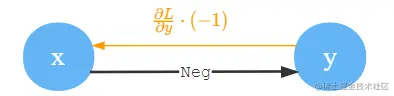本文介绍常见运算的计算图。
计算图直观地表示了计算过程。通过观察反向传播的梯度流动,可以帮助我们理解反向传播的推导过程。
我们会利用计算图来实现自动求导工具。首先我们看一下常见运算操作的计算图。
加法
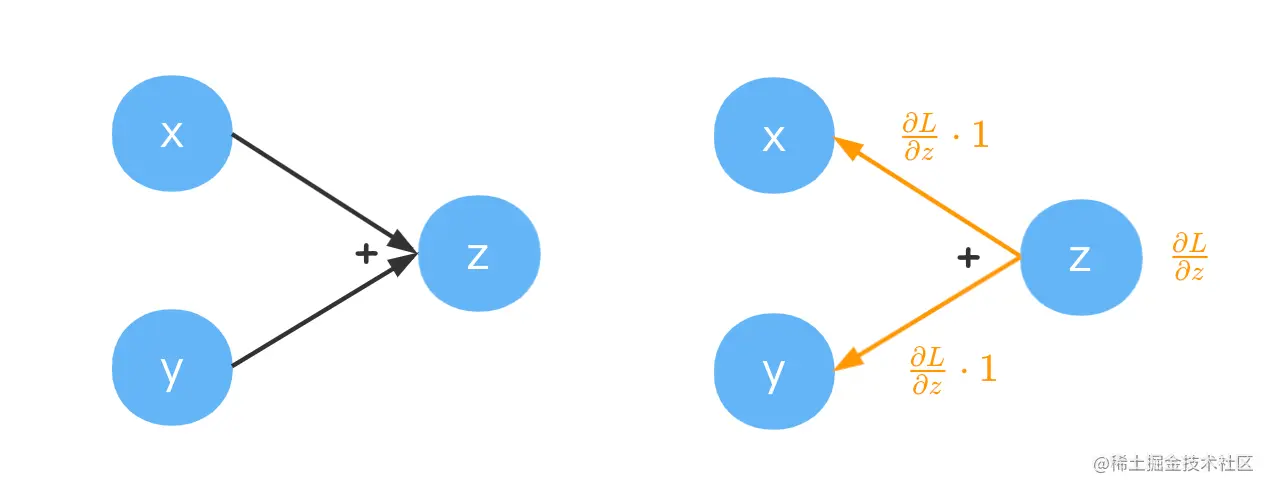
z=x+y求这个运算的梯度比较简单,易得∂x∂z=1,∂y∂z=1
∂z∂L为经过反向传播传递到z节点上的梯度。
减法
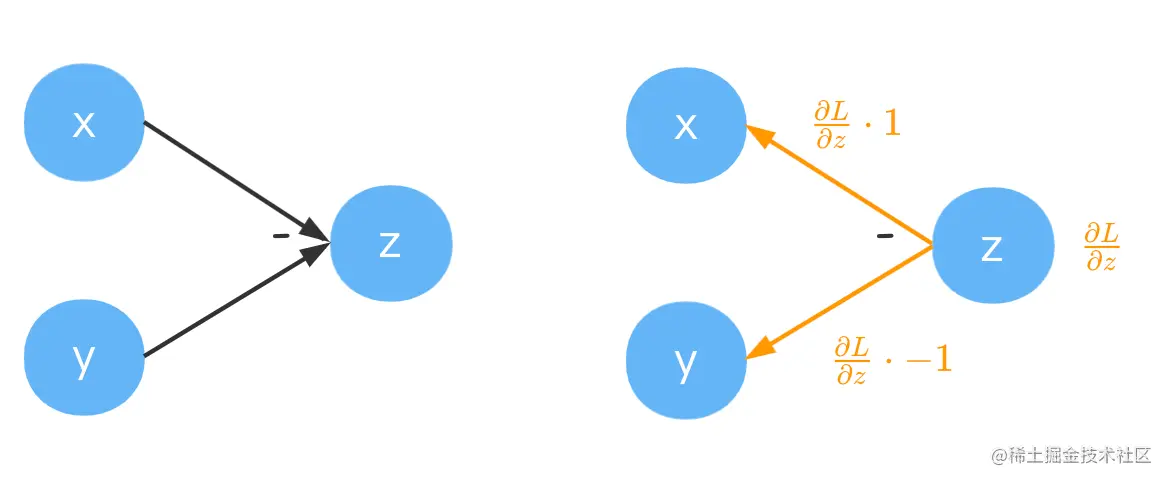
由z=x−y 可得∂x∂z=1,∂y∂z=−1
乘法
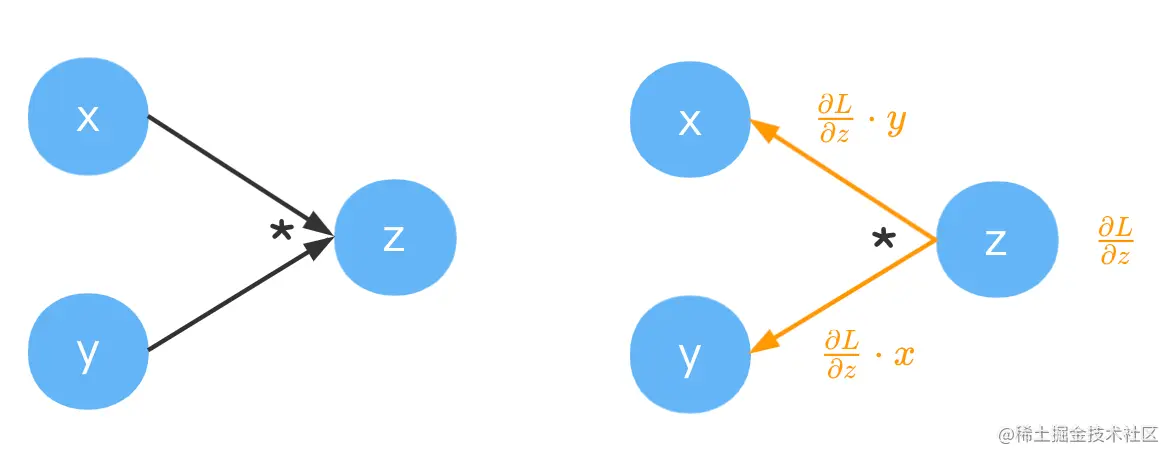
z=x×y 的梯度也比较简单,易得∂x∂z=y,∂y∂z=x。
此时,反向传播时会将上游传来的梯度乘以当前路径上计算出来的梯度。
除法
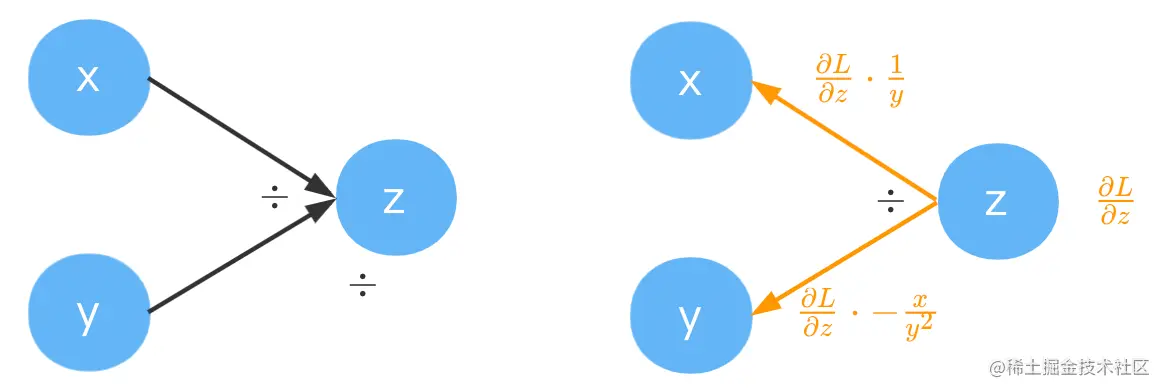
