1.Map概述
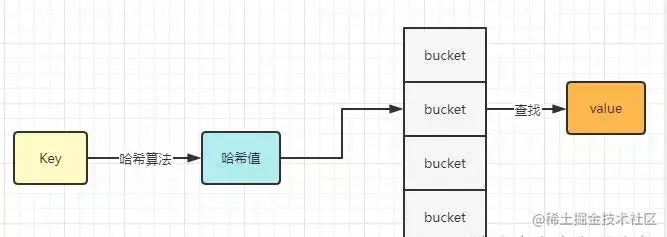
上面是Map实现的流程,Map的查询效率很高,时间复杂度为O(1),它的底层原理是哈希表,通过计算key的hash值,来找到它所在的bucket,然后再通过bucket来寻找它的value。、
2.哈希碰撞
因为bucket的数量是有限的,但是key——value对的数量却是会越来越多的,所以,在我们通过哈希值来寻找对应的bucket的时候,我们很有可能会遇到多个哈希值对应一个bucket的情况,这就叫做hash碰撞,我们可以用拉链法和开放地址法来解决这一类的问题。
2.1 拉链法
如果一个bucket中有很多个元素,这些元素会被以链表的形式组织起来,当我们找到了对应的bucket时,我们只需要对这个链表进行遍历就可以了。
好处:我们不用预先申请空间,可以不断地链接新的元素
缺点:因为使用了链表来组织数据,所以肯定会使用到额外的指针来连接,这增加了哈希表的大小。如果同一个桶中的连接元素太多了, 那么对于查找来说就不严格符合O(1), 当一条链表过长时, 我们需要改变这种情况, 让这个链表减少元素 , 更改哈希函数, 或者扩容.
2.2 开放寻址法
如果有“LLLL”和“MMMM”的hash(key)对应的bucket都是bucket1,产生了hash碰撞,那后面放入的元素“MMMM”就会自动放在bucket1的后面一个位置bucket2,如果bucket2被占用了,则放在bucket3,以此类推。
3.常用的操作
1.声明与创建
var m1 map[int]string
var m2 = make(map[int]int)
2.赋值
var m = make(map[int]int)
m[1]=2003
delete(m,1)
4.哈希函数
哈希函数能够将任意大小的数据映射出一个固定大小的值
(常见的哈希函数有MDS和SHA系列)


