

讲解Go写代码时性能如何优化
我们写代码的时候可能无意间就写出来了性能较差的代码,所以我们要学会性能调优,通过手段去把我们的程序进行优化,主要有Slice优化,Map优化,字符串处理优化......
1、Slice
大内存未释放
-
在已有切片上创建切片,不会创建新的底层数组
-
场景:
- 原切片较大,代码在原切片的基础上创建新的小切片
- 原底层数组在内存中有引用,得不到释放
-
可以用
copy代替re-slice
func GetLastBySlice(origin []int) []int {
return origin[len(origin)-2:]
}
func GetLastCopy(origin []int) []int {
result := make([]int, 2)
copy(result, origin[len(origin) - 2:])
return result
}
func testGetLast(t *testing.T, f func([]int) []int) {
result := make([]int, 0)
for i := 0; i < 100; i ++ {
origin := make([]int, 128 * 1024)
result = append(result, f(origin)...)
}
}
func TestLastBySlice(t *testing.T) {
testGetLast(t, GetLastBySlice)
}
func TestLastByCopy(t *testing.T) {
testGetLast(t, GetLastCopy)
}
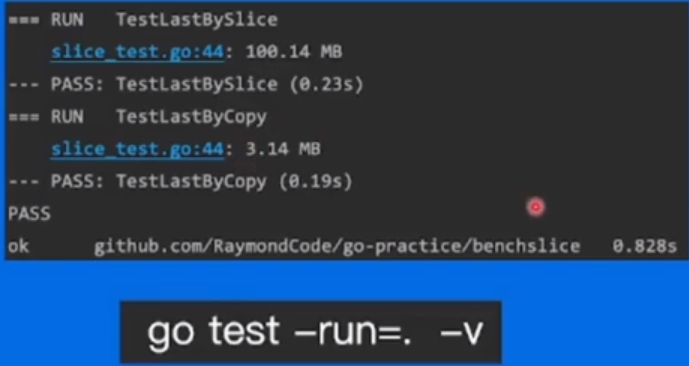
可见我们使用copy的时候内存和时间花销小很多
2、map优化
map使用时也要预先分配内存
3、字符串处理
我们常用的字符串处理
1.直接拼接
func plus(n int, str string) {
s := " "
for i := 0; i < n; i ++ {
s += str
}
}
2.使用strings.Builder()
func StrBuilder(n int, str string) {
var buf strings.Builder
for i := 0; i < n; i++ {
buf.WriteString(str)
}
}
3.使用ByteBuffer()
func ByteBuffer(n int, str string) {
buf := new(bytes.Buffer)
for i := 0; i < n; i++ {
buf.WriteString(str)
}
}
测试结果
# 测试Plus直接加
go test -bench=Plus
goos: windows
goarch: amd64
pkg: goTest/test
cpu: AMD Ryzen 5 4600U with Radeon Graphics
BenchmarkPlus-12 296730 109249 ns/op
PASS
ok goTest/test 32.560s
#每次耗时109249 ns/op
# 测试StrBuilder
go test -bench=StrBuilder
goos: windows
goarch: amd64
pkg: goTest/test
cpu: AMD Ryzen 5 4600U with Radeon Graphics
BenchmarkStrBuilder-12 231668 83853 ns/op
PASS
ok goTest/test 20.143s
# 每次耗时83853 ns/op
# 测试ByteBuffer
go test -bench=ByteBuffer
goos: windows
goarch: amd64
pkg: goTest/test
cpu: AMD Ryzen 5 4600U with Radeon Graphics
BenchmarkByteBuffer-12 257964 95089 ns/op
PASS
ok goTest/test 24.682s
# 每次耗时95089 ns/op
最快的是strings.Builder()
所以我们字符串拼接的时候用strings.Builder()是比较快的
原因分析
因为字符串在Go中是不可变类型,
- 占用内存大小固定,每次使用
+都会重新分配内存 - 另外两种方法底层都是
[]byte数组 - 内存扩容策略,不需要重新分配内存
4、atomic包
这个包用来去维持一个原子操作
type atomicCounter struct {
i int32
}
// atomic包
func AtomicAddOne(c *atomicCounter) {
atomic.AddInt32(&c.i, 1)
}
// 使用mutex进行操作
type mutexCounter struct {
i int
mu sync.Mutex
}
func MutexAddOne(c *mutexCounter) {
c.mu.Lock()
defer c.mu.Unlock()
c.i++
}
BenchmarkAtomicAddOne-12 269700860 4.463 ns/op 0 B/op 0 allocs/op
BenchmarkMutexAddOne-12 76684665 14.65 ns/op 0 B/op 0 allocs/op
从此处可见使用atomic包效率较高
原因
- 锁的操作使用过操作系统实现的,属于系统调用
atomic包通过硬件实现,效率比锁高- 加锁应该保护一段逻辑,不仅仅保护一段变量
- 非数值操作,可以使用
atomic.Value,承载一个interface{}
