

数列排序算法
排序算法是《数据结构与算法》中最基本的算法之一。
排序算法可以分为内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存。常见的内部排序算法有:插入排序、希尔排序、选择排序、冒泡排序、归并排序、快速排序、堆排序、基数排序等。
1.冒泡排序
- 类似气泡上涌的动作,会将数据在数组中从小到大或者从大到小不断的向前移动。
基本思想:
- 冒泡排序的基本思想是对比相邻的两个元素值,如果满足条件就交换元素值,把较小的元素移动到数组前面,把大的元素移动到数组后面(也就是交换两个元素的位置),这样较小的元素就像气泡一样从底部上升到顶部。
算法思路
- 冒泡算法由双层循环实现,其中外部循环用于控制排序轮数,一般为要排序的数组长度减1次,因为最后一次循环只剩下一个数组元素,不需要对比,同时数组已经完成排序了。而内部循环主要用于对比数组中每个相邻元素的大小,以确定是否交换位置,对比和交换次数随排序轮数而减少。
算法步骤
- 比较相邻的元素。如果第一个比第二个大,就交换他们两个。
- 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对。这步做完后,最后的元素会是最大的数。
- 针对所有的元素重复以上的步骤,除了最后一个。
- 持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
#!/bin/bash
#冒泡排序,实现升序
arr=(63 4 24 1 3 15)
echo "原始的数组元素列表为: ${arr[@]}"
#获取素组的长度
length=${#arr[@]}
#使用外部循环定义比较轮数,比较轮数为数组长度减1,且从1开始
for ((a=1; a<length; a++))
do
#定义使用内部循环来进行相邻元素的比较,确定元素的位置,较大的数放后面,且每轮的>比较次数会随着轮数递减
#这里内部循环的变量用来表示两个相邻比较元素的前一个元素的下标
for ((b=0; b<length-a; b++))
do
#定义left变量获取两个相邻比较元素的前一个元素的值
left=${arr[$b]}
#定义right变量获取两个相邻比较元素的后一个元素的值
c=$[b + 1]
right=${arr[$c]}
#将两个相邻元素的值进行比较,如果前一个元素的值比较大则两个元素互换值
if [ $left -gt $right ];then
tmp=$left
arr[$b]=${arr[$c]}
arr[$c]=$tmp
fi
done
done
echo "排序后的数组顺序为:${arr[@]}"
[root@localhost ~]# . 38.sh
原始的数组元素列表为: 63 4 24 1 3 15
排序后的数组顺序为:1 3 4 15 24 63
2.直接选择排序
与冒泡排序相比,直接选择排序的交换次数更少,所以速度会快些。
基本思想
将指定排序位置与其它数组元素分别对比,如果满足条件就交换元素值,注意这里区别冒泡排序,不是交换相邻元素,而是把满足条件的元素与指定的排序位置交换(如从最后一个元素开始排序),这样排序好的位置逐渐扩大,最后整个数组都成为己排序好的格式。
算法步骤
首先在未排序序列中找到最小(大)元素,存放到排序序列的起始位置。
再从剩余未排序元素中继续寻找最小(大)元素,然后放到已排序序列的末尾。
重复第二步,直到所有元素均排序完毕。
#!/bin/bash
#直接选择排序,实现升序
arr=(63 4 24 1 3 15)
length=${#arr[*]}
#定义排序轮数,为数组长度减1
for ((a=1; a<length; a++))
do
#初始定义假设下标为0的元素的值最大
n=0
