要做什么
我们的要做的是,训练出一个人工神经网络(ANN),使它能够识别手写数字(如下图所示)。

背景
人工神经网络是什么
人工神经网络(Artificial Neural Network,简称ANN),也被称为神经网络(NN),是受生物神经网络(Biological Neural Networks)启发的计算系统。
神经网络是一种重要的人工智能技术,其在图像识别、自然语言处理、医疗和金融等领域得到了广泛应用。
手写数字从哪来
这些手写数字,来自大名鼎鼎的 MNIST 手写数字图像集。
MNIST 是机器学习领域最有名的数据集之一,也称作计算机视觉领域的 hello world 数据集。

基础
由于人工神经网络(Artificial Neural Network)的灵感来源是生物神经网络(Biological Neural Networks),那么接下来,我将按照以下思路讲解:
- 生物神经网络 的基本结构和特性。
- 人工神经网络 如何对其进行模拟。
生物神经网络
生物神经网络一般指,生物的大脑神经元、细胞、触突等结构组成的一个大型网络结构,用来帮助生物进行思考和行动。
【神经元】
神经元即神经元细胞,是神经系统最基本的结构和功能单位。
神经元包括胞体和突起两大部分,突起又分为轴突和树突。
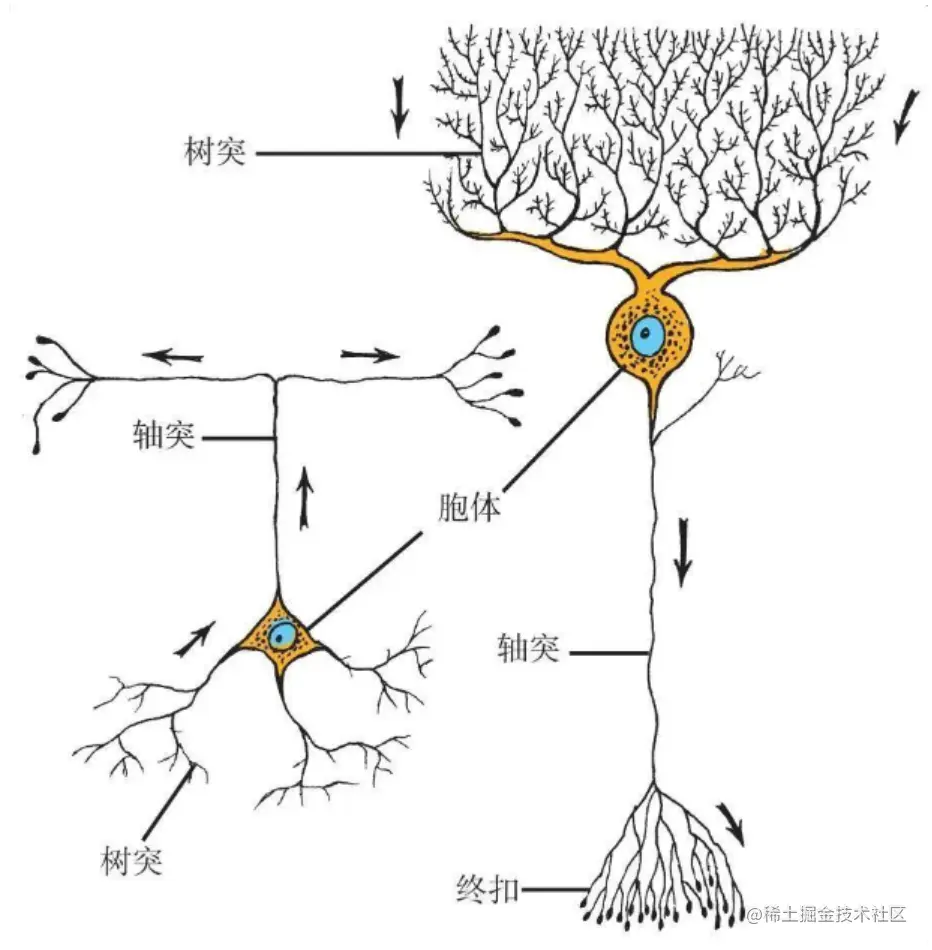
下面从功能角度,对生物神经元进行进行介绍:
-
神经信号的输入:
- 神经元的树突,负责接收其他神经元传来的神经信号,并传给胞体。
- 一个神经元通常有多个树突,即一个神经元可以接收来自多个神经元的输入。
-
神经元的激活:
-
神经信号的输出:
- 胞体被激活后,它会沿轴突向其它神经元发出神经信号。
- 轴突比树突长而细,也叫神经纤维,末端处有很多细的分支称为神经末梢,每一条神经末梢可以向四面八方传出信号,神经末梢和和另一个神经元进行通信的结构叫突触,用于输出神经元的神经信号。
- 需要注意的是,相同的同神经信号可能对接受它的不同神经元有不同的效果。这一效果主要由突触决定:突触的“联结强度”越大,接受的信号就越强,反之,就越弱。

【神经网络】
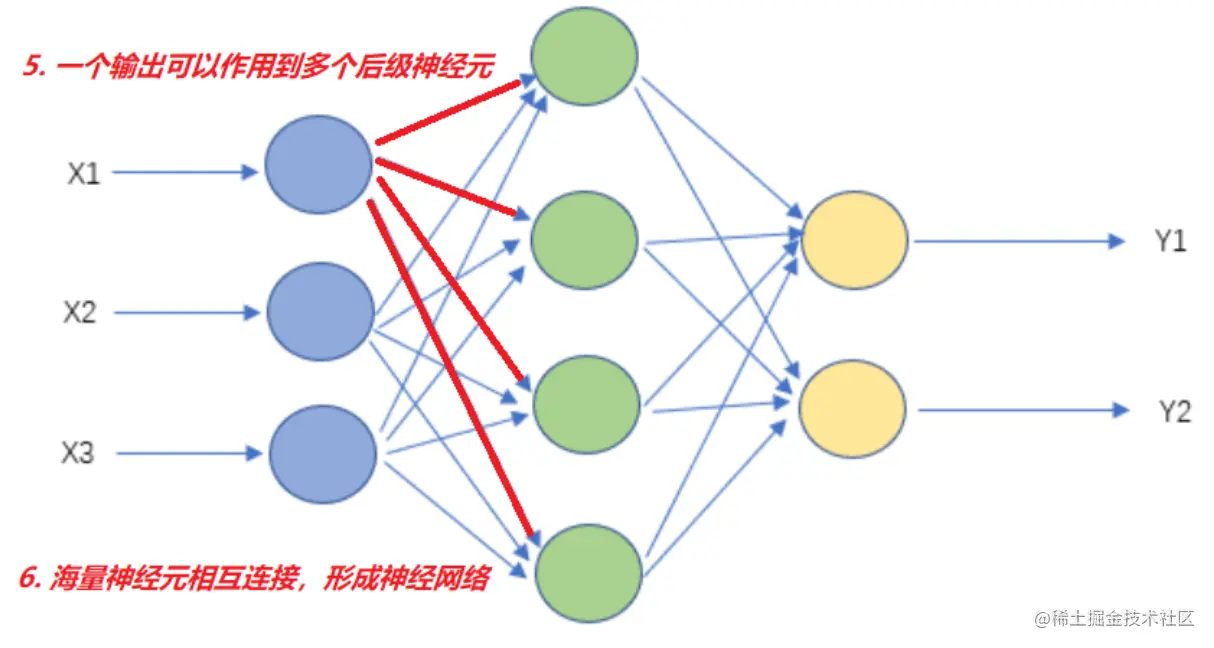
生物神经系统由大量神经元构成,每个神经元都可能连接到数千个其他神经元,这会形成一个复杂的神经网络。这个网络使得我们可以感知环境、思考、记忆、学习等。我们的每一个思想、感觉和行动都是由这种神经元间的连接和交流驱动的。
【知识学习】
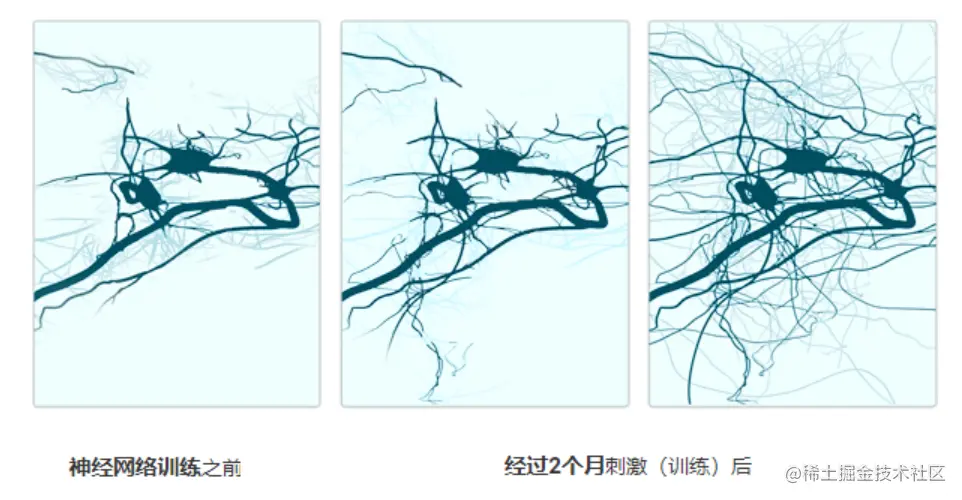
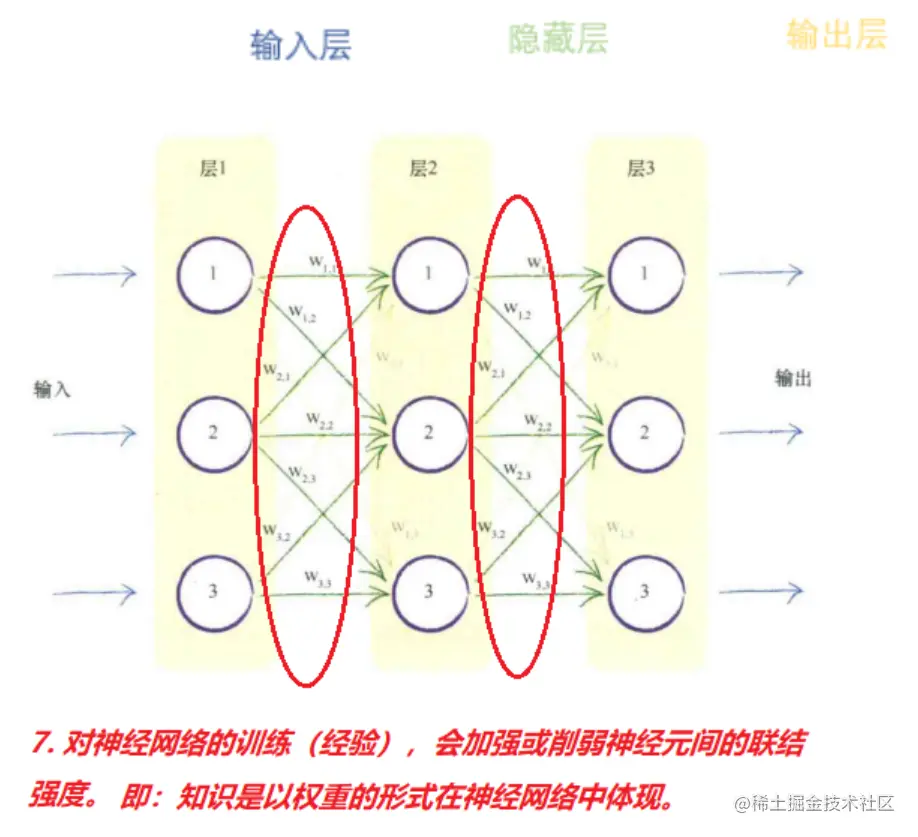
1949 年 Hebb 提出了突触学习的模型(Hebb定律)。该理论认为,神经网络是具有可塑性的,重复性的经验可以加强或削弱神经元间的连接,即:学习,在脑分子层次上,导致的是神经元间突触连接的变化。这使得我们的大脑可以适应新的信息、经历和学习。