z=yx的梯度稍微有点复杂,∂x∂z=y1,∂y∂z=−y2x。
我们现在看到的都是单变量,其实也可以是多变量(向量、张量或矩阵)。在多变量时,只需要独立计算向量中各个元素,即,向量的各个元素独立于其他元素进行对应元素的计算。在下文的矩阵乘法时会详细介绍。
分支
严格来说,分支并不是我们常见运算的一种。但是有些情况下很有用,比如进行广播操作时。

分支是最简单的复制形式,它的反向传播是上游传来的梯度之和。
Repeat
上面的分支操作有两个副本(或者分支),也可以扩展为N个副本,此时称为复制(Repeat)。
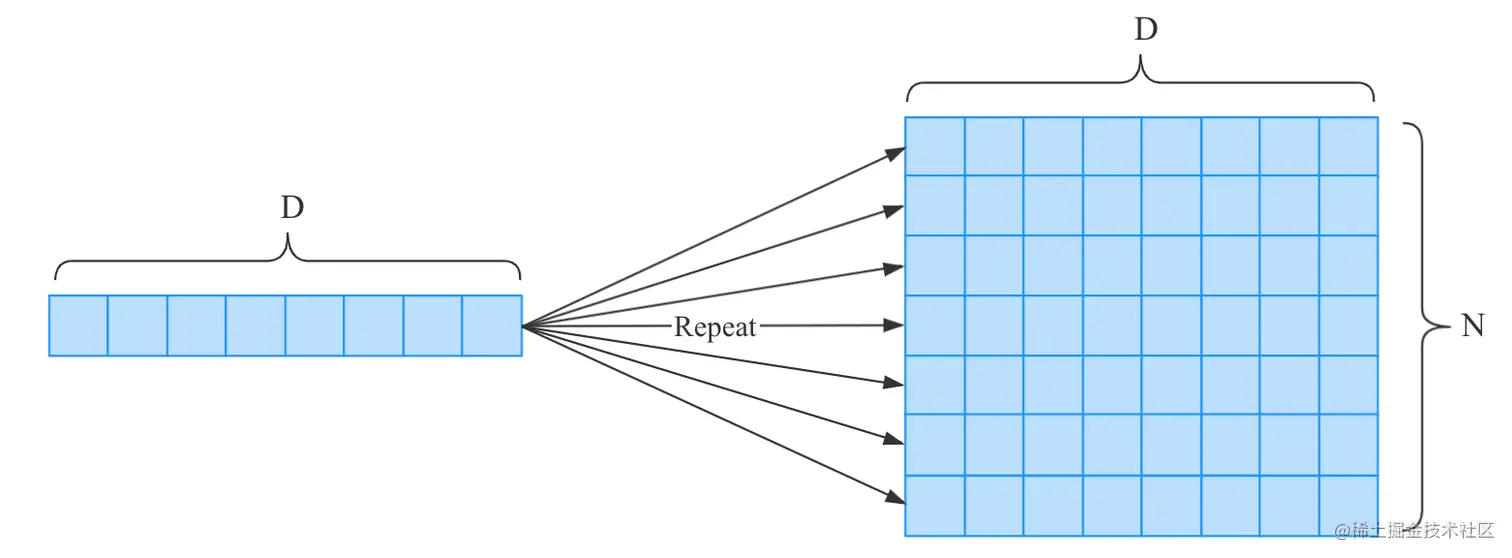
如上图,将长度为D的数组复制了N份,这个复制操作可以看成是N个分支操作,所以它的反向传播可以通过N个梯度的总和。
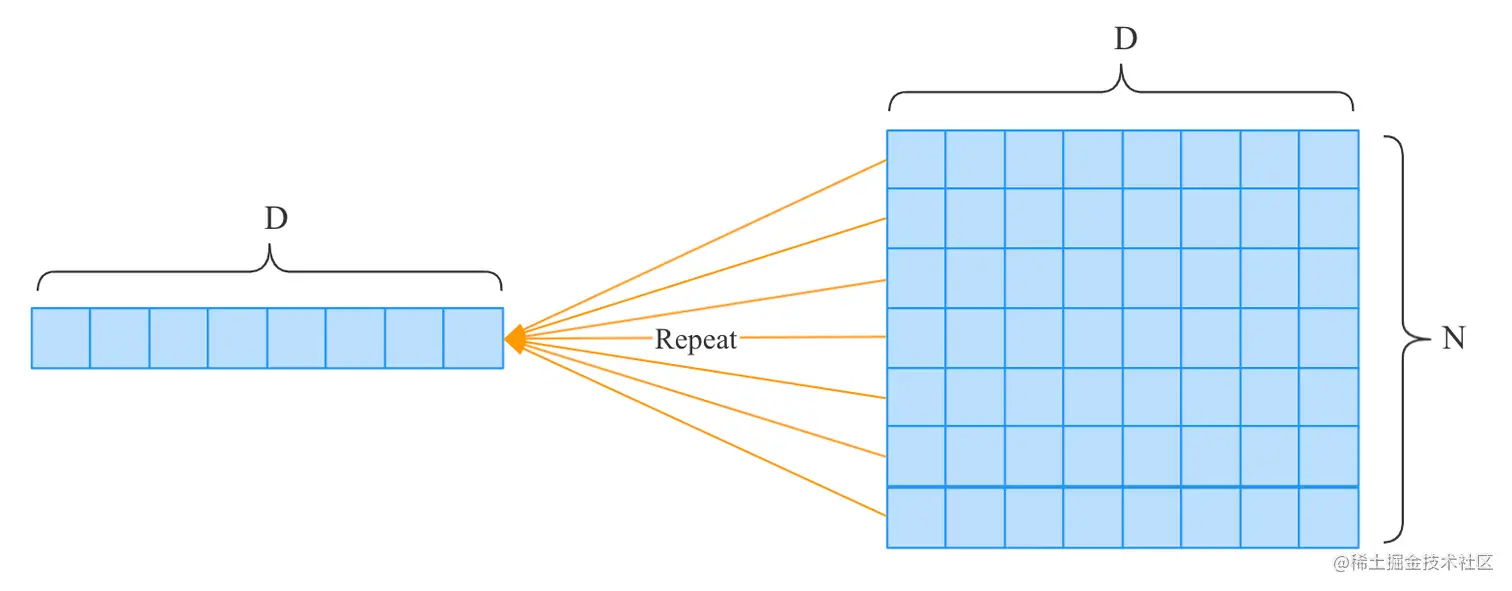
如果通过Numpy实现的化:
import numpy as np
D, N = 8, 7
x = np.random.randn(1,D)
