

金仓数据库KingbaseES 读写分离集群-状态管理
关键字:
KingbaseES、集群管理、集群状态检查
一、集群状态信息
集群故障、节点故障、网络故障和部分人为错误、资源耗尽问题都会表现出集群状态异常,集群状态信息是监控中重要的监控项。
1.1 节点状态
在存活的数据库节点执行(当前数据库故障则无法查看状态)
repmgr cluster show
图例:

告警值:
status列不是running状态
upstream 列,不是级联复制情况下不是primary 的node_name不同节点获得的数据不同
1.2 守护进程状态
在存活的数据库节点执行(当前数据库故障则无法查看状态)
repmgr service status
图例:

告警值:
repmgrd列,不是running状态
2.1.3 流复制状态
ksql连接数据库执行(连接主库查询)
查询流复制信息:
SELECT * FROM sys_stat_replication;
图例:

查询主备流复制差距: select sys_wal_lsn_diff(sys_current_wal_flush_lsn(), replay_lsn) as lsn_lag, * from sys_stat_replication;
图例:

告警值:
state列值不为streaming
sync_state列和预期不符(配置的同步方式)
复制差距超过预设值
1.4复制槽状态
ksql连接数据库执行(连接主库或备库查询)
复制槽信息:
SELECT * FROM sys_replication_slots;
图例:

告警值:
主库复制槽个数、slot_type列值或active列值为预期外
二、集群状态基础切换
2.1集群启停
集群的启停通常有两种方式:一键启停和单个节点独立启停。
2.1.1一键启停方式
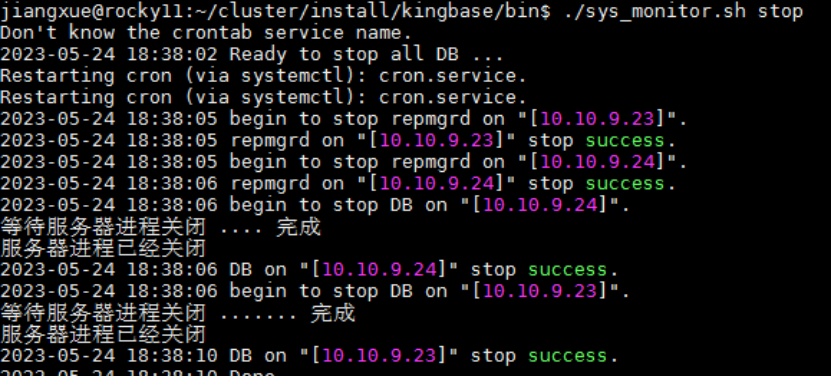
集群一键停止
$bin_path/sys_monitor.sh stop
图例:
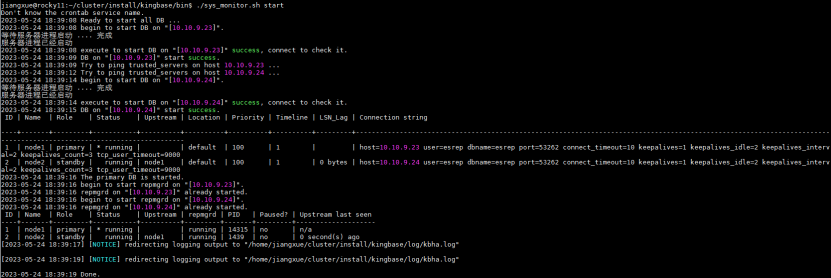
集群一键启动
$bin_path/sys_monitor.sh start
图例:
2.1.2手动启停方式
手动启动:
需要按照步骤手动启动集群中所有数据库以及守护进程。
a.首先启动所有数据库节点,在启动前需要检查所有数据库状态,保证不能有多主。
sys_ctl -D $data_directory -l logfile start
b.然后启动所有节点的 repmgrd 守护进程。
repmgrd -d -v -f $rep_conf
c.启动所有节点的 kbha 守护进程。
kbha -A daemon -f $rep_conf
d.最后,在所有节点使用 root 用户添加 CRON 任务。
#在文件/etc/cron.d/KINGBASECRON(如果没有请创建)中写入语句:
** 1 * * * * $user . /etc/profile;$bin_path/kbha -A daemon -f $rep_conf
手动停止:
需要按照步骤手动停止所有守护进程以及数据库。
a.首先,在所有节点使用 root 用户注释或删除 CRON 任务。
# 在文件/etc/cron.d/KINGBASECRON 注释(句首使用 #)以下语句:
#* 1 * * * * $user . /etc/profile;$bin_path/kbha -A daemon -f $rep_conf
b.其次,关闭或杀掉所有节点的守护进程 kbha 和 repmgrd。
# 一定先关闭 kbha 进程 kill -9 pidof kbha repmgrd
c.最后停止所有数据库节点。
sys_ctl -D $data_directory -l logfile stop
2.2集群主备切换
集群主备切换时指主动让主备角色互换,这种场景和故障自动转移的情况有所不同。自动故障转移是主库故障 后,备库升主以替代原主库,这个流程是意外发生、不受控制的。而主备切换一般是在运维过程中由运维人员手动触 发的,使主备角色互换。
在需升主备机节点执行:
$bin_path/repmgr standby switchover
切换示例:
- 最初 primary 节点是 node1

- 选择 node2 为新的 primary。在 node2 运行切换命令,如下所示:
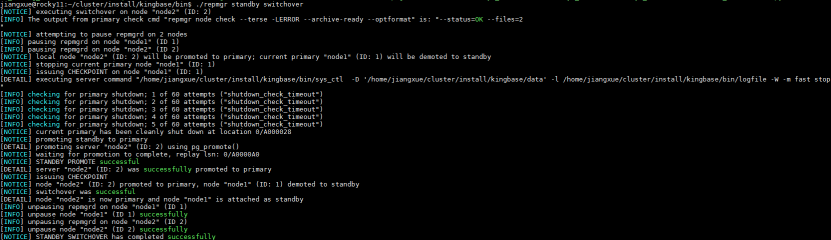
- 切换结果验证

三、故障恢复至集群
一般情况下,故障数据库会由守护进程将其作为备库恢复至集群。但如果故障为主库,默认情况(recovery=standby)下是不会自动将其恢复为备库的,另外,如果用户关闭了自动恢复功能(recovery=manual)或者暂 停了集群(repmgr service pause),那么任何故障数据库都不会自动恢复至集群,这时就需要运维人员手动操作将 故障数据库恢复至集群。
命令行命令:
# 在故障的数据库节点执行
repmgr node rejoin -h ${主库 IP} -d esrep -U esrep -p ${主库 port} [--force-rewind] [--no-check-wal]
# 可以执行简化后的命令
kbha -A rejoin -h ${主库 IP}
参数说明: --force-rewind,当故障数据库和当前主库数据分歧后,需要指定此参数使用 sys_rewind 使得故障数据库 和新主库保持数据一致; —no-check-wal,一般情况下不允许时间线高的数据库恢复为时间线低的主库的备库,此选项可以忽略时 间线和 lsn 检查,必须和--force-rewind 一起使用;
四、总结
1、集群状态信息是监控中重要的监控项,可通过不同维度的集群状态信息查看确认集群的运行情况
2、集群可一键启停及一键切换 更多信息,参见help.kingbase.com.cn/v8/index.ht…