人工神经网络
神经网络是一种对生物神经网络组织结构和运行机制的抽象、简化和模拟,以期能够实现类人工智能的机器学习技术。
下面还是从功能的角度,以对比的方式,描述人工神经网络如何实现对生物神经网络的抽象、简化和模拟。
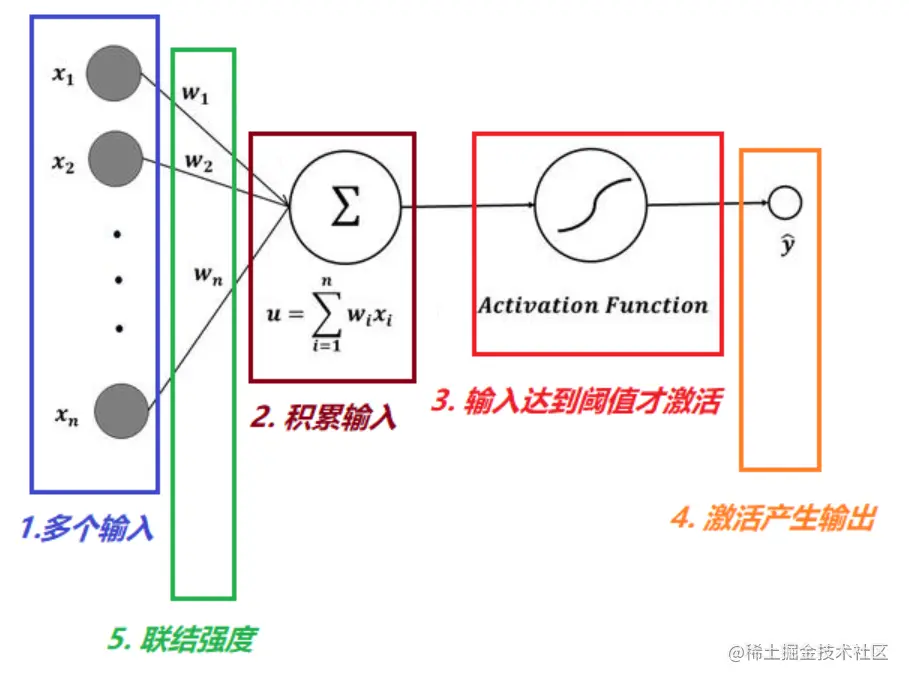
我们先对前面所讲的,生物神经元、神经网络最核心的特性,进行提炼:
- 神经信号的输入:
- 一个神经元可以接收来自多个神经元的输入。【核心1:多个输入】
- 神经元的激活:
- 神经元会积累输入的神经信号。【核心2:积累输入】
- 积累的神经信号,超过一个阈值,神经元才会被激活【核心3:输入超过阈值才激活】。
- 神经元的输出:
- 被激活的神经元,会沿着轴突发出神经信号。【核心4:激活后产生输出】
- 轴突的神经末梢会向四面八方传出信号。【核心5:一个输出可以作用到多个后级神经元】
- 相同的输出可能会对后级神经元产生不同的效果。【核心5:一个输出,可能会对不同的后级神经元,产生不同的影响】
- 【核心6:海量神经元相互连接,形成神经网络】。
- 【核心7:重复的经验可以加强、削弱神经元之间的联结强度。】。
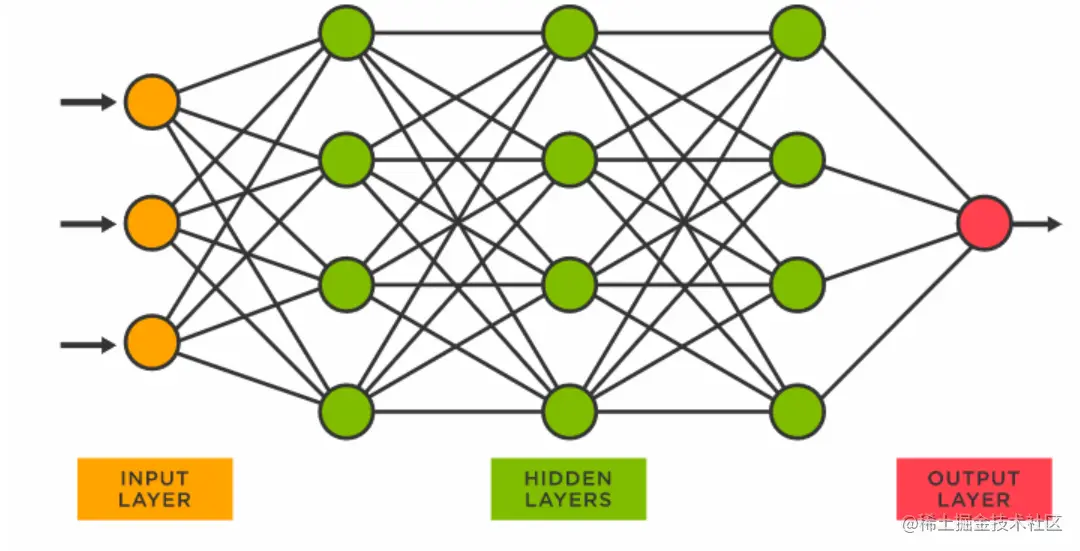
所以人工神经元的抽象模型,如下图所示:
运行
接下来,我们从运行的角度,描述人工神经网络是如何工作的。
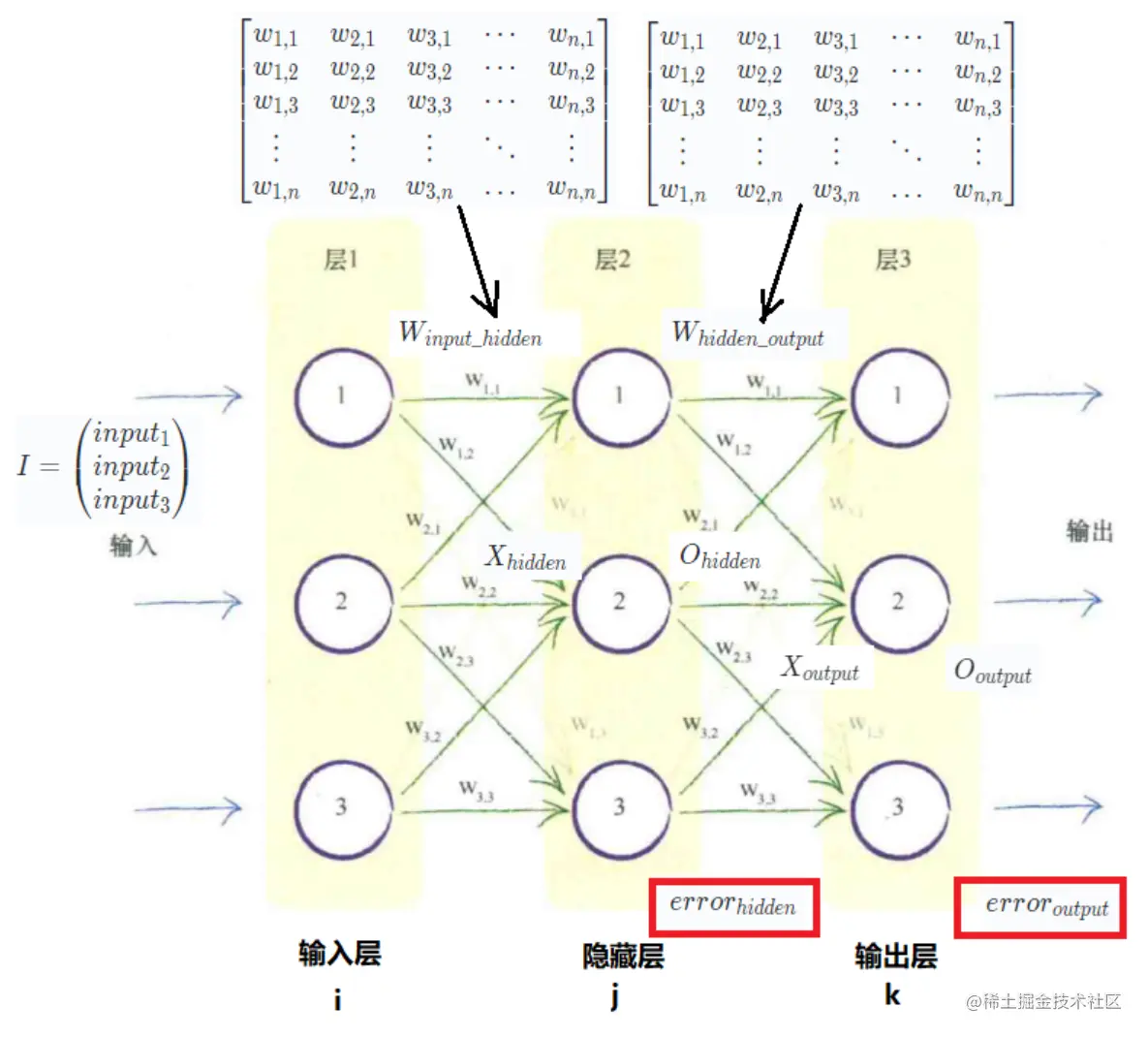
一些记号
由于后面几节中会反复使用一些记号,所以在这里把后面会用到的记号以及含义写在这里,方便查阅。
| 记号 | 含义 | 备注 |
|---|
| I=⎝⎛input1input2input3⎠⎞ | 输入信号 | |
| wi,j | 权重,前一层节点 i 与下一层节点 j 间的联结强度。 | |
| W=⎣⎡w1,1w1,2w1,3⋮w1,nw2,1w2,2w2,3⋮w2,nw3,1w3,2w3,3⋮w3,n⋯⋯⋯⋱…wn,1wn,2wn,3⋮wn,n⎦⎤ | 权重矩阵 | |
| WT= ⎣⎡w1,1w2,1w3,1⋮wn,1w1,2w2,2w3,2⋮wn,2w1,3w2,3w3,3⋮wn,3⋯⋯⋯⋱…w1,nw2,nw3,n⋮wn,n⎦⎤ | 权重矩阵的转置 | |
| sigmoid(x)=1+e−x1 | 激活函数 | |
| Winput_hidden | 输入层和隐藏层之间的权重矩阵 | |
| Xhidden | 隐藏层聚合后的输入 | |
| Ohidden=sigmoid(Xhidden) | 隐藏层的输出结果 | |
| Whidden_output | 隐藏层和输出层之间的权重矩阵 | |
| Xoutput | 输出层聚合后的输入 | |
| Ooutput=sigmoid(Xoutput) | 输出层的输出结果 | |
| erroroutput | 输出层误差 | |
