1.递归神经网络
当使用前馈神经网络时,神经网络会认为我们t时刻输入的内容与t-1时刻输入的内容完全无关,对于许多情况,例如图片分类识别,这是毫无问题的,可是对于一些情景,例如自然语言处理 (NLP, Natural Language Processing) 或者我们需要分析类似于连拍照片这样的数据时,合理运用t或之前的输入来处理t+n时刻显然可以更加合理的运用输入的信息。为了运用到时间维度上信息,人们设计了递归神经网络 (RNN, Recurssion Neural Network),一个简单的递归神经网络可以用这种方式表示。
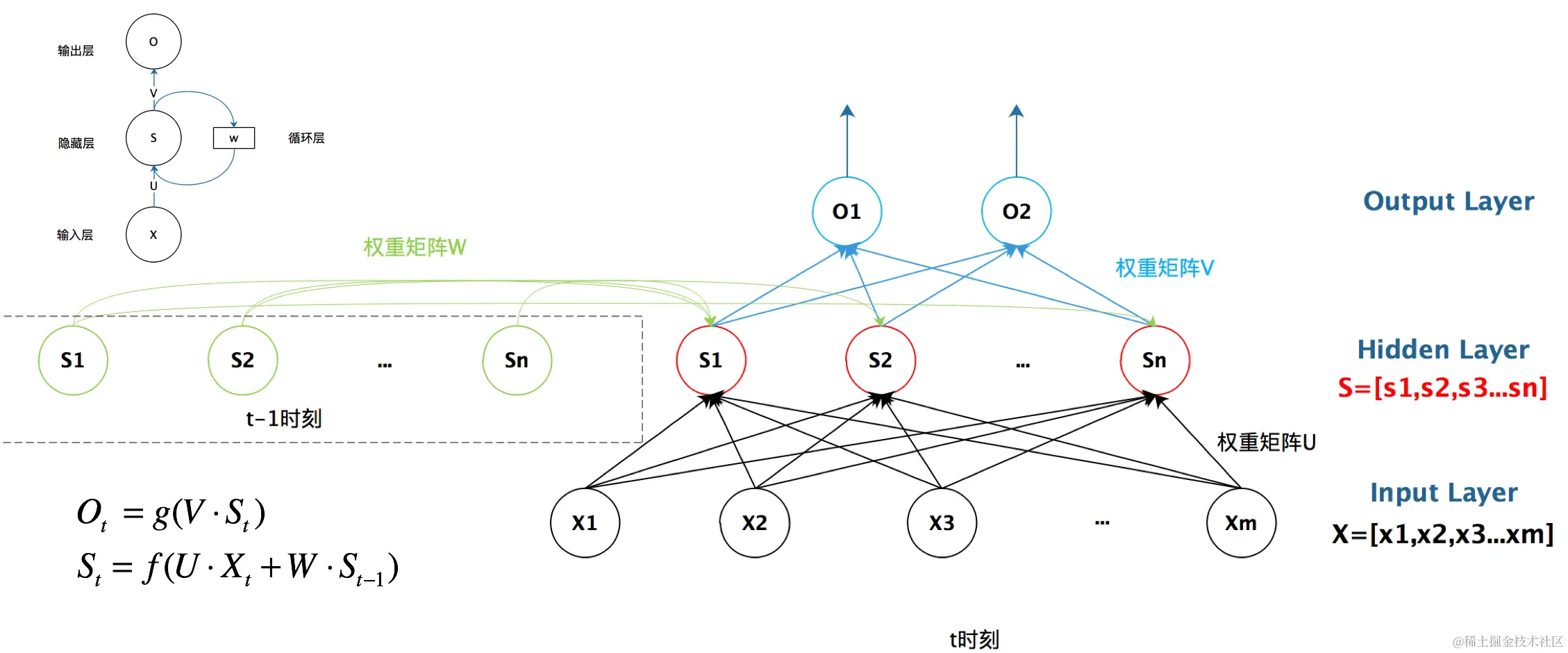 U是输入层到隐藏层的权重矩阵,O也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。循环神经网络的隐藏层的值S不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
U是输入层到隐藏层的权重矩阵,O也是一个向量,它表示输出层的值;V是隐藏层到输出层的权重矩阵。循环神经网络的隐藏层的值S不仅仅取决于当前这次的输入x,还取决于上一次隐藏层的值s。权重矩阵 W就是隐藏层上一次的值作为这一次的输入的权重。
2. LSTM简介
LSTM(Long Short-Term Memory)是一种循环神经网络(RNN)的变体,用于处理和预测时间序列数据。它在处理长期依赖关系(长距离依赖)时比传统的RNN更有效。
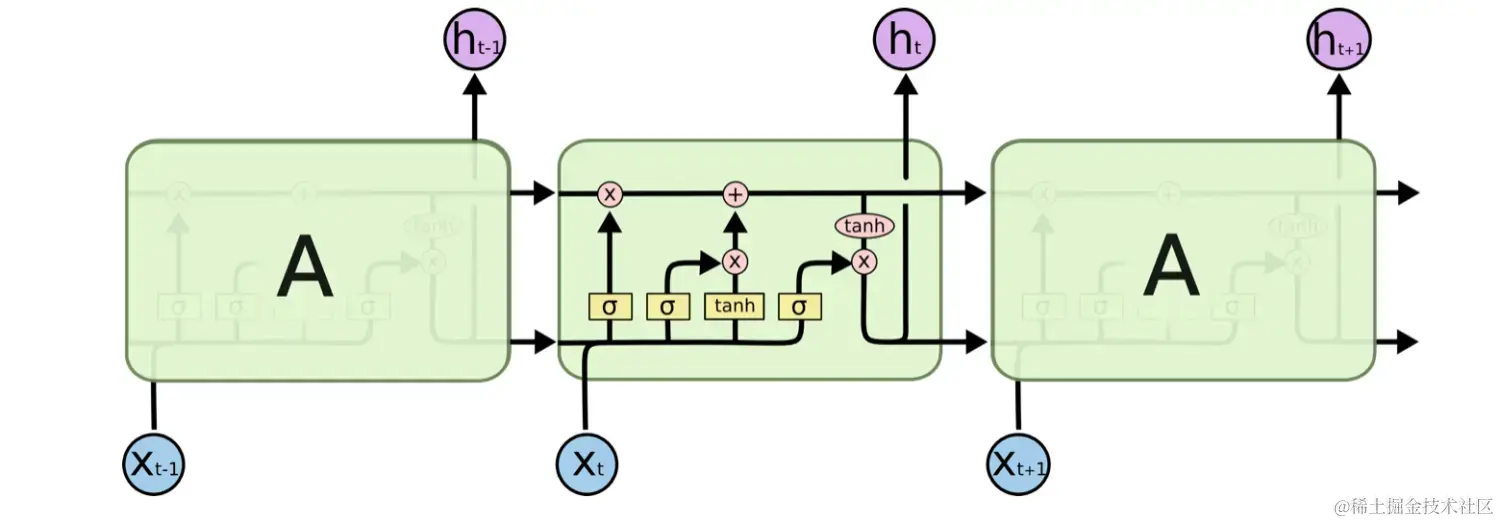
LSTM通过引入称为“细胞状态”(cell state)的概念来解决传统RNN中的梯度消失和梯度爆炸问题。细胞状态可以沿着时间步长保持不变,并且可以选择性地添加或删除信息。这样,LSTM可以更好地捕捉长期依赖关系,因为它可以选择性地遗忘或保留过去的信息。
it=σ(Wiixt+bii+Whiht−1+bhi)ft=σ(Wijxt+bif+Whfht−1+bhf)gt=tanh(Wigxt+big+Whght−1+bhg)gt=σ(Wioxt+bio+Whoht−1+bho)ct=ft⊙ct−1+it⊙gtht=ot⊙tanh(ct)