y = np.repeat(x, N, axis=0)
dy = np.random.randn(N,D)
dx = np.sum(dy, axis=0, keepdims=True)
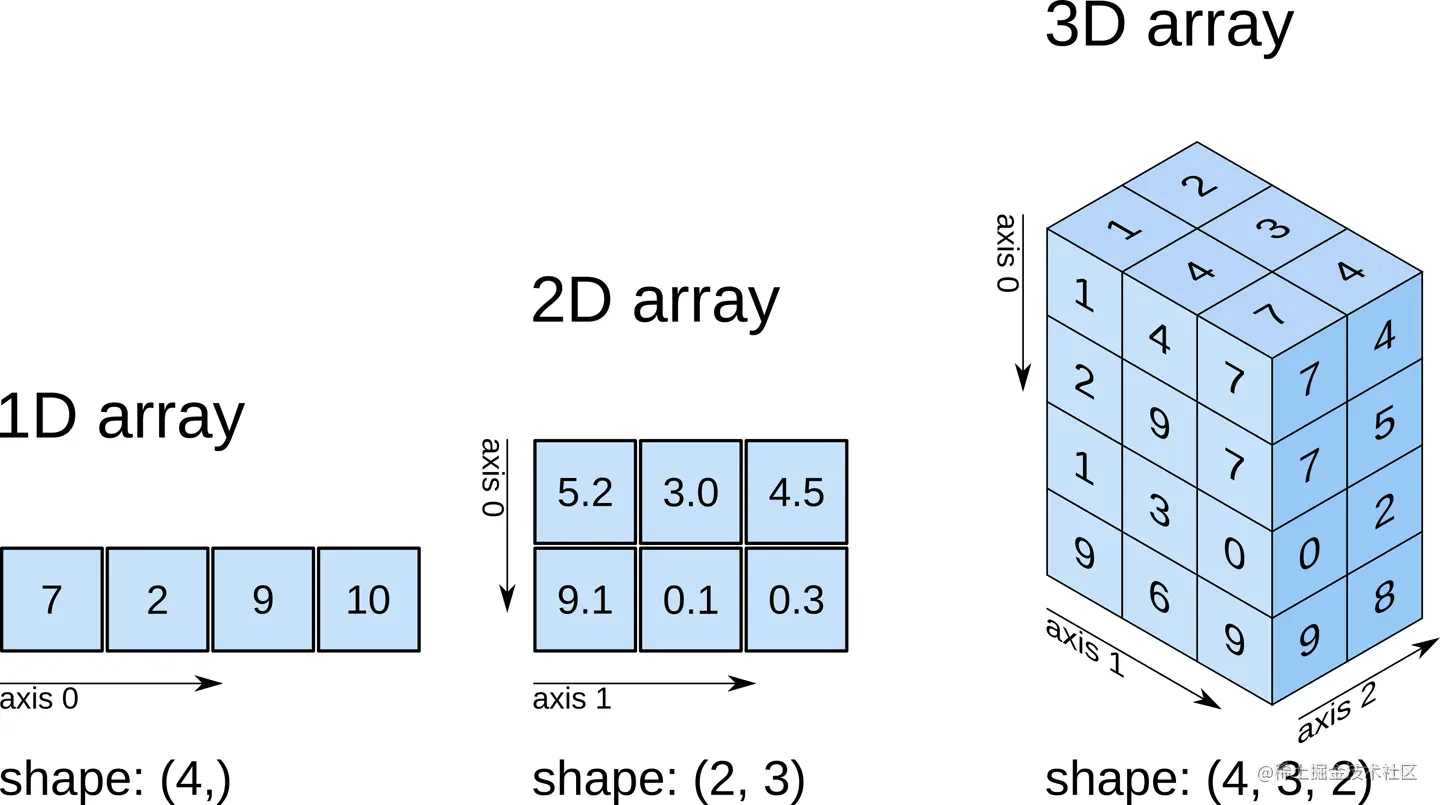
上图是简单介绍一下Numpy中axis的概念。当数组是1D的时候,只有一个轴,所以0轴的方向和2D的不同,要注意一下。
Numpy中的广播会复制数组的元素,可以通过这里的复制操作来表示。
Sum
Sum(求和)也是我们在深度学习中常用的运算。加法操作可以看成是求和的特殊形式。
考虑对一个N×D对数组沿着第行的方向求和,此时正向传播和反向传播如下所示。
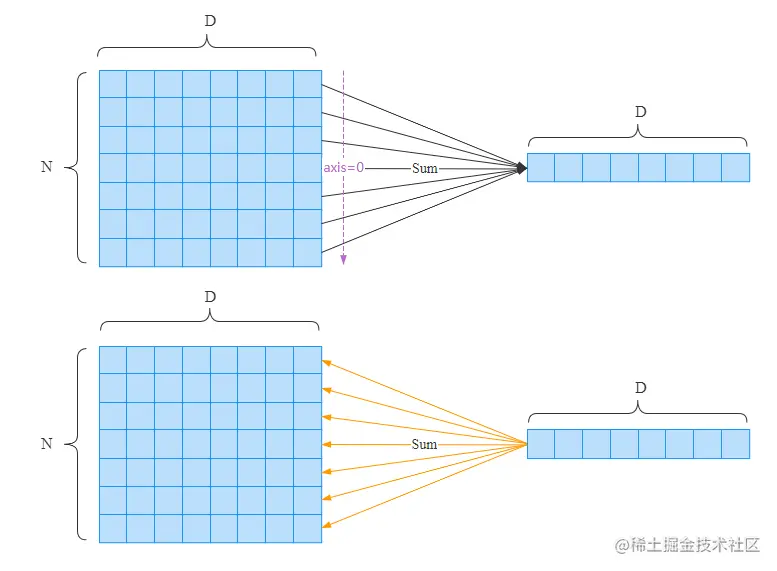
和加法一样,反向传播时将梯度(拷贝)分配到所有的箭头上,Sum操作是上面介绍的复制操作的逆向操作。即Sum的正向传播相当于复制操作的反向传播;Sum的反向传播相当于复制操作的正向传播。
我们也看一下通过Numpy实现的例子。
