一、概述
对于下图所示的数据进行聚类,可以采用GMM或者K-Means的方法:

然而对于下图所示的数据,单纯的GMM和K-Means就无效了,可以通过核方法对数据进行转换,然后再进行聚类:

如果直接对上图所示的数据进行聚类的话可以考虑采用谱聚类(spectral clustering)的方法。
总结来说,聚类算法可以分为两种思路:
①Compactness,这类有 K-means,GMM 等,但是这类算法只能处理凸集,为了处理非凸的样本集,必须引⼊核技巧。
②Connectivity,这类以谱聚类为代表。
二、基础知识
1.无向权重图
谱聚类的方法基于带权重的无向图,图的每个节点是一个样本点,图的边有权重,权重代表两个样本点的相似度。
假设总共N个样本点,这些样本点构成的图可以用G=(V,E)表示,其中V={v1,v2,⋯,vN},图中的每个点vi也就代表了一个样本xi,E是边,用邻接矩阵(也是相似度矩阵)WN×N来表示,W=[wij],1≤i,j≤N,由于是无向图,因此wij=wji。
另外还有度的概念,这里可以类比有向图中的出度和入度的概念,不过图中的点vi的度di并不是和该点相连的点的数量,而是和其相连的边的权重之和,也就是邻接矩阵的每一行的值加起来,即:
di=j=1∑Nwij
而图的度矩阵(对角矩阵)DN×N可以表示如下:
D=⎣⎡d1d2...dN⎦⎤
另外我们定义,对于点集V的一个子集A⊂V,我们定义:
∣A∣:=子集A中点的个数vol(A):=i∈A∑di
2.邻接矩阵
构建邻接矩阵W一共有三种方法,分别是ϵ-近邻法、k近邻法和全连接法。
首先需要设置一个阈值ϵ,比较任意两点xi与xj之间的距离sij=∣∣xi−xj∣∣22与ϵ的大小,定义邻接矩阵如下:
wij={0,sij>ϵϵ,sij≤ϵ
这种方法表示如果两个样本点之间的欧氏距离的平方小于阈值ϵ,则它们之间是有边的。
使用这种方法,两点相似度只有ϵ和0两个值,这种度量很不精确,因此在实际应用中很少使用ϵ-近邻法。
使用KNN算法遍历所有样本点,取每个样本点最近的k个点作为近邻。这种方法会造成构造的邻接矩阵不对称,而谱聚类算法需要一个对称的邻接矩阵。因此有以下两种方法来构造一个对称的邻接矩阵:
①只要一个点在另一个点的k近邻内,则wij>0,否则为0,相似度wij可以使用径向基函数来度量:
wij=wji={exp{−2σ2∣∣xi−xj∣∣22},xi∈KNN(xj)orxj∈KNN(xi)0,xi∈/KNN(xj)andxj∈/KNN(xi)
②只有两个点互为k近邻,才会有wij>0,否则为0:
wij=wji={exp{−2σ2∣∣xi−xj∣∣22},xi∈KNN(xj)andxj∈KNN(xi)0,xi∈/KNN(xj)orxj∈/KNN(xi)
上述方法是不用先建立图而直接获得邻接矩阵,在编程实现时能够更加简便,构建的邻接矩阵也就表明了哪些样本点之间有边连接。也可以采用先建立图然后再在图上有边的数据点上保留权重获得邻接矩阵的方法。