LSTM由三个门控单元组成:输入门(input gate)、遗忘门(forget gate)和输出门(output gate)。输入门控制是否更新细胞状态,遗忘门控制是否删除过去的信息,输出门控制将细胞状态转化为输出。
LSTM的工作原理是通过学习门控单元的权重来确定是否更新细胞状态和输出。这些权重是通过反向传播算法和梯度下降来训练的。在训练过程中,LSTM可以自动学习到时间序列中的模式和规律,从而进行预测和分类任务。
由于LSTM的能力和效果,在自然语言处理、语音识别、机器翻译等领域得到了广泛应用。它在处理长文本、长句子和长时间序列数据方面表现出色,成为深度学习中非常重要的一种模型。
3.RNN梯度消失和梯度爆炸原因
在普通RNN中,隐藏向量和输出的计算如下:
St=tanh(U⋅Xt+W⋅St−1)Ot=V⋅St
为了通过时间进行反向传播来训练RNN,我们需要计算E相对于W的梯度。总误差梯度等于每个时间步长的误差梯度之和。对于步骤t,我们可以使用多元链式规则来导出误差梯度,如下所示:
∂W∂Et=i=0∑t∂yt∂Et∂St∂yt∂Si∂St∂W∂Si
现在这里除了∂St/∂Si都可以很容易地计算出来,∂St/∂Si具体计算公式如下(diag将向量转化为对角矩阵):
∂Si∂St=∂St−1∂St∂St−2∂St−1...∂Si∂Si+1=k=1∏t−1∂Sk∂Sk+1
∂Sk∂Sk+1=diag(f′(Uxi+Whi−1))W
因此,如果我们想通过k个时间步长进行反向传播,则该梯度将为
∂S1∂Sk=∏kdiag(f′(Uxi+WSi−1))W
如本文所示,如果矩阵W的主特征值大于1,则梯度爆炸。如果小于1,则渐变消失。值得注意的是f′(x)的值将始终小于1,因此,如果W值太小,那么导数必然会变为0。小于1值的重复相乘将远远小于W的重复相乘。相反,使W过大,导数将变为无穷大,因为W的幂运算将超过小于1的值的重复乘法。在实践中,消失梯度更为常见,因此我们将主要关注这一点。如果梯度消失,就意味着早期的隐藏状态对后期的隐藏状态没有真正的影响,这意味着没有学到长期的依赖关系。
