显式利用用户画像的多兴趣建模
目前在多兴趣建模中,用户侧的特征包括用户基础画像特征(年龄、性别、地域等)、用户在当前场景的静态兴趣画像特征(短期兴趣画像、长期兴趣画像)、交互的历史正向行为序列特征(正向物料id序列、正向物料类目序列、正向行为间隔序列等)。不论是基础画像、静态兴趣画像,都称为用户画像,经过Embedding层之后,与用户序列特征经过兴趣编码层提取后的兴趣Embedding拼接后进入最后的MLP。这里直接简单的拼接应该有更有效的方式来处理,有一篇paper使用attention的方式较好的结合了兴趣Embedding和用户画像Embedding。
论文地址:dl.acm.org/doi/pdf/10.…
整体结构
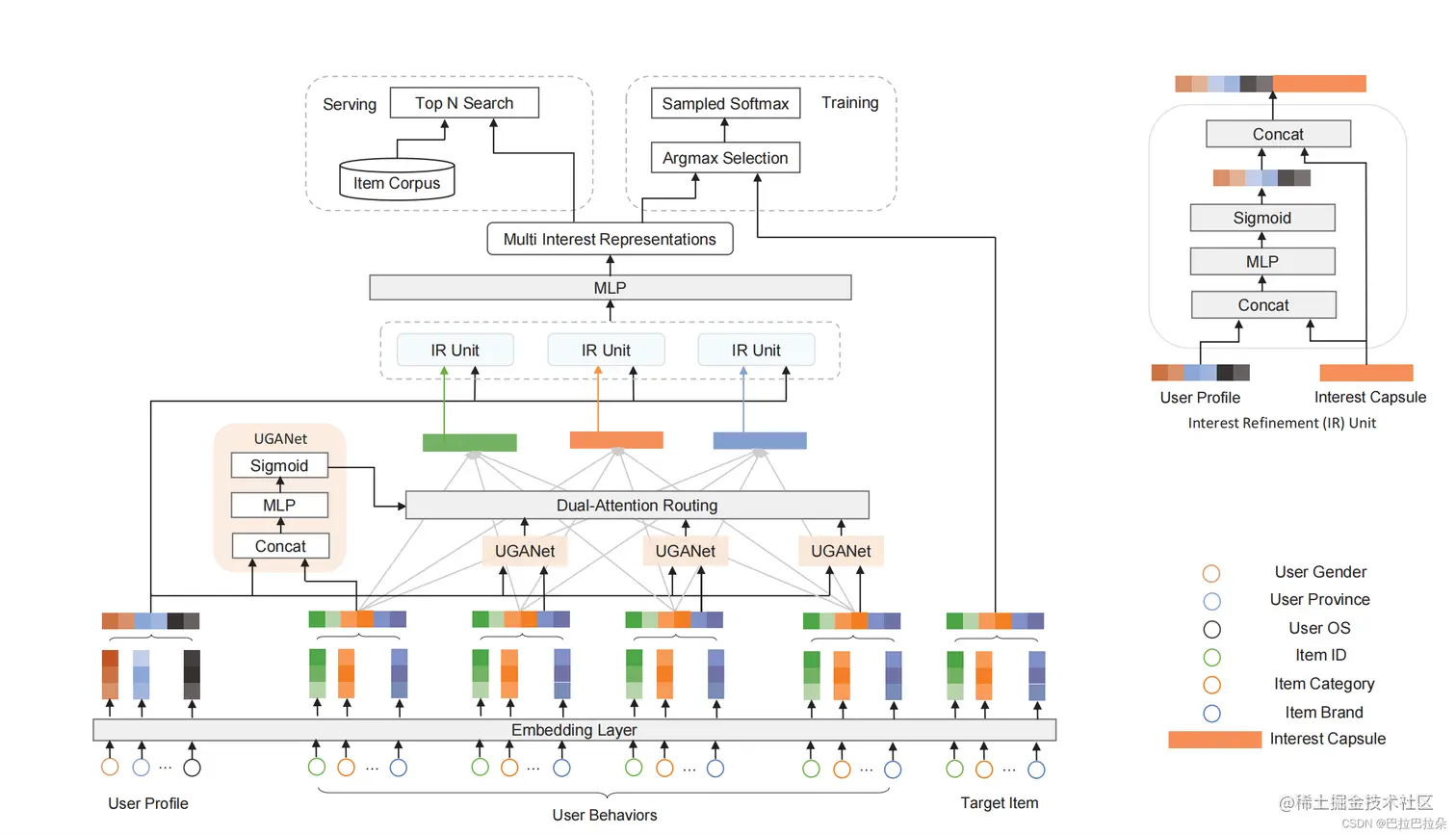
多兴趣编码前
用户序列在输出多兴趣编码层之前,对序列每个正向行为的Embedding和用户画像计算attention分数,即计算每个正向行为和用户画像的相关性。然后attention分数乘到行为的Embedding上面,即对用户画像相关程度高的行为进行强化,对用户还行相关程度低的行为降权弱化,这个操作类似于对用户序列进行去噪。
其中计算attention分数的方式如下,这里也是用到了一个网络,论文中称为user-guided attention Network,ei是用户序列Embedding,eu是用户画像Embedding,[ei,eu]表示用户画像Embedding和行为Embedding拼接成一个Embedding,WiT是学习的参数,ai是attention分数。
ai=sigmoid(W2TReLU(W1T[ei,eu]+b1)+b2)
计算出的attention分数再乘回到序列Embedding上面,作为兴趣编码层的输入(如果是capsule编码,则计算方式如下)
zj=∑i=1TaicijWjej
多兴趣编码后
经过多兴趣编码之后,产生的多个兴趣向量,需要再度与用户画像进行兴趣精调,即用产生的兴趣向量和用户画像向量再次计算相关性,对相关性高的兴趣进行强化。论文中称这部分为IR Unit。
假设编码出了K个兴趣向量,vk表示一个兴趣向量,eu表示用户画像Embedding,ok表示最终的兴趣向量。精调过程如下
ok=MLP([ok,eu]) k=1,2,...,K
不得不说,利用用户画像的这个方式挺有效的。兴趣编码之前,对每个行为序列根据用户画像进行去噪提纯;兴趣编码之后,对每个兴趣向量根据用户画像进行精调。
其他策略
这个paper还提出了一个hard negetive策略
使用argmax从用户兴趣向量池Ou中选择出和目标物料et最匹配的兴趣向量ok
ok=Ou[argmax(OuTet)]
那么基于这个用户兴趣ok,最可能的交互物料xt可以由最大化p(xt∣u)得到
p(xt∣u)=∑j∈Iexp(okTej)exp(okTet)
这里面兴趣向量ok是和正向物料xt最相关的,计算负样本中的xj的相关性也是用这个兴趣向量来计算的,训练和推断时有个较大的gap,因为ok和目标物料xt明显相关,但是和其他物料xt明显无关。因此可以构造hard negetive,argmax操作不仅仅包括正向物料,也报告负向物料,即选出每个物料最相关的兴趣向量,不论这个物料是正向的还是负向的。
ok(q)=Ou[argmax(OuTeq)]
p(xt∣u)=∑j∈Iexp((ok(j))Tej)exp((ok(t))Tet)
损失函数如下:
L=∑u∈U∑xt∈Iu−log(p(xt∣u))


