Adam(Adaptive Moment Estimation)
Adam是常见的优化深度神经网络的最优化方法,普通的最优化方法(比如BGD,SGD)面对更为复杂的代价函数往往会陷入局部震荡或者陷入鞍点,难以收敛。于是便引入了 动量(Momentum) 这种物理学概念,让优化方向不只沿着梯度方向进行,还需要参考参数之前一步的运动方向。
SGD with Momentum
对于一个代价函数 L(wi) 来说,普通的 SGD 算法的某一步只需要沿着某一个方向前进一步:
wi:=wi−η∂wi∂L
带有动量的 SGD 算法则引入了速度的变化。令 wt 为 第 t 次后迭代的参数的值,Δwt 是算上学习率 η,w 在本次迭代中沿着负梯度方向应该前进的方向与大小,即:
Δwt=−η∇L(w)
则带有动量的 SGD 算法的迭代公式为:
vt+1=γvt+Δwtwt+1=wt+vt+1
其中 γ 为速度的衰减系数,一般为 0.9。
可以将这种方法比作一个斜坡上的小球,斜坡越陡,他的加速度越大,他的下降也就越快。所以带有动量的 SGD 算法会加速收敛,同时也可以有效的减少参数陷入鞍点的问题,但在优化过程中还有一些震荡的现象。
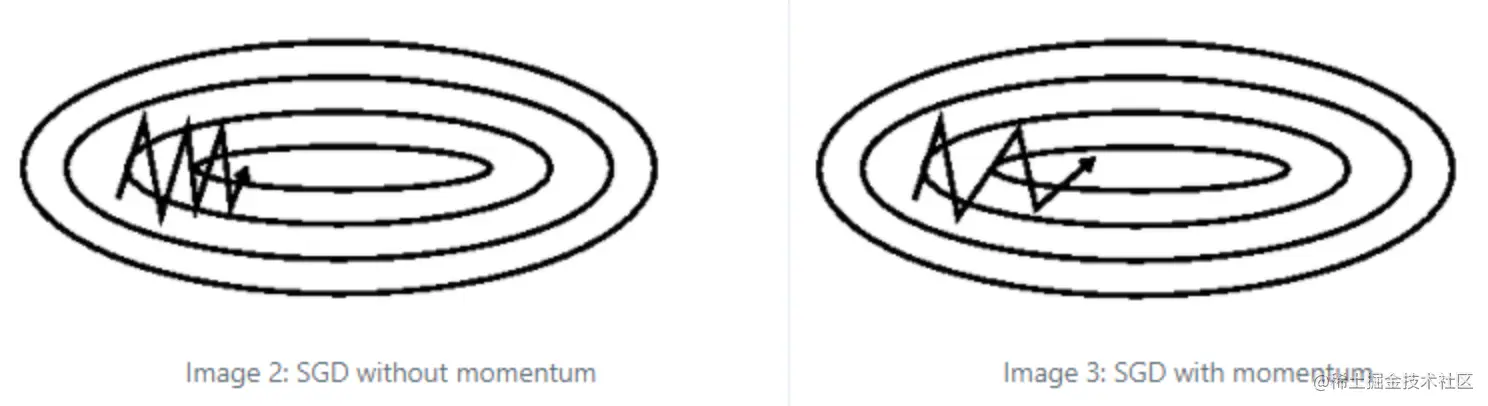
NAG(Nesterov Accelerated Gradient)
带有动量的 SGD 算法似乎是先计算梯度,再累积速度,这样很有可能会导致下降过头而导致震荡,NAG 算法则与 SGD 算法相反,先预见性的看见了自己之后的位置 wt′,再进行梯度计算,这样相当于走了两步:
wt′=wt+γvtΔwt=−η∇L(wt′)vt+1=γvt+Δwtwt+1=wt+vt+1
根据这篇 博文 的结论,这种走了两步这种方法更像牛顿法的前瞻性,因此比带有动量的 SGD 算法的震荡更小,但 η∇L(wt′) 计算会出现问题,需要更多的数学技巧来解决。
Adagrad
通常在深度网络训练到一定程度时,当前的学习率相对与代价函数来说太大以至于不能继续收敛,于是需要手动减小学习率 η,而 Adagrad 则是一种可以自动调节学习率大小的优化算法。
假设有一组待优化的参数 w={w1,w2,...,wn},则参数 wi 的梯度方向为:
Δwi=∇wiL(w)
那么迭代方程如下:
wi:=wi−gi+ϵηΔwi
其中 gi 储存着历史梯度 ∇wiL(w) 平方和,即:
gi=∑t∇wiL(w(t))2
可以看出 gi 随着训练逐渐递增,则其学习率会逐渐变小,实现了自适应调节学习率。同时,学习率的变化也会与参数直接挂钩,在同一问题中出现次数少的特征优化速率会比出现次数多的特征快得多。
但是这种方法会导致在学习一定时间后学习率会变得无限小,在数据过多或者 batch 较小时,累积的梯度平方和会将优化将陷入停滞。
RMSProp
比起累计历史梯度平方和 gi,RMSProp 算法将其替换为历史梯度平方和的期望。与动量的累积相似,在 t 时刻的梯度期望(或者说指数衰减的平均)的更新公式为:
E(∇wiL(w(t))2)=γE(∇wiL(w(t−1))2)+(1−γ)∇wiL(w(t))2
可以看到经过一段时间的衰减,离现在时间距离远的梯度信息会慢慢减小,越靠近当前时间,梯度信息占比越大。
上式的期望与动量有什么区别呢?我觉得除了换了一种赋权方式和从梯度转变为了梯度和之外没什么区别。
那么与 Adagrad 算法相似,最终的迭代方程为:
wi:=wi−E(∇wiL(w)2)+ϵηΔwi
通常 γ=0.9
AdaDelta
AdaDelta 算法与上面的 RMSProp 算法同时被提出。AdaDelta 算法不再拥有学习率,而是将他替换成为
wi:=wi−E(∇wiL(w)2)+ϵE(x)+ϵΔwi
其中
E(x(t+1))=γE(x(t))+(1−γ)(E(∇wiL(w)2)+ϵE(x(t))+ϵΔwi2)
这样 AdaDelta 算法就不需要依赖全局学习率而做到真正的自适应啦!