这种方法会使所有的wij都大于0,可以选择不用的核函数来度量相似度,比如多项式核函数、径向基核函数和sigmoid核函数。最常用的是径向基核函数:
wij=exp{−2σ2∣∣xi−xj∣∣22}
在实际应用时选择全连接法建立邻接矩阵是最普遍的,在选择相似度度量时径向基核函数是最普遍的。
3.拉普拉斯矩阵
图的拉普拉斯矩阵(Graph Laplacian)LN×N是一个对称矩阵,用度矩阵减去邻接矩阵得到的矩阵就被定义为拉普拉斯矩阵,L=D−W。拉普拉斯矩阵有一些性质如下:
- ①对称性。
- ②由于其对称性,则它的所有特征值都是实数。
- ③对于任意向量f,有:
fTLf=21i=1∑Nj=1∑Nwij(fi−fj)2
这一性质利用拉普拉斯矩阵的性质很容易可以得到:
fTLf=fTDf−fTWf=i=1∑Ndifi2−i=1∑Nj=1∑Nwijfifj=21(i=1∑Ndifi2−2i=1∑Nj=1∑Nwijfifj+j=1∑Ndjfj2)=21(i=1∑Nj=1∑Nwijfi2−2i=1∑Nj=1∑Nwijfifj+i=1∑Nj=1∑Nwijfj2)=21i=1∑Nj=1∑Nwij(fi−fj)2
- ④拉普拉斯矩阵是半正定的,则其所有特征值非负,这个性质由性质③很容易得出。并且其最小的特征值为0,这是因为L的每一行和为0,对于全1向量1N=(11⋯1)T,有L⋅1N=0=0⋅1N。
4.无向图切图
对于无向图G的切图,我们的目标是将G=(V,E)切成相互没有连接的k个子图,每个子图节点的集合为A1,A2,⋯,Ak,它们满足Ai∩Aj=ϕ,且A1∪A2∪⋯∪Ak=V。
对于任意两个子图点的集合A,B⊂V,定义A和B之间的切图权重为:
W(A,B)=i∈A,j∈B∑wij
对于k个子图的集合,定义切图cut为:
cut(A1,A2,⋯,Ak)=i=1∑kW(Ai,Ai)
上式中Ai是Ai的补集,意为除Ai子集以外的其他子集的并集。
每个子图就相当于聚类的一个类,找到子图内点的权重之和最高,子图间的点的权重之和最低的切图就相当于找到了最佳的聚类。实现这一点的一个很自然的想法是最小化cut。然而这种方法存在问题,也就是最小化的cut对应的切图不一定就是符合要求的最优的切图,如下图:
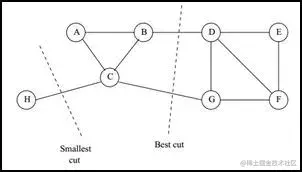
在上面的例子中,我们选择在最小的权重上进行切图,比如在C和H之间进行切图,这样可以使得cut最小,但并不是最优的切图。
接下介绍谱聚类使用的切图方法。
三、模型定义
我们首先来做一些基本定义:
样本X=(x1x2⋯xN)⊤=⎝⎛x1⊤x1⊤⋮xN⊤⎠⎞N×p图G={V,E}V代表顶点集合,E代表边集合顶点集V={1,2,...,N}<=>X每个顶点代表一个样本边集合E:W=[wij],1≤i,j≤N其中:W:simiilaritymatrix(affinitymatrix)wij={K(xi,xj)=exp{−2σ2∣∣xi−xj∣∣22},(i,j)∈E 0,(i,j)∈E