#定义内循环变量为从第二个元素下标开始.用于比较当前假设的最大的元素的值,并记录最>大元素的下标
for ((b=1; b<=length-a; b++))
do
if [ ${arr[$b]} -gt ${arr[$n]} ];then
n=$b
fi
done
#获取每轮最后一个比较元素的下标
last=$[length - a]
#拿最大的元素和当前轮数的最后一个比较元素交换值
tmp=${arr[$last]}
arr[$last]=${arr[$n]}
arr[$n]=$tmp
done
echo "排序后的数组的顺序为:${arr[@]}"
[root@localhost ~]# . 41.sh
排序后的数组的顺序为:1 3 4 15 24 63
3.反转排序
以相反地顺序把原有数组的内容重新排序
基本思想: 基本思想!: 顾名思义,反转排序就是以相反的顺序把原有[数组]内容重新排序。反转排序在实际开发中经常用到。其基本思想较为简单,也很好理解,其实就是把最后一个元素和第一个元素交换位置,倒数第二个和第二个交换位置,以此类推,直到把所有数组元素反转替换为止。
初始数组排序【10 20 30 40 50 60】
第一趟排序后 60 【20 30 40 50】 10
第二趟排序后 60 50 【30 40】 20 10
第三趟排序后 60 50 40 30 20 10
#!/bin/bash
#反转排序
arr=(10 20 30 40 50 60 70 80)
length=${#arr[@]}
#设置前后两个替换元素中的前面的元素下标的取值范围,下标从0开始
for ((a=0; a<length/2; a++))
do
tmp=${arr[$a]}
arr[$a]=${arr[$length-1-$a]}
arr[$length-1-a-$a]=$tmp
done
echo "反转排序后的数组顺序为:${arr[@]} "
[root@localhost ~]# . 42.sh
反转排序后的数组顺序为:80 30 20 50 50 20 70
4.插入排序
插入排序的代码实现虽然没有冒泡排序和选择排序那么简单粗暴,但它的原理应该是最容易理解的了,因为只要打过扑克牌的人都应该能够秒懂。插入排序是一种最简单直观的排序算法,它的工作原理是通过构建有序序列,对于未排序数据,在已排序序列中从后向前扫描,找到相应位置并插入。
插入排序和冒泡排序一样,也有一种优化算法,叫做拆半插入。
算法步骤
将第一个待排序序列第一个元素看做一个有序序列,把第二个元素到最后一个元素当成是未排序序列。
从头到尾依次扫描未排序序列,将扫描到的每个元素插入有序序列的适当位置。(如果待插入的元素与有序序列中的某个元素相等,则将待插入元素插入到相等元素的后面。)
bash
复制代码
#!/bin/bash
#插入排序,实现升序
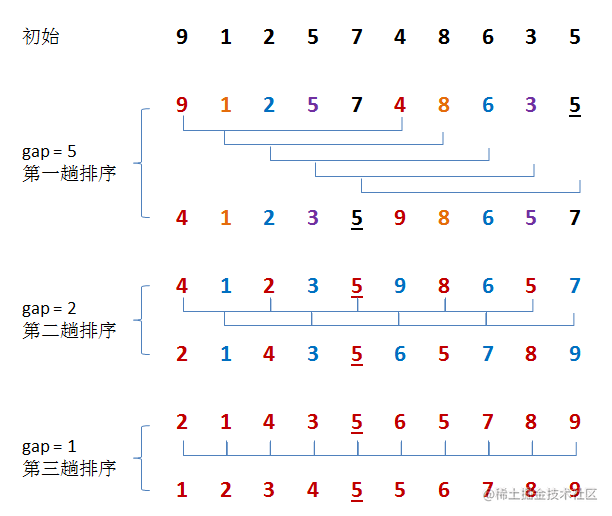
arr=(63 4 24 5 3)
length=${#arr[@]}
#定义比较的轮数,并a的值也用于作为待排序的元素下标
for ((a=1; a<length; a++))
do
#定于用于和待排序的元素比较的元素下标范围
#拿待排序的元素和前面已排序的元素进行比较,较大的数放后面的排序元素>的位置,娇小的数放前面的位置
for ((b=0; b<a; b++))
do
if [ ${arr[$a]} -lt ${arr[$b]} ];then
tmp=${arr[$a]}
arr[$a]=${arr[$b]}
arr[$b]=$tmp
fi
done
done
echo "排序后的数组的顺序为:${arr[@]} "
[root@localhost ~]# . 43.sh
排序后的数组的顺序为:3 4 5 24 63
