媒体数据,用户数据的碰撞总结
一,背景
困境
- 媒体那有消耗数据,用户数据不能长线提供(如:只提供7天)
- 公司本身有最准确的用户数据,没有相关投放的消耗数据
- 媒体那很难能满足公司业务的一些定制化需求
实现方式
- 用空间换时间,暂时不支持实时查询,可以接受一定的时间误差
- 多渠道接入(头条,广点通,百度等等)
- 满足一些定制化需求
二,实践总结
1,名词解析

2,消耗碰撞
如何将媒体数据和用户数据进行碰撞,并且能支持多维度的查询得满足以下:
1. 用户数据在进行媒体归因时,要将对应媒体数据如:广告组,广告计划,广告创意,素材ID等采集入库,必须得获取最小粒度的层级单位数据,如创意等
2. 媒体也是拉取对应的层级数据,如广告组,广告计划,广告创意等,最小粒度必须得拉取,并在表中维护好对应的层级关系,如在创意中能查到对应的广告计划,广告组,对应的账户等
3. 媒体只需拉取最小粒度的消耗即可(这是最佳实践),如果每个层级都拉取会出现以下问题:
- 浪费大量资源开发和维护接口
- 因为拉取时机问题导致在某一个时刻,几个层级的消耗对不上
- 如果出现消耗对不上,排查难度是n倍(n=层级)
4,所有的消耗只拉取最小维度的,其他层级查询通过关联关系直接查询最小粒度,有问题排查一次就够了
5,因为是用定时任务定时拉取,这里就会出现间隔上的缺失(不可避免),应对的方式是每天8点重新拉取一次昨天的数据(投手上班前能看到比较准确的数据),10点后再拉取一次昨天的数据(媒体一般都是第二天的10点后也会校准数据一次)
3,素材归因
1, 在监测链接中媒体要么提供素材的相关的直接数据如素材ID,要么就提供间接素材如创意ID等,拉取媒体对应的数据进行匹配
2,匹配过程中会出现上游数据丢失某些关键指标导致匹配不上(不可避免),这里匹配的逻辑就是以媒体的数据为准进行匹配,只有这样才能保证素材消耗不会丢失,未匹配的以未知素材显示,如:
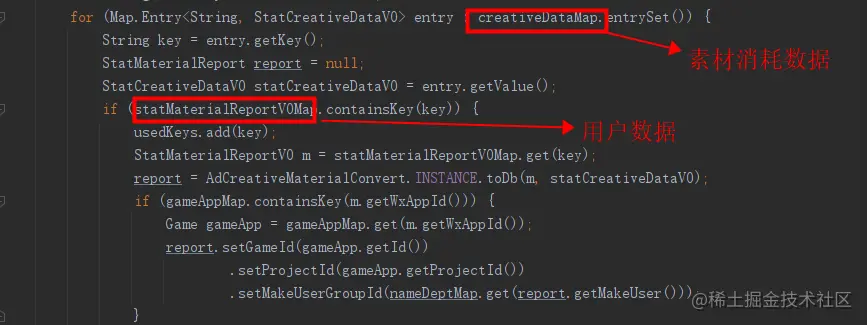
3,素材信息的匹配,比如素材名称,创作人之类的,这与获取数据的方式有关,天枢这里素材信息是从创量获取,如果设计师是直接从媒体上传的,这里就会获取不到,解决的方案就是,素材基建,构建自己平台的素材库,所有上传的数据保存在平台,这样就可以从根源上杜绝匹配不到的素材,当然历史数据搞不了.
4,数据指标的计算
分而治之,业务内敛,不同的业务,分别存放,满足各种维度的参数
根据不同业务,灵活组合数据,满足多种场景
1,解决roi,xx率之类的问题的办法就是在内存中计算,表中只存计算前数据,因为各项指标只会更多,如果都存库中,只会使表爆炸增长,而且也解决不了合计中的计算
2,解决查询中对某一个指标的排序查询,如果是计算数值其实能用sql解决,但是碰到roi,xx率的指标,解决不了,解决方案就是,将相关数据加载到内存中,然后根据和前端约定好的排序参数进行对应排序
3,解决查询中的多维度查询,多维度查询会存在一个问题,怎样根据不同维度显示不同的字段内容,目前有两个方案
- 后端是全字段指标返回,但也会返回一个相关的字段展示列表,前端根据这个列表进行命中展示
- 后端在内存中将数据像mysql一样进行处理只返回要展示的字段内容
5,硬件升级
随着数据不断的增多,相应的硬件也得升级,之前天枢碰到过定时任务服务器经常挂机和Redis缓存刷新不及时,经过排查都是硬件资源到达瓶颈所致,后期升级,持续观察了一段时间,暂时没出现了
6,媒体拉取方式升级
以前拉取存在的问题
- 全量拉取,时间长
- 经常会触发媒体设定的阈值,导致很多账号拉取不到数据
- 占用服务器资源
- 很难缩短更新媒体数据的周期
V2版本
- 根据有消耗账号拉取,拉取量不到20%
- 减少服务器资源的占用
- 能缩短更新媒体数据的周期,目前15分钟,媒体建议是10-15分钟拉取一次
7,业务沉淀输出
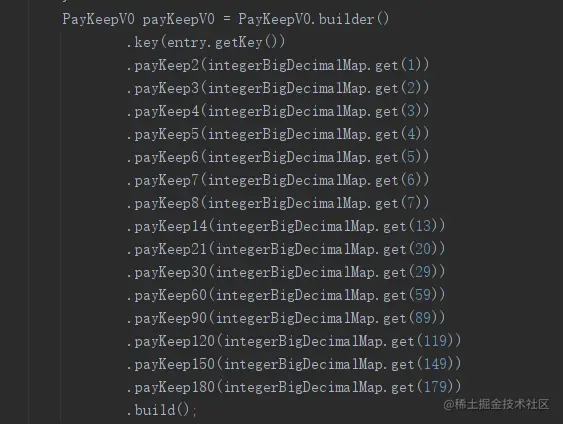
- 各种指标成熟的算法,如:
- 有套路的问题排查思路,产品提供有问题数据,如1月份账号维度的消耗,导入数据库与数据数据进行账号维度的比对,定位到对应账号,然后进行专项排查
- 较成熟的技术方案,如平齐素材数据与广告数据一致的问题(广告数据直接查询素材或者定时拉取素材报表)
- 技术输出

- 内存中像mysql一样的操作,只返回指定的字段,并能进行数据的相加
7,路漫漫其修远兮,吾将上下而求索