谱聚类是基于Graph-based(带权重的无向图),因此我们将对该图所涉及到的一些变量进行具体定义。
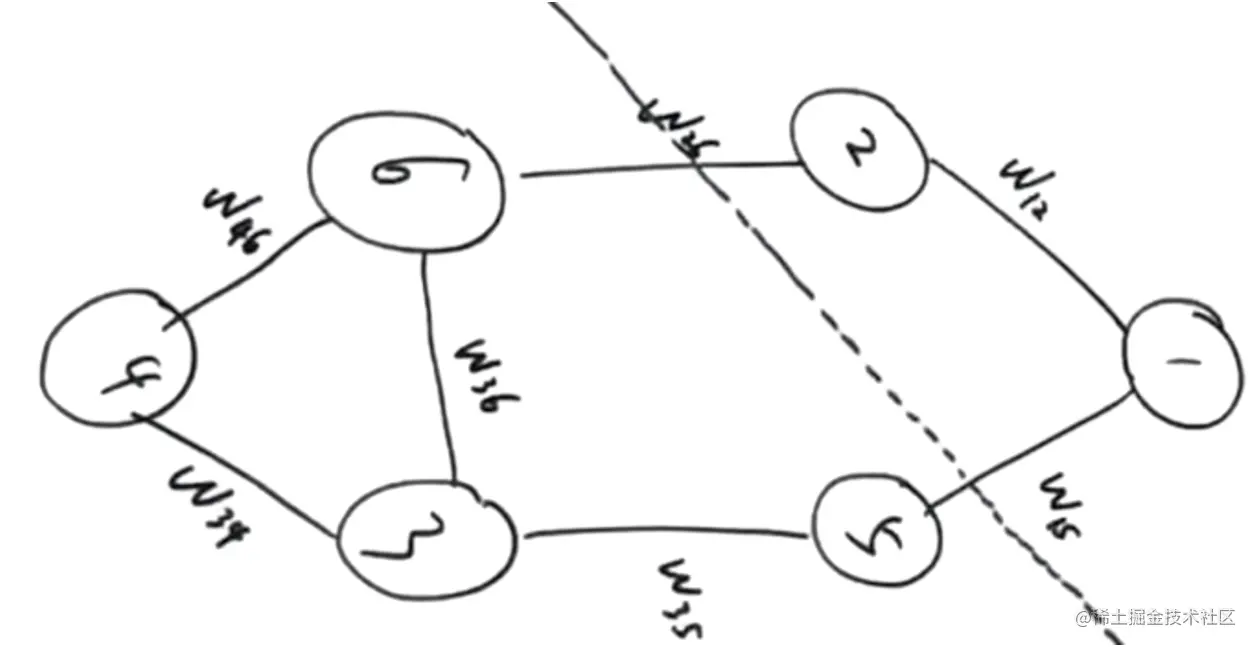
定义:A⊂V,B⊂V,A∩B=∅,在上图中,可以视作A即为点1,2;B为点3,4,5,6W(A,B)=i∈Aj∈B∑Wij
假如一共有K个类别,即cut(V)=cut(A1,A2,⋯⋅Ak)=∑k=1KW(Ak,Aˉk)=∑k=1KW(Ak,V)−W(Ak,Ak)
在这里我们的目标是取得最小的Cut(V),也就是让每一个类之间的关联度达到最低。
而cut(V)=degree(Ak)=∑i∈Akdi,di=∑j=1Nwij,di就是在它所在类别中与它相连的顶点的相似矩阵之和,就比如,i=1时,因为1、2为一组,那么wij最终的取值就只是w12,因为在相似矩阵的定义中别的地方的取值只能为0(不同组)
在这里有一个小问题,当同组的点个数越多,那么相似矩阵之和必然越多,即我们需要保证不会因为数量问题使得后续优化问题的结果取向局部最优,因此最好的方式是在每一组下面除以一个当前组数,求平均,即最终的目标转化为:minNcut(V)
Ncut=k=1∑K∑i∈AkdiW(Ak,Aˉk)
四、模型的矩阵形式
定义指示向量(indicator vector):{yi∈{0,1}k∑i=1kyij=1 1⩽i⩽N,1⩽j⩽k这样表示的意思就是one-hot向量,对于第i个样本而言,它属于第j个类别。
我们现在考虑将上述Ncut模型转换为矩阵形式,定义Y=(y1,y2,..,yN)N∗kT则Y^=YargminNcut (v)其实就相当于引入一个Y矩阵,其中yi是k维one-hot向量,因为每个样本i只属于一个类别,只能一个维度为1。
由于优化问题的结果,一定是一个实数,所以我们可以考虑将Ncut转化为矩阵,并对其求trace,其过程如下所示,将原式拆解成O、P两部分:
Ncut (v)=k=1∑K∑i∈AkdiW(Ak,Aˉk)=trO⋅P−1=tr⎝⎛W(A1,Aˉ1)W(A2,Aˉ2)⋱W(Ak,Akˉ)⎠⎞⎭⎬⎫Ok×k . ⎝⎛∑i∈A1di∑i∈A2di⋱∑i∈Akdi⎠⎞−1⎭⎬⎫Pk×k
- P的含义:A1,A2...都属于一个样本子集,求 和di意味着对于每一个子集内每一个点的度求和,假如A1={1,2,5},那么P1,1=d1+d2+d5
我们再来回顾一下,现在我们已知的是W,Y,要求的是O,P,并且选择从P开始入手。由于W是一个很正常的矩阵,我们现在考虑从Y入手看看有没有什么新发现。
对于Y=(y1,y2,..,yN)N∗kT而言,YTY=∑i=1Nyi⋅yiT,为k × k 维的矩阵,将其展开得到式子y1y1⊤+⋯yNyN⊤,且,根据定义,如果y1k=1,y2k=1就代表着样本x1,x2∈Ak,将此概念广泛化,即为:
Nk : 在N个样本中,属于类别 k 的样本个数