D, N = 8, 7
x = np.random.randn(N, D)
y = np.sum(x, axis=0, keepdims=True)
dy = np.random.randn(1, D)
dx = np.repeat(dy, N, axis=0)
Matmul
Matmul是矩阵乘法(Matrix Multiply),比如,考虑y=xW这个运算。x,W,y的形状分别是1×D、D×H和1×H。
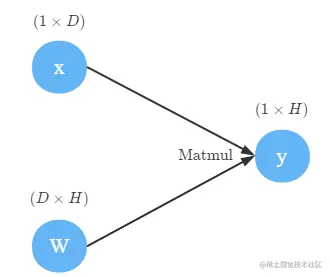
它的反向传播稍微有点复杂。我们先来了解下雅可比矩阵(Jacobian matrix)。
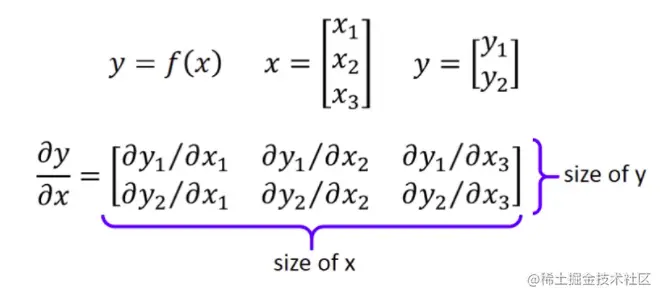
用每个y对每个x计算偏微分,计算得到的矩阵高度是y的个数,宽度是x的个数。
把y=xW展开得:
[y1,y2,⋯,yH]=[x1,x2,⋯,xD]⎣⎡W11W21⋮WD1W12W22⋮WD2⋯⋯⋱⋯W1HW2H⋮WDH⎦⎤