| errorhidden | 隐藏层误差 | |
| ei=ti−oi | 误差 = 真是结果 - 输出结果 | |
| E=∑n(tn−on)2 | 神经网络误差函数 | |
| α | 学习率 | |
| ∂wij∂E | 权重变化时,网络误差的变化方式 | |
神经信号在网络中的正向传播
我们使用一个有3层、每层3个神经元的神经网络,讲解神经信号在神经网络中的正向传播过程。

第一步,计算隐藏层各神经元的神经信号输入。
- x1=input1∗w1,1+input2∗w2,1+input3∗w3,1
- x2=input1∗w1,2+input2∗w2,2+input3∗w3,2
- x3=input1∗w1,3+input2∗w2,3+input3∗w3,3
用矩阵来表达:
Xhidden=⎝⎛w1,1w1,2w1,3w2,1w2,2w2,3w3,1w3,2w3,3⎠⎞⋅I
再简化一下:
Xhidden=Winput_hidden⋅I
第二步:计算隐藏层各神经元的神经信号输出。
即,对隐藏层各神经单元的输入,施加激活函数sigmoid。
- o1=sigmoid(x1)
- o2=sigmoid(x2)
- o3=sigmoid(x3)
用矩阵来表达:
Ohidden=sigmoid(Xhidden)
同理:
第三步:输出层各神经元的神经信号输入为
Xoutput=Whidden_output⋅Ohidden
第四步:输出层各神经元的神经信号输出为
Ooutput=sigmoid(Xoutput)
以上就是神经信号在神经网络中的正向传播过程。
神经网络误差的反向传播
从这一节开始,就进入了神经网络的训练过程,即神经网络积累知识的过程。
上一节描述了,神经信号如何输入神经网络并得到输出的过程。从我们要做的事情“训练出一个人工神经网络,使它能够识别手写数字”角度说,我们最终的期望就是,把一张手写数字7的图片输入神经网络,神经网络的输出是数字7,把一张手写数字3的图片输入神经网络,神经网络的输出是数字3。
所谓“训练”,就是事先准备好一堆有正确答案的数据(比如:图1是3,图2是6,图2是9 ...),把这些数据和答案输入神经网络,让神经网络自己从这堆数据中把数据中潜藏的“知识”提炼出来,这些提炼出来的知识表现为神经网络中确定下来的权重。
由于还未经过训练的神经网络无法完成我们期望它做的事情(例如:输入手写数字3,输出是6;输入手写数字1,输出是9 ...)。也就是说,对于给定神经网络的输入,我们期望神经网络应该输出的结果 和 神经网络的实际输出结果之间存在误差。
所以,针对这个误差,我们要做的工作是:
- 将神经网络的输出误差反向传播到神经网络中的各个神经元上;
- 找到某种方式,能让我们利用这个误差来指导我们调整神经网络中的权重,以达到最小化神经网络输出误差的目的。
我们先解决第一个问题:将神经网络的输出误差反向传播到神经网络中的各个神经元上。
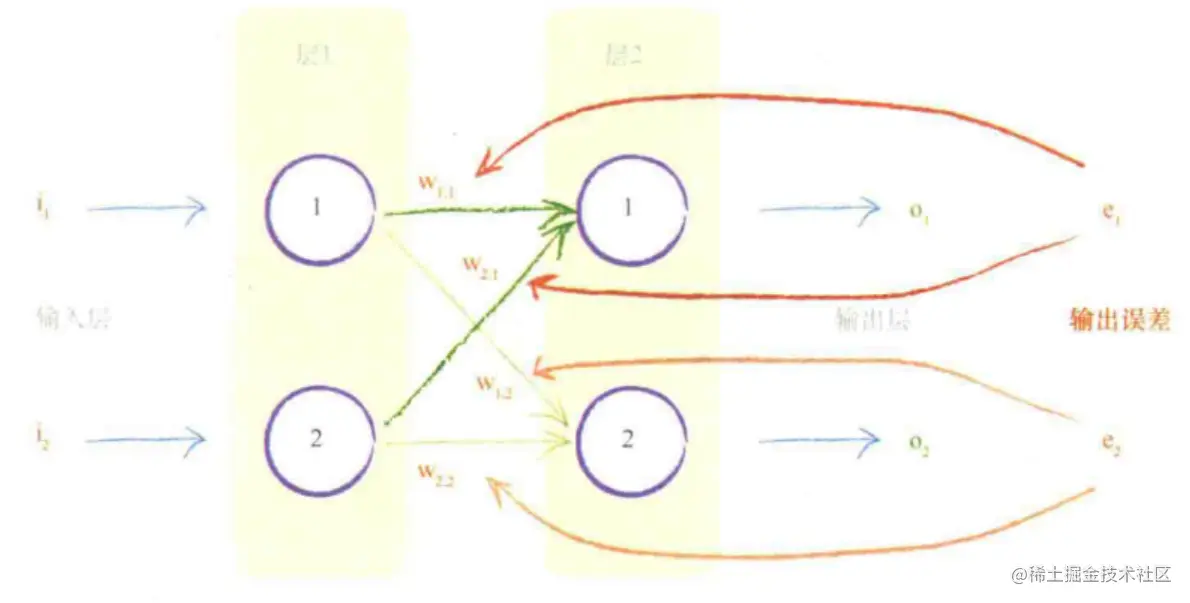
