访问【WRITE-BUG数字空间】_[内附完整源码和文档]
在机器学习领域,分类的目标是指将具有相似特征的对象聚集。而一个线性分类器则透过特征的线性组合来做出分类决定,以达到此种目的。对象的特征通常被描述为特征值,而在向量中则描述为特征向量。
1. 理论知识
1.1 从线性回归到线性多分类
回归是基于给定的特征,对感兴趣的变量进行值的预测的过程。在数学上,回归的目的是建立从输入数值到监督数值的函数: y^=f(x1,...,xm) 线性回归限制函数为线性形式,即为: f(x1,...xm)=w0+w1x1+...+wmxm=xw 其中, x=[1,x1,x2,...,xm] w=[w0,w1,w2,...,wm]T 也就是找一组参数wkk=1m,使得在训练集上,函数与预测值尽可能接近。
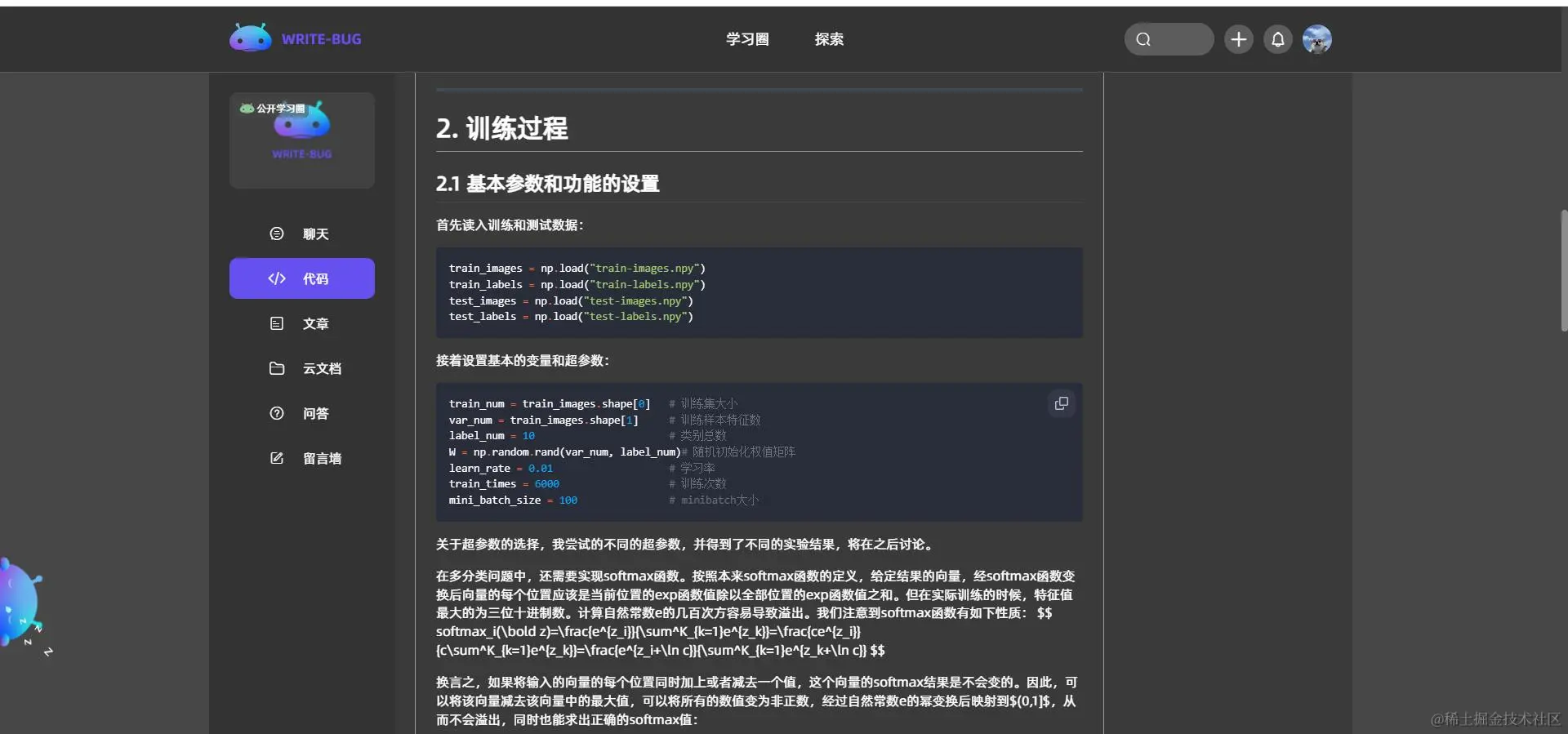
对于本次的分类问题来说,线性回归的输出值与分类任务中的目标值不兼容。线性回归的结果范围为全体实数,而对于本次实验的多分类问题,变量结果即属于的类别,换言之,我们期望的结果标签的种类数量和训练样本的总类别数量一致。因此考虑使用softmax函数来将回归结果映射到种类上,从而表示分类结果。对于K分类问题,有: softmaxi(z)=∑k=1Kezkezi fi(x)=softmaxi(xW)=∑k=1Kexwkexwi 其中,W为: W≜[w1,w2...,wK] 易见,所有类的softmax函数值之和为1。每一类的函数值就为它的概率。