这里假设我们要计算L对x的导数∂x∂L。
我们先计算∂y∂L=[∂y1∂L,∂y2∂L,⋯,∂yH∂L]
接着计算y对x的导数∂x∂y,根据雅克比矩阵,有
∂x∂y=⎣⎡∂x1∂y1∂x1∂y2⋮∂x1∂yH∂x2∂y1∂x2∂y2⋮∂x2∂yH⋯⋯⋱⋯∂xD∂y1∂xD∂y2⋮∂xD∂yH⎦⎤
看起来挺复杂,但是如果我们先把y中第j个元素yj的等式写出来,就会很简单,如:
yj=x1⋅W1j+x2⋅W2j+⋯+xi⋅Wij+⋯+xD⋅WDj
所以 ∂xi∂yj=Wij,把∂x∂y完整的写出来,有
∂x∂y=⎣⎡W11W12⋮W1HW21W22⋮W2H⋯⋯⋱⋯WD1WD2⋮WDH⎦⎤=WT
所以∂x∂y=WT ,这就解释了为什么计算矩阵乘法的反向传播时,有个参数需要转置的。
有∂x∂L=∂y∂L∂x∂y=∂y∂LWT
x的形状是1×D,∂x∂L的形状和它保持一致,也是1×D。
∂y∂L的形状和y一样,是1×H
WT的形状是H×D。
在推导上面的公式时,不要被写法的复杂所迷惑了,只要我们展开把等式写出来,或者用一个简单的比如2×3的矩阵自己去推,就可以知道规律。