第一步,计算隐藏层各神经元的误差。
这里采用的是按照权重的比例,将误差反向传播到隐藏层的结点上。
- ehidden,1=w1,1+w2,1+w3,1w1,1∗eoutput,1+w1,2+w2,2+w3,2w1,2∗eoutput,2+w1,3+w2,3+w3,3w1,3∗eoutput,3
- ehidden,2=w1,1+w2,1+w3,1w2,1∗eoutput,1+w1,2+w2,2+w3,2w2,2∗eoutput,2+w1,3+w2,3+w3,3w2,3∗eoutput,3
- ehidden,3=w1,1+w2,1+w3,1w3,1∗eoutput,1+w1,2+w2,2+w3,2w3,2∗eoutput,2+w1,3+w2,3+w3,3w3,3∗eoutput,3
用矩阵来表达就是
errorhidden=⎝⎛w1,1+w2,1+w3,1w1,1w1,1+w2,1+w3,1w2,1w1,1+w2,1+w3,1w3,1w1,2+w2,2+w3,2w1,2w1,2+w2,2+w3,2w2,2w1,2+w2,2+w3,2w3,2w1,3+w2,3+w3,3w1,3w1,3+w2,3+w3,3w2,3w1,3+w2,3+w3,3w3,3⎠⎞⋅erroroutput
其实上面这个式子中,最重要的部分就是输出误差与链接权重 wi,j 的乘法,较大的权重就意味着携带较多的输出误差给隐藏层。这些分数的分母是一种归一化因子。如果我们忽略了这个因子,那么我们仅仅失去后馈误差的大小。也就是说,我们可以使用简单得多的 w1,1∗eoutput,1 来代替 w1,1+w2,1+w3,1w1,1∗eoutput,1。
这样矩阵演变为
errorhidden=⎝⎛w1,1w2,1w3,1w1,2w2,2w3,2w1,3w2,3w3,3⎠⎞⋅erroroutput
注意一下这个矩阵和权重矩阵的关系,可以得到,
errorhidden=Winput_outputT⋅erroroutput
至此,我们完成了神经网络输出误差的反向传播。
神经网络权重的调整
在完成了第一件事(即,将神经网络的输出误差反向传播到神经网络中的各个神经元上)后
我们再完成第二件事情(即,找到某种方式,能让我们利用这个误差来指导我们调整神经网络中的权重,以达到最小化神经网络输出误差的目的),就可以实现对神经网络的训练。
既然要让神经网络的输出误差最小,那么我们需要先构建神经网络的输出误差函数。
E=n∑(tn−on)2
ok=Sigmoid(j∑wj,k∗Sigmoid(i∑wi,j∗inputi))
Sigmoid(x)=1+e−x1
直接求误差函数的最小值很难,所以我们采用梯度下降法,以小步迭代的方式,找到目标函数(即我们的)的最小值。
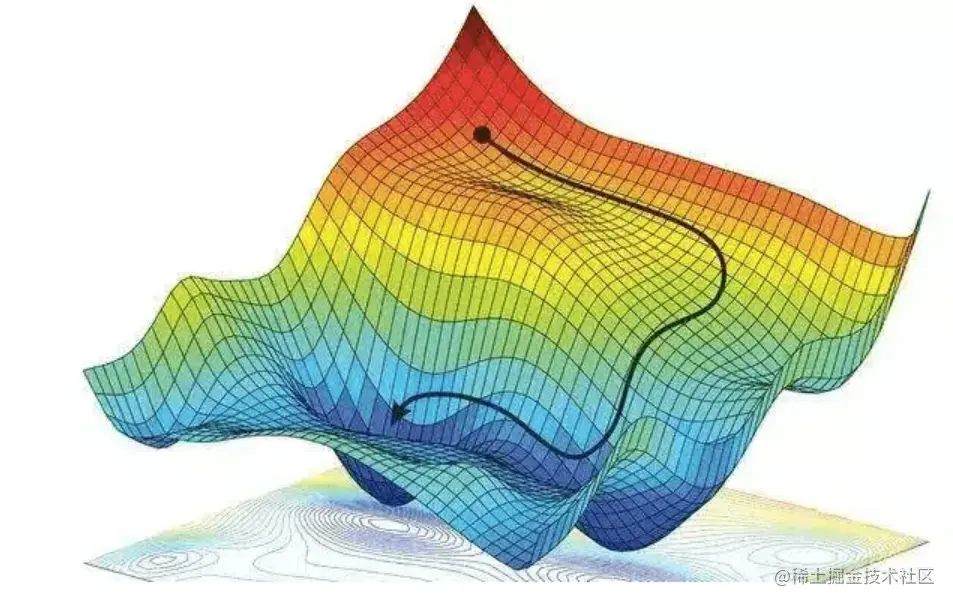
因为我们最终要实现通过调整权重 wij 找到误差函数 E 的最小值。
