阿里ComiRec
论文地址:dl.acm.org/doi/pdf/10.…
git地址:github.com/THUDM/ComiR…
阿里的ComiRec是对多兴趣召回的一个阶段性总结。
多兴趣抽取模块总结了2种方法:一个是之前应用到MIND的Capsule Network,一个是Self-Attention
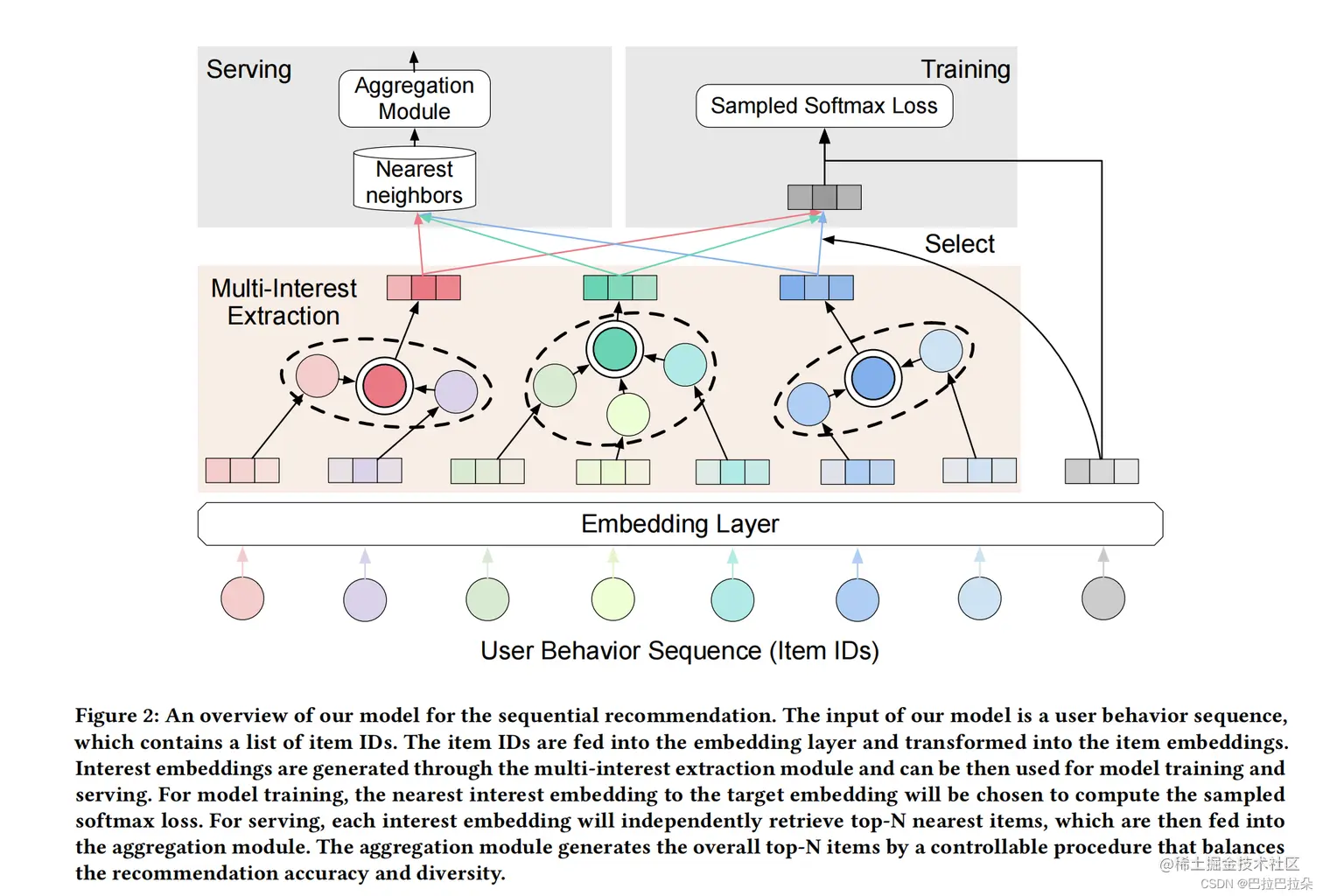 对于Self-Attention方法,给定用户行为序列Embedding H∈Rd×n,d是兴趣向量维度,n是用户的序列长度(sequence-length),attention的权重向量计算如下
对于Self-Attention方法,给定用户行为序列Embedding H∈Rd×n,d是兴趣向量维度,n是用户的序列长度(sequence-length),attention的权重向量计算如下
a = softmax(w2Ttanh(W1H)) ∈Rn
W1∈Rda×d , w2∈Rda×1
权重求出来后,应用到用户序列Embedding上面,就得到用户的Embedding
vu=Ha∈Rn
为了表示多个用户兴趣,将w2的维度扩展K倍,变成矩阵W2∈Rda×K
注意力权重向量变成了注意力权重矩阵
A = softmax(W2tanh(W1H)) ∈Rn×K
Vu=HA ∈Rn×d
模型训练
计算出用户的多个兴趣Embedding之后,根据目标item的Embedding ei,使用argmax操作来确定最终的用户Embedding
vu=Vu[:,argmax(VuTei)]
损失函数
loss=∑u∈U∑i∈Iu−logPθ(i∣u)
Pθ(i∣u)=∑i∈Iuexp(vuTei)exp(vuTei)
合并策略
每个兴趣Embedding都可以检索出topN个最相关的候选物料,如何合并K个兴趣Embedding的结果,一种简单的做法是对于同时出现在多个兴趣Embedding相似结果的物料,其最终打分可以用max/sum等策略来解决,max策略比较强调某一个兴趣的单一相似度,sum强调多个兴趣总的相似度。论文基于max策略结合类目多样性限制提出了一个新的合并策略。
首先max分数结果如下,vu(k)是是第k个用户兴趣向量
f(u,i)=x∈Smax(eiTvu(k))
设S是K个兴趣Embedding检索到的候选集去重后的数量,Q(u,S)表示结合max策略和类目多样性的打分结果
Q(u,S)=f(u,i)+λ∑i∈S∑j∈Sg(i,j)
其中g(i,j)=δ(CATE(i)=CATE(j))表示类目多样性,λ=0表示只要准确性,不要多样性,λ=∞表示要推荐最多样化类目的候选给用户
评估指标
I^u,N表示topN候选结果集合,Iu表示测试集用户u真实的交互物料集合
Recall 表示每个用户的平均准确率
Recall@N=∣U∣1∑u∈U∣Iu∣∣I^u,N⋂Iu∣
Hit Rate表示topN推荐结果中至少包含一个测试集用户u真实交互物料的比例
HR@N=∣U∣1∑u∈Uδ(∣I^u,N⋂Iu∣>0)
NDCG考虑了推荐结果的位置
NDCG@N=Z1NCG@N=Z1∣U∣1∑u∈U∑k=1Klog2(k+1)δ(i^u,k∈Iu)
兴趣提取模块究竟是capsule还是self-attention好要看实际业务场景,不同场景应用可能结果不同