4.LSTM可防止梯度消失原因
导致梯度消失的最大罪魁祸首是我们需要计算的递归导数:∂St/∂Si。如果这个导数是“表现良好的”(也就是说,当我们通过层反向传播时,它不会变为0或无穷大),那么我们就可以学习长期依赖关系。
最初的LSTM解决方案,LSTM引入了一个单独的单元状态Ct。在最初的1997 LSTM中,Ct的值取决于单元状态的先前值和由输入门值加权的更新项:
Ct=Ct−1+iC~t
这种结构效果不佳,因为细胞状态往往无法控制地生长。为了防止这种无限增长,添加了一个遗忘门来缩放之前的细胞状态,从而产生了更现代的公式:
Ct=fCt−1+iCt~
∂Ct/∂Ct-1展开式:
∂Ct−1∂Ct=∂ft∂Ct∂ht−1∂ft∂Ct−1∂ht−1+∂it∂Ct∂ht−1∂it∂Ct−1∂ht−1+∂C~t∂Ct∂ht−1∂C~t∂Ct−1∂ht−1+∂Ct−1∂Ct
明确写出:
∂Ct−1∂Ct=Ct−1σ′(⋅)Wf∗ot−1tanh′(Ct−1)+C~tσ′(⋅)Wi∗ot−1tanh′(Ct−1)+ittanh′(⋅)WC∗ot−1tanh′(Ct−1)+ft
现在,如果我们想反向传播k个时间步长,我们只需乘以k倍以上的项。请注意这个递归梯度与普通RNN的递归梯度之间的巨大差异。在普通RNN中,项∂St/∂Si最终将取一个总是高于1或总是在[0,1]范围内的值,这本质上是导致消失/爆炸梯度问题的原因。
在任何时间步长,这里的项∂Ct/∂Ct−1可以取大于1的值,也可以取[0,1]范围内的值。因此,如果我们扩展到无限数量的时间步长,就不能保证我们最终会收敛到0或无穷大(与普通RNN不同)。如果我们开始收敛到零,我们总是可以将ft(和其他门值)的值设置得更高,以使∂Ct/∂Ct−1的值更接近1,从而防止梯度消失(或者至少防止它们消失得太快)。需要注意的一件重要事情是,值ft、ot、C~t( 以当前输入和隐藏状态为条件)。因此,通过这种方式,网络学会了通过相应地设置门值来决定何时让梯度消失,何时保持梯度!