k=1∑kNk=N,Nk=∣Ak∣=i∈Ak∑⋅1
这个结论与P的对角线某一项如此的相似,由此,我们可以作进一步转化。
YTY=⎝⎛N1N2...Nk⎠⎞k×k=⎝⎛∑i∈A11∑i∈A21⋱∑i∈Ak1⎠⎞P=⎝⎛∑i∈A1di∑i∈A2di⋱∑i∈Akdi⎠⎞=Y⊤⋅D⋅Y其中:D=⎝⎛d1d2⋱dN⎠⎞=diag(W⋅1N×1)diag()即将W⋅1N×1的结果(N×1的列向量)转化为对角线上的值,构造N×N的对角矩阵
到这里我们就求得了P,接下来试着将O进行表达,首先对Ok,k进行解读
Ok,k=W(AK,AˉK)=∑i∈AkdiW(Ak,v)−∑i∈Ak,j∈AkwijW(Ak,Ak)
自然而然的,我们可以将O改写成如下形式,并且左项已在P时就求得,牢牢抓住已知条件只有W,Y,右项则需要进一步尝试
O=⎝⎛∑i∈A1di⋱∑i∈Akdi⎠⎞−⎝⎛w(A1,A1)⋱w(Ak,Ak)⎠⎞=Y⊤DY−△
由于右项与w相关,且YTY又能构造相同维度矩阵,不难得出应该尝试一下YTWY
Y⊤WY=⎝⎛∑i∈A1∑j∈A1wij⋮∑i∈AK∑j∈A1wij∑i∈A1∑j∈A2wij⋯⋯⋯∑i∈A1∑j∈AKwij⋮∑i∈AK∑j∈AKwij⎠⎞
与△有些许不同,故我们可以定义O’=Y⊤DY−YTWY
这无伤大雅,因为我们的目标是求Ncut(v),且P为对角矩阵,则trO’⋅P−1=trO⋅P−1
到了这里,我们就求得了我们的最终目标:
Y^=argminYtr(Y⊤(D−w)Y⋅(Y⊤DY)−1)其中:L=D−w就是著名的LaplacianMatrix
五、总结
谱聚类是一种在数据集中找出群集或者组的技术。与传统的聚类算法(如K-means)相比,谱聚类可以识别出复杂的聚类结构,并且不需要事先假设每个群集在几何形状上的均匀性。谱聚类的工作原理是将数据点转化为图形结构,然后通过对图形进行操作(例如切割图形以最小化连接不同组的边的权重)来识别出组。
下面是谱聚类的基本步骤:
- 构建相似性矩阵:对于输入的数据点,计算每对数据点之间的相似性,并形成一个相似性矩阵。
- 构建图:基于上一步的相似性矩阵,构建一个图,其中每个节点代表一个数据点,每个边代表两个数据点的相似度。
- 构建拉普拉斯矩阵:然后计算出所谓的拉普拉斯矩阵。拉普拉斯矩阵是图的一个关键属性,可以反映出图的结构信息。常见的拉普拉斯矩阵有无向图的拉普拉斯矩阵和归一化拉普拉斯矩阵等。
- 计算拉普拉斯矩阵的特征向量和特征值:然后求解拉普拉斯矩阵的特征向量和特征值。
- 基于特征向量进行聚类:选择前k个最小的特征值对应的特征向量,将它们按列合并成一个矩阵,然后将这个矩阵的每一行看作是原数据在新的空间下的表示,对这些数据点使用传统的聚类方法(如K-means)进行聚类。
谱聚类的优点是能够处理复杂的非线性数据,并且可以识别出复杂的聚类结构。但是,谱聚类的计算成本可能会比较高,尤其是对于大型数据集,因为需要计算和存储全量的相似度矩阵,并对其进行特征分解。