Adam
Adam 采用了一阶梯度矩估计与二阶梯度矩估计的指数衰减均值 mi(t),vi(t) 作为计算梯度均值于方差的手段,其中
mi(t)=β1mi(t−1)+(1−β1)∇L(wi)vi(t)=β2vi(t−1)+(1−β2)∇2L(wi)
mi(t) 可以理解为带有动量的梯度方向,而 vi(t) 来自于 RMSProp 算法,用来调节自适应优化的大小。
在算法的启动阶段,会另 mi(0),vi(0)=0,这会导致在开始优化时 mi(0),vi(0) 值过小,难以启动。则引入偏差修正:
m^i(t)=1−β1tmi(t)v^i(t)=1−β2tvi(t)
最终的迭代过程为:
wi(t+1)=wi(t)−v^i(t)+ϵηmi(t)
为什么需要偏差修正呢?当优化刚刚开始时,假设我们得到初始下降梯度 ∇L(wi) ,由于 mi(0)=0,mi(1)=0.1×∇L(wi),则会使初始优化步长缩小很多,可能会导致优化效果出现偏差,于是需要乘以一个系数来修正这种算法来修正在开始优化时出现的偏差。
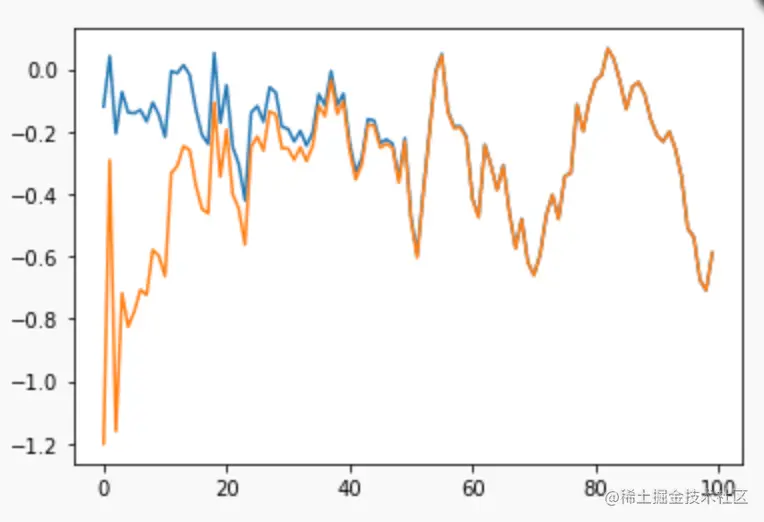
如图,黄色的曲线就是没有偏差修正的结果,在前期会与蓝色曲线(E(∇L(w)))产生较大偏差。
我们分解 m(t),可以得到:
m(t)=(1−β1)i=1∑tβ1t−i∇L(w(i))
求 m(t) 期望 E(m(t)):
E(m(t))=E((1−β1)i=1∑tβ1t−i∇L(w(i)))=(1−β1)(β1t−1E(∇L(w(1))+β1t−2E(∇L(w(2))+⋯+E(∇L(w(t)))=(1−β1)(β1t−1E(∇L(w)+β1t−2E(∇L(w))+⋯+E(∇L(w))=(1−β1)(1+β1+β12+⋯+β1t−1)E(∇L(w))=(1−β1t)E(∇L(w))
所以,m 是一阶梯度的有偏估计,同理,v 是二阶梯度的有偏估计,而随着迭代步数的增加,两者的偏差会越来越小,采用偏差修正会减小因为偏差在优化开始时对迭代方向的干扰。
reference:
1 、2 、3