这一切看起来可能很神奇,但实际上只是两件主要事情的结果:
- 细胞状态的加法更新函数给出了一个更“表现良好”的导数。
- 门控函数允许网络决定梯度消失的程度,并且可以在每个时间步长取用不同的值。它们所取的值是当前输入和隐藏状态的学习函数。
5.LSTM参数
对于输入序列中的每个元素,每个层计算以下函数:
it=σ(Wiixt+bii+Whiht−1+bhi)ft=σ(Wijxt+bif+Whfht−1+bhf)gt=tanh(Wigxt+big+Whght−1+bhg)gt=σ(Wioxt+bio+Whoht−1+bho)ct=ft⊙ct−1+it⊙gtht=ot⊙tanh(ct)
ht、ct、xt分别是时间t的隐藏状态、单元格状态和输入,ht−1是在时间t-1的层的隐藏状态或在时间0的初始隐藏状态。
it、ft、gt、ot分别为输入门、遗忘门、神经单元、输出门。σ是sigmoid函数,⊙是Hadamard乘积。
参数:
- input_size-输入x中预期的特征数
- hidden_size-隐藏状态h的特征数量
- num_size-重复出现的层数。例如,设置num_layers=2意味着将两个LSTM堆叠在一起以形成堆叠的LSTM,第二个LSTM接收第一个LSTM的输出并计算最终结果。默认值:1
- bias-如果为False,则层不使用偏移权重bih和bhh。默认值:True
- batch_first-如果为True,输入张量:(batch,seq,feature),否则为(seq,batch,feature)。默认值:False
- dropout-如果非零,则在除最后一层之外的每个LSTM层的输出上引入丢弃层,丢弃概率等于丢弃。
- bidirectional-如果为True,则变为双向LSTM。默认值:False
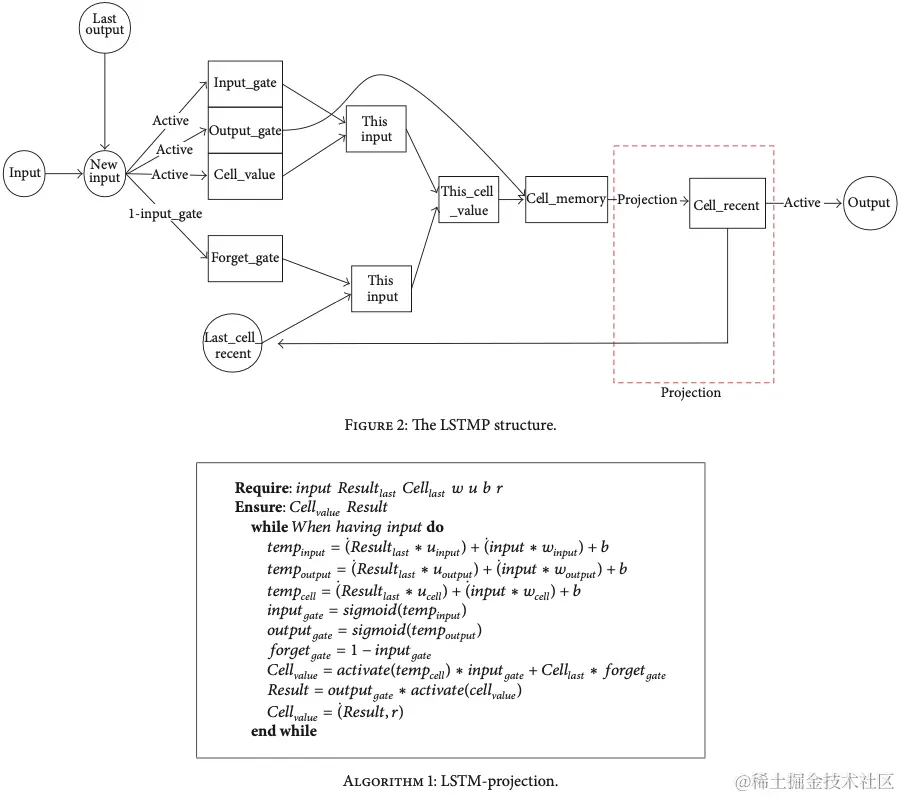
- proj_size-LSTM网络的变体,即LSTMP,减少LSTM的参数和计算量,进行h_t进行压缩,性能损失不大使用。默认值:0
输入:
- input-当batch_first=False时:(L,N,Hin),batch_first=Ture时:(N,L,Hin)。
- h_0-(D∗numlayers,N,Hout)
- c_0-(D∗numlayers,N,Hcell)
NLDHinHdetHdetHdet=batch size=sequence length=2 if biirectional=True otherwise1=input-size=hide=pair-size=pair-size if proj-size>0otherwise hidden-size
输出:
- output-当batch_first=False时:(L,N,D∗Hout),batch_first=Ture时:(N,L,D∗Hout)。
- h_n-(D∗numlayers,N,Hout)
- c_n-(D∗numlayers,N,Hcell)
变量:

图解:
 6.LSTM模型代码(Pytorch)
6.LSTM模型代码(Pytorch)

参考资料:
[1.](一文搞懂RNN(循环神经网络)基础篇 - 知乎 (zhihu.com))
[2.](Why LSTMs Stop Your Gradients From Vanishing: A View from the Backwards Pass (weberna.github.io))
[3.](LSTM — PyTorch 2.0 documentation)
[4.]((28条消息) PyTorch笔记 - LSTM(Long Short Term Memory) 和 LSTMP(Projection) 网络结构_pytorch lstm many2many_SpikeKing的博客-CSDN博客)