而采用“梯度下降法”后,这个问题就转变为:搞清楚“误差对链接权重的改变有多敏感?”。
所以我们的目标就变成了,求解
∂wj,k∂E
展开误差函数,得到:
∂wj,k∂E=∂wj,k∂∑n(tn−on)2
这是对目标值和实际值之差的平方进行求和,这是针对所有 n 个输出节点的和。
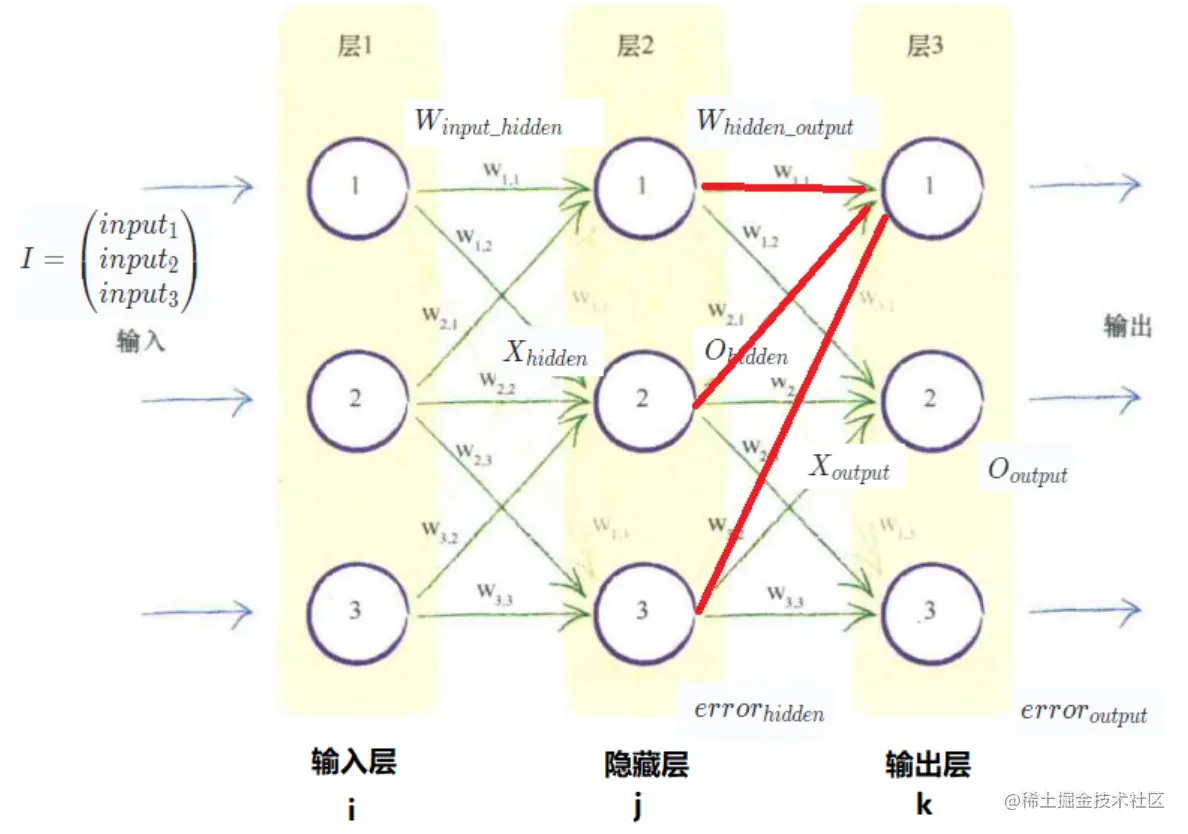
再仔细观察一下上面这张图,当权重 wj,k 发现变化的时候,其实只会影响到输出结点 ok,所以这个误差函数可以进一步简化为:
∂wj,k∂E=∂wj,k∂(tk−ok)2
利用链式法则,得到:
∂wj,k∂E=∂ok∂(tk−ok)2∗∂wj,k∂ok
∂wj,k∂E=−2(tk−ok)∗∂wj,k∂ok
展开 ok:
∂wj,k∂E=−2(tk−ok)∗∂wj,k∂sigmoid(∑wj,k∗oj)
由于:
∂x∂sigmoid(x)=sigmoid(x)(1−sigmoid(x))
所以:
∂wj,k∂E=−2(tk−ok)∗sigmoid(∑wj,k∗oj)∗(1−sigmoid(∑wj,k∗oj))∂wj,k∂∑wj,k∗oj=−2(tk−ok)∗sigmoid(∑wj,k∗oj)∗(1−sigmoid(∑wj,k∗oj))∗oj=−2(tk−ok)∗ok∗(1−ok)∗oj=−2ek∗ok∗(1−ok)∗oj
由于我们只对斜率的方向感兴趣,所以可以把 2 去掉:
∂wj,k∂E=−ek∗ok∗(1−ok)∗oj
所以,根据梯度下降的策略,权重 wj,k 应该这么调整:
wj,k_new=wj,k_old−α∗∂wj,k∂E
所以
Δwj,k=α∗ek∗ok∗(1−ok)∗oj
我们再从矩阵角度看,权重矩阵 Whidden_output 如何更新
⎝⎛Δw1,1Δw1,2Δw1,3Δw2,1Δw2,2Δw2,3Δw3,1Δw3,2Δw3,3⎠⎞=α⋅⎝⎛e1∗o1∗(1−o1)e2∗o2∗(1−o2)e3∗o3∗(1−o3)⎠⎞⋅(o1o2o3)
所以
ΔWj,k=α∗Ek∗Ok∗(1−Ok)⋅OjT
同理
ΔWi,j=α∗Ej∗Oj∗(1−Oj)⋅OiT
至此,我们就实现了通过前一层(j)的输出(Oj)、后一层(k)的输出(Ok)以及后一层的误差(Ek),微调神经网络两层(j、k)间权重(Wj,k),降低后一层(k)输出误差(Ek)的目的。
梳理一下
现在让我们把上面这一套流程串起来梳理一下,加深一下理解。
第1步:初始化神经网络
- 构建一个3层(输入层(i)、隐藏层(j)、输出层(k))、每层3个神经元的神经网络。
- 输入层、隐藏层间的权重(Winput_hidden)和隐藏层、输出层间的权重(Whidden_output)先赋随机值。
- 注:这时候,这个神经网络还干不了什么有意义的事情,只是一个随机的神经网络。
- 注:这些随机值将在后续的训练过程中得到逐步调整。
第2步:准备训练数据
