爬虫程序爬取rpm
import requests
from bs4 import BeautifulSoup
import os
url = 'https://vault.centos.org/5.5/os/x86_64/CentOS/'
dir_path = 'D://packages'
if not os.path.exists(dir_path):
os.makedirs(dir_path)
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
links = soup.find_all('a')
for link in links:
href = link.get('href')
if href.endswith('.rpm'):
print(f'Downloading {href} ...')
response = requests.get(f'{url}/{href}')
with open(os.path.join(dir_path, href), 'wb') as f:
f.write(response.content)
print('All done.')
爬虫程序爬取respondata 主要建立cache 使用
- 修改爬虫程序中16行的字符串将rpm 修改为xml与bz2 修改url为vault.centos.org/5.5/os/x86_…
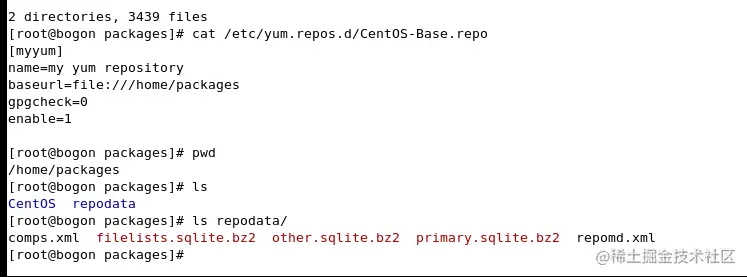
配置本地源
- sudo vi /etc/yum.repos.d/myyum.repo
- 写入
[myyum]
name=my yum repository
baseurl=file:///path/to/local/repo
enabled=1
gpgcheck=0
- sudo yum clean all
- yum list
- yum makecache
- 详细结构信息如下,