1.2 损失函数表示与优化
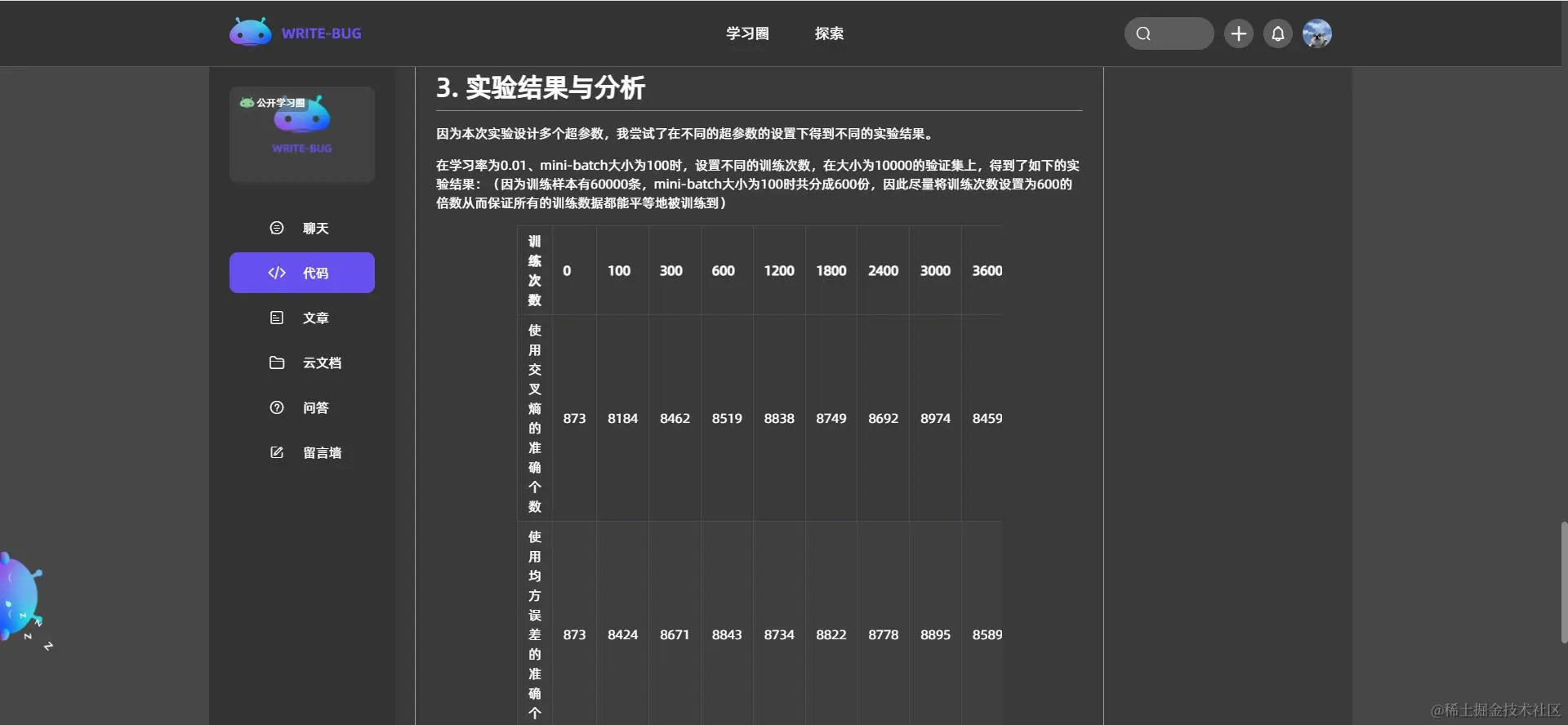
经过上面的讨论与操作,对于多分类问题,预测结果是在每一类上的概率,即维度数等于类数的向量。与之对应的实际结果可以用独热向量表示,即是本类的那一维度为1,其他维度为0的向量。为了使得预测结果与实际结果尽量接近,我们考虑用损失函数用于衡量预测结果和实际结果的差距。在数学上,该分类问题等价于找到合适的向量w,使得损失函数最小化。依据本次实验的要求,损失函数需要分别考虑交叉熵损失和均方误差损失,即损失函数分别为: L1(w1,w2,...,wK)=−N1∑l=1N∑k=1Kyk(l)logsoftmaxk(x(l)W) L2(w1,w2,...,wK)=N1∑l=1N∑k=1K(softmaxk(x(l)W)−yk(l))2 其中,yk(l)是第k个y(l)的元素。
考虑使用梯度下降法使得损失函数最小化。两个损失函数的梯度分别为: \partW\partL(W)=N1∑l=1Nx(l)T(softmax(x(l)W)−y(l)) \partW\partL(W)=N2∑l=1Nx(l)T(softmax(x(l)W)−y(l))∗(diag(softmax(x(l)W)−softmax(x(l)W)∗softmax(x(l)W)T)
梯度下降法的参数更新方式为: W(t+1)=W(t)−r\partW\partL(W)∣∣W=W(t)
其中r为学习率。对于凹函数,通过适当的学习率,对模型参数进行迭代更新,最终可以收敛到最小值点。