS的区分主要在于是否造成了驱动顺序的改变,这是性能变化的关键,如果是EXISTS,那么外表就是驱动表会被先访问,如果是IN,那么就会先执行子查询,所以一般是以驱动表快速返回为目标,那么就会考虑到索引与结果集的关系。IN将外表与内表做hash连接而EXISTS对外表做loop循环每次循环再对内表进行查询。
通过合理的使用这两种关键运算符可以更好的理解和发挥SQL语言的强大特效,从而提高数据分析与决策的能力。
