【单智能体应用、分配算法、基于Q-learning】基于强化学习的电动汽车充电站收益最大化算法
Reinforcement Learning Based Algorithm for the Maximization of EV Charging Station Revenue
- 基于Q-learning算法
- 单智能体的强化学习
- 大多参数是利用统计学,使用历史数据归纳得出的
具体实现
-
参数设置
-
设置为一个episode为一天,一个小时step一次
-
t1=1,2,..,T 其中T=24 车辆以任何时间到达电站,但最早需要在下一小时开始时充电
-
电站有k个充电车位,最多容纳M辆车(M=k+等待充电车辆)
-
用函数f(x)表示车辆到达不同充电状态的支付费用(期望时间内获取的电量越多(快充)则越贵),x为车辆充电状态SOC;x1=SOCx1为初始态(在实验中根据历史信息手动配置);x2为需求状态(由用户提供);则价格=f(x2)−f(x1),电站还会获取车辆预计离开时间(TTL)
-
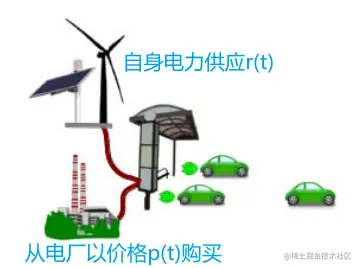
电站在某个t时刻获得自身电力供应r(t);此外,电站还可以以p(t)价格购买额外的电量,价格是变化的;(在实验中r(t)和p(t)根据统计的历史数据直接给出确定值;)
-
环境
-
观察/状态向量为
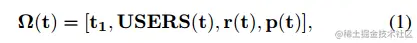
其中,t1表示一天中的小时,USERS(t)={{TTL(t),SOC(t),Types(t)}1,{TTL(t),SOC(t),Types(t)}2,...,{TTL(t),SOC(t),Types(t)}M}
TTL(t)为0~ttlmax之间的整数,ttlmax被设置为12;SOC被设置为0,10,20,...,90,100;假设每辆车的电池容量相同;在实验中,Types被设置为富裕用户rich,普通用户medium;
-
车辆抵达服从泊松分布,时间间隔(a, b)内到达的数量,用N(b)-N(a)表示
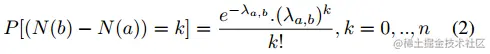
因此,到达的数量为 z(t)∼Po(λt,t+1),t∈1,2,...,23,λt,t+1为均值,带入k即可计算每个时段到达k个车辆的概率
-
动作空间:(充电量)动作向量为ui(t)=0,10,...,100−SOCi(t)
SOC向量更新为 SOC(t)=SOC(t)+u(t)
TTL减少1的变化:TTL(t+1)=TTL(t)−1,当TTL为0时将车辆移除
在每个时间步数组按TTL排序,如果TTL一致,则按类型排序
-
奖励函数Φ:

-
值函数:
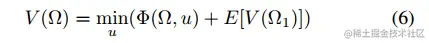
使用Q-learning的近似值函数: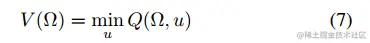
-
价格函数f(x):
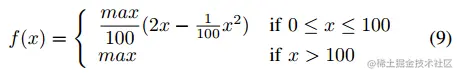
max指的是一辆最初空着的汽车充满电的价格,根据实验,maxrich=3.6 ,maxmedium=2.4
实验