- 准备 1000 张(只是举个例子)手写数字图片,并且我们知道这些图片对应的数字是多少(即:每一张图片都被标记了正确的答案)。
第3步:训练神经网络
- 拿出一张图片(假设:是一张手写数字 7 的图片)。
- 把这实际是 7 的手写数字图片,转换为神经网络的输入信号(I)输入神经网络,经过神经网络的正向传播,得到神经网络的输出信号(Ok)(假设:输出信号此时代表数字 3)。
- 根据神经网络的实际输出(3)和期望输出(7),计算出神经网络输出层(k)神经元的误差 Ek
- 将输出层误差(Ek)反向传播到隐藏层,得到隐藏层(j)神经元的误差 Ej
- 采用梯度下降法,使用隐藏层输出(Oj)、输出层输出(Ok)和输出层误差(Ek),对隐藏层、输出层间的权重(Whidden_output)进行一次微调(ΔWj,k=α∗Ek∗Ok∗(1−Ok)⋅OjT)。
- 采用梯度下降法,使用输入(Oi)、隐藏层输出(Oj)和隐藏层误差(Ej),对输入层、隐藏层间的权重(Winput_hidden)进行一次微调(ΔWi,j=α∗Ej∗Oj∗(1−Oj)⋅OiT)。
至此,就用一张图片,完成了一轮对神经网络的训练。也可以说,神经网络从这张图片中提取到了部分知识,体现在神经网络中的权重里。
那么,我们用这 1000 张图片,对神经网络训练 1000 轮,那么我们有理由相信,神经网络从这 1000 张图片中提取到了足够的知识,来完成手写数字图片的识别任务。😄
实战
下面使用 Python 把上述过程实现出来。
NeuralNetwork.py:神经网络
import scipy.special
class NeuralNetwork:
def __init__(self, input_nodes, hidden_nodes, output_nodes, learning_rate) -> None:
self.input_nodes = input_nodes
self.hidden_nodes = hidden_nodes
self.output_nodes = output_nodes
self.weight_input_hidden = np.random.normal(0.0, pow(self.hidden_nodes, -0.5), (self.hidden_nodes, self.input_nodes))
self.weight_hidden_output = np.random.normal(0.0, pow(self.output_nodes, -0.5), (self.output_nodes, self.hidden_nodes))
self.learning_rate = learning_rate
self.activation_function = lambda x: scipy.special.expit(x)
pass
def train(self, input_list, target_list):
inputs = np.array(input_list, ndmin=2).T
