SimCLR通过隐藏空间的对比损失最大化相同数据在不同增广下的一致性来学习表达。SimCLR框架有四个主要的组件,分别是:数据增广,encode网络,projection head网络和对比学习函数。
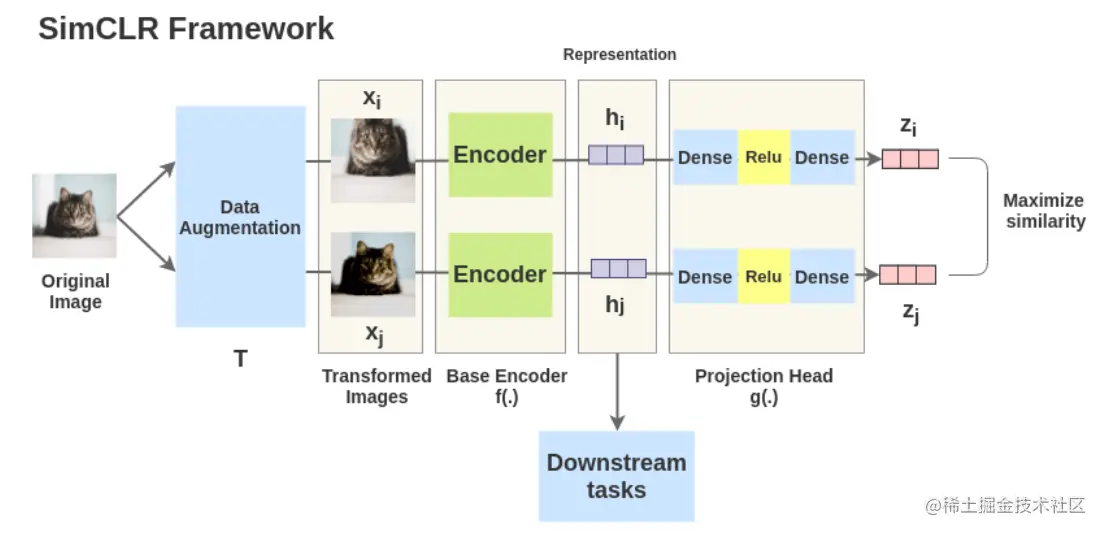
对于数据x,从同一个数据增广族中抽取两个独立的数据增广算子(t∼T和t′∼T),以获得两个相关的视图x^i和x^j,x^i和x^j是一对正样本,然后一个神经网络编码器f(⋅)从增广的数据中提取特征hi=f(x^i),hj=f(x^j),。再然后一个小的神经网络project head g(⋅)将特征映射到对比损失的空间。project head采用带有一个隐含层的MLP获取zi=g(hi)=W(2)σ(W(1)hi)。
对于包含一对正样本x^i和x^j的集合{x^k},对比预测任务目的是对于给定的x^i在{x^}k=i中识别出x^j。随机挑选N个样本组成一个minibatch,这个minibatch中则有2N个数据样本,将其他2(N−1)个扩增的样本作为这个minibatch中的负样本,设sim(u,v)=uTv/∥u∥∥v∥表示l2正则化后你的u和v的点积,那么对一对正样本(i,j),损失函数如下定义:
li,j=−log∑k=12N1[k=i]exp(sim(zi,zk)/τ)exp(sim(zi,zj)/τ)
最后的损失函数计算一个minibatch中的所有的正样本对,包括(i,j)和(j,i)。下面是SimCLR的伪代码。从伪代码中可以看出,编码器f(⋅)和project head g(⋅) 在训练时都会被更新参数,但是只有编码器f(⋅)用于下游任务。

simCLR不采用memory bank的形式进行训练,而是加大batchsize,bacth size为8192,对于每一个正样本,将会有16382张负样本实例。增大batch size其实相当于每个minibatch时动态生成一个memory bank。论文中发现使用标准的SGD/Momentum,大batch size训练时是不稳定的,论文中采用LARS优化器。
参考
- The Illustrated SimCLR Framework
- SimCLR


