If we have a neural network with only 1 hidden layer and 1 output layer, the structure is as follows:
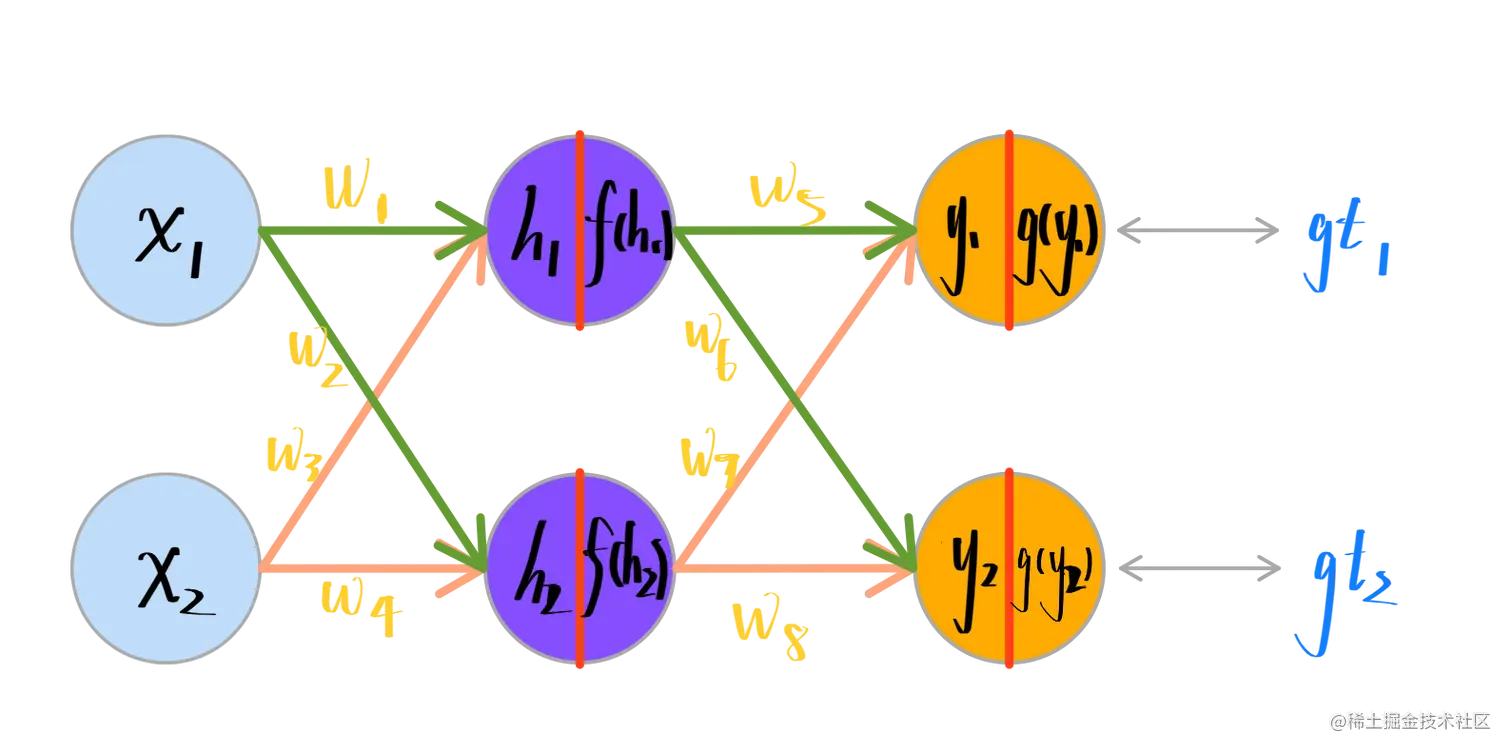 so the forward path of g(y1) is as equation below:
output: f(y1)
so the forward path of g(y1) is as equation below:
output: f(y1)
y1=w5f(h1)+w7f(h2)h1=w1x1+w3x2
So the error of the f(y1) is denoted as: Error(y1)=2(gt1−g(y1))2
So the back-propagation for w5 is as follows based on the chain rule:
∂w5∂Error(y1)=∂f(yy1)∂Error(y1)×∂y1∂f(y1)×∂w5∂y1
When we got the real value of ∂w5∂Error, we can update the weight w5:
w5+=w5−η∂w5∂Error(y1)
This is as same as w6:
w6+=w6−η∂w6∂Error(y2)
Furthermore, the back-propagation for w1 is as follows:
∂w1∂ Error =∂w1∂Error(y1)+∂w1∂Error(y2)=∂g(y1)∂Error(y1)∂y1∂(y1)∂f(h1)∂y1∂h1∂f(h1)∂w1∂h1+∂g(y2)∂Error(y2)∂y2∂(y2)∂f(h1)∂y2∂h1∂f(h1)∂w1∂h1
So we can update the w1 by the gradient:
w1+=w1−η∂w1∂ Error 