targets = np.array(target_list, ndmin=2).T
hidden_inputs = np.dot(self.weight_input_hidden, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.weight_hidden_output, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
output_errors = targets - final_outputs
hidden_errors = np.dot(self.weight_hidden_output.T, output_errors)
self.weight_hidden_output += self.learning_rate * np.dot(output_errors * final_outputs * (1.0 - final_outputs), np.transpose(hidden_outputs))
self.weight_input_hidden += self.learning_rate * np.dot(hidden_errors * hidden_outputs * (1.0 - hidden_outputs), np.transpose(inputs))
pass
def query(self, input_list):
inputs = np.array(input_list, ndmin=2).T
hidden_inputs = np.dot(self.weight_input_hidden, inputs)
hidden_outputs = self.activation_function(hidden_inputs)
final_inputs = np.dot(self.weight_hidden_output, hidden_outputs)
final_outputs = self.activation_function(final_inputs)
return final_outputs
main.py:神经网络训练与测试:
import numpy as np
import matplotlib.pyplot
import pylab
from NeuralNetwork import *
input_nodes = 784
hidden_nodes = 100
output_nodes = 10
learning_rate = 0.1
n = NeuralNetwork(input_nodes, hidden_nodes, output_nodes, learning_rate)
training_data_file = open("mnist_train.csv", 'r')