上面把yj=x1⋅W1j+x2⋅W2j+⋯+xi⋅Wij+⋯+xD⋅WDj写出来后,计算∂xi∂yj就很简单了,因为此时只与xi有关,对于x剩下的元素的导数都是0,变成了xiyj=0+0+⋯+Wij+⋯+0。
下面介绍几个简单的一元操作。
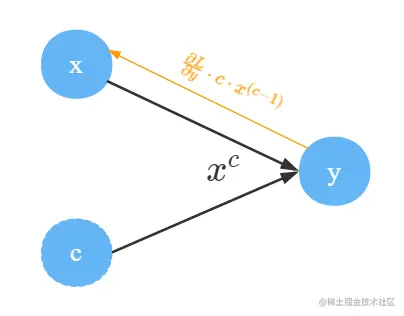
Pow
计算y=xc,我们把x看成是变量,c看成是常数。只有一个变量,因此定义为一元操作。∂x∂y=c⋅x(c−1),一元操作比较简单,因此正向传播和反向传播画到一张图里面。
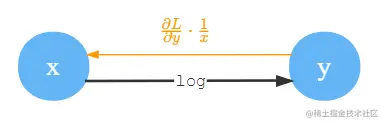
Log
取对数(Log),一般指的是以指数e为底。y=logx,那么∂x∂y=x1。
Exp
指数函数最简单了y=ex,∂x∂y=ex,原样返回。
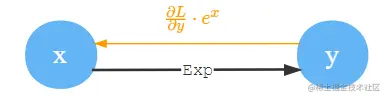
Neg
Neg是取负数的意思,y=−x,∂x∂y=−1,可以理解为y=−1⋅x。