training_data_list = training_data_file.readlines()
training_data_file.close()
epochs = 5
total_progress = 5 * len(training_data_list)
current_progress = 0
for e in range(epochs):
for record in training_data_list:
all_values = record.split(',')
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
targets = np.zeros(output_nodes) + 0.01
targets[int(all_values[0])] = 0.99
n.train(inputs, targets)
current_progress += 1
print("\rtraining progress: {:3}%".format((current_progress / total_progress) * 100), end="")
pass
pass
test_data_file = open("mnist_test.csv", 'r')
test_data_list = test_data_file.readlines()
test_data_file.close()
scorecard = []
for record in test_data_list:
all_values = record.split(',')
correct_label = int(all_values[0])
inputs = (np.asfarray(all_values[1:]) / 255.0 * 0.99) + 0.01
outputs = n.query(inputs)
label = np.argmax(outputs)
if (label == correct_label):
scorecard.append(1)
else:
scorecard.append(0)
pass
scorecard_array = np.asarray(scorecard)
print ("\nperformance = ", scorecard_array.sum() / scorecard_array.size)
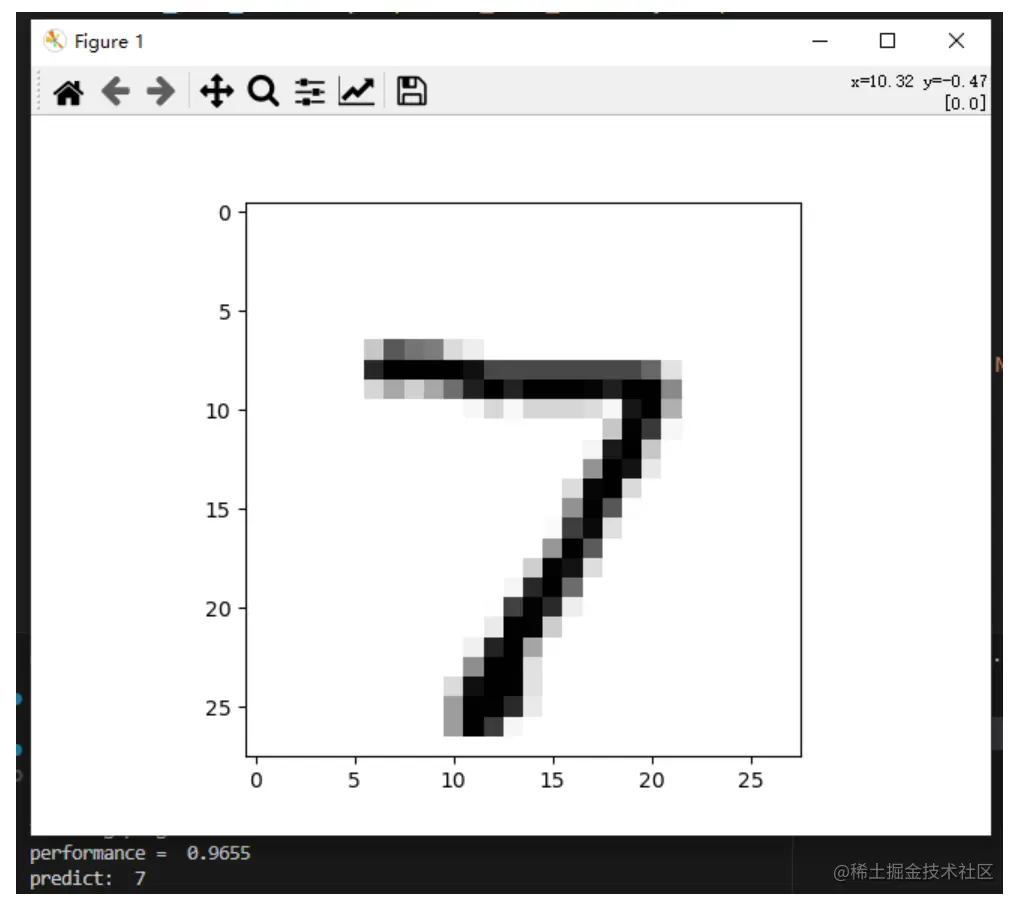
参考
《Python神经网络编程》
MNIST in CSV:pjreddie.com/projects/mn…
THE MNIST DATABASE of handwritten digits:yann.lecun.com/exdb/mnist/
NN-SVG:alexlenail.me/NN-SVG/LeNe…
NeuroMorpho.Org:neuromorpho.org/



