Python爬虫实战之酷狗音乐爬取:想下载歌曲,但又要开启“人上人”服务,士可忍孰不可忍!
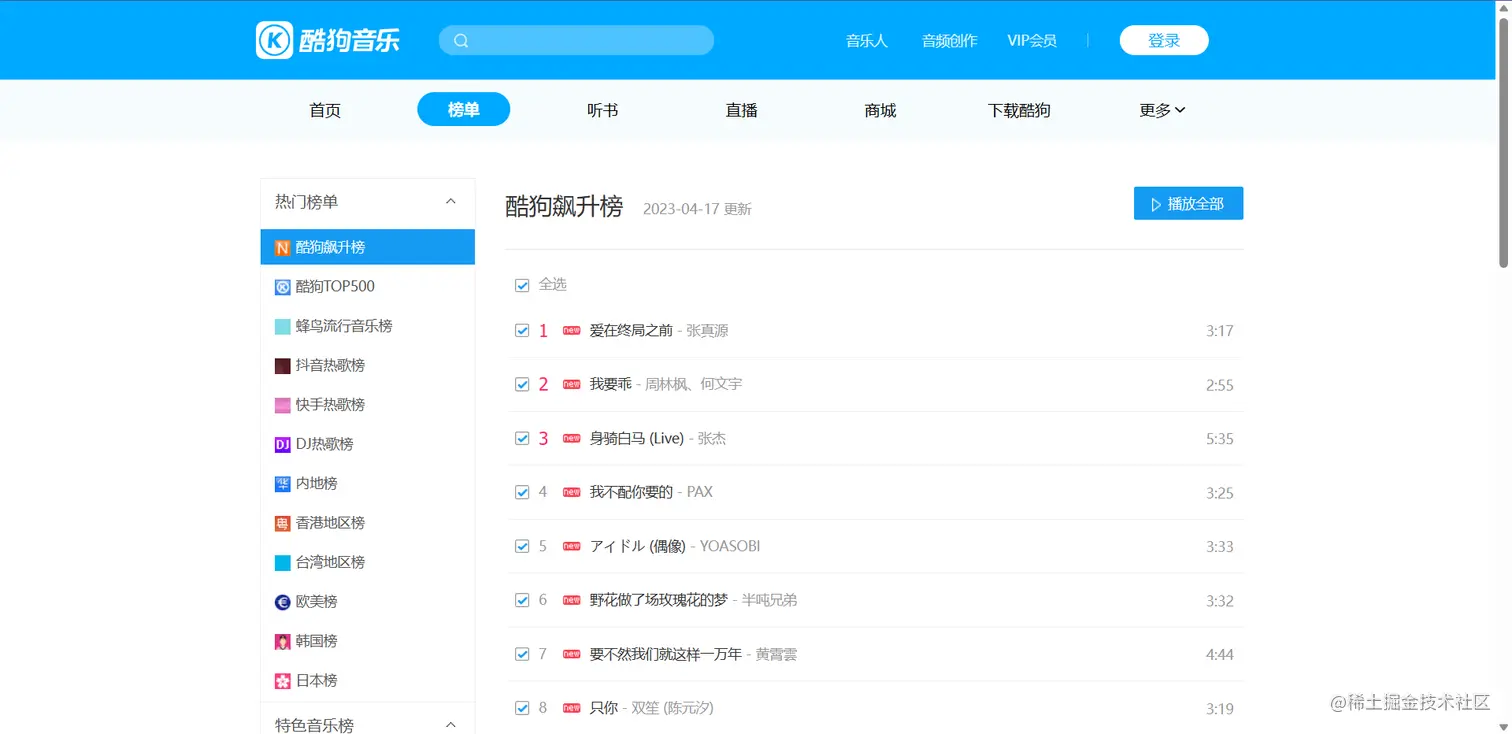
2,这里我要解释一下,这个代码不仅可以爬取酷狗飙升榜包括下面的其他榜单也是可以爬取的:

2.1,我们只需把榜单上的URL替换到这里就可以爬取到相应的歌曲加歌词,由于方便我们放在自己音乐网站上,在这里我更改了一下自己的代码,让我们更方便的放在自己的网站中
url = 'https://www.kugou.com/yy/rank/home/1-6666.html?from=rank'
request(url)
全部代码展示:
import requests
import re
from pprint import pprint
import os
import time
import tqdm
headers = {
'user-agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 14_3 like Mac OS X) AppleWebKit/534.30 (KHTML, like Gecko) Version/4.0 Mobile Safari/534.30',
'cookie': 'kg_mid=2d94fc2f6b14d23d5a9d31c5bbbb6d18; kg_dfid=3x87US2eiEz443jt7n29R06x; kg_dfid_collect=d41d8cd98f00b204e9800998ecf8427e'
}
def request(url):
html_id = requests.get(url, headers=headers)
music_id = re.findall('data-eid="(.*?)">', html_id.text)
name = re.findall('<li class=" " title="(.*?)"', html_id.text)
date = zip(name, music_id)
for name, music_id in date:
html_rexe = 'https://wwwapi.kugou.com/yy/index.php?r=play/getdata&encode_album_audio_id=' + music_id
html_jiexi = requests.get(url=html_rexe, headers=headers)
album_name = html_jiexi.json()['data']['audio_name']
mice_url = html_jiexi.json()['data']['play_backup_url']
lyrics = html_jiexi.json()['data']['lyrics']
save(album_name, mice_url, lyrics)
def save(album_name, mice_url, song_info_cleaned):
with open(f'酷狗音乐\\{album_name}.m4a', 'wb') as f:
music = requests.get(url=mice_url, headers=headers)
f.write(music.content)
with open(f'酷狗音乐\\{album_name}.txt', 'w+',encoding="utf-8")as a:
a.write(song_info_cleaned)
print(f'{album_name}下载完成')
if __name__ == '__main__':
try:
os.makedirs('酷狗音乐')
except:
pass
url = 'https://www.kugou.com/yy/rank/home/1-6666.html?from=rank'
request(url)
'''
酷狗飙升榜: https://www.kugou.com/yy/rank/home/1-6666.html?from=rank
酷狗top500:https://www.kugou.com/yy/rank/home/1-8888.html?from=rank
'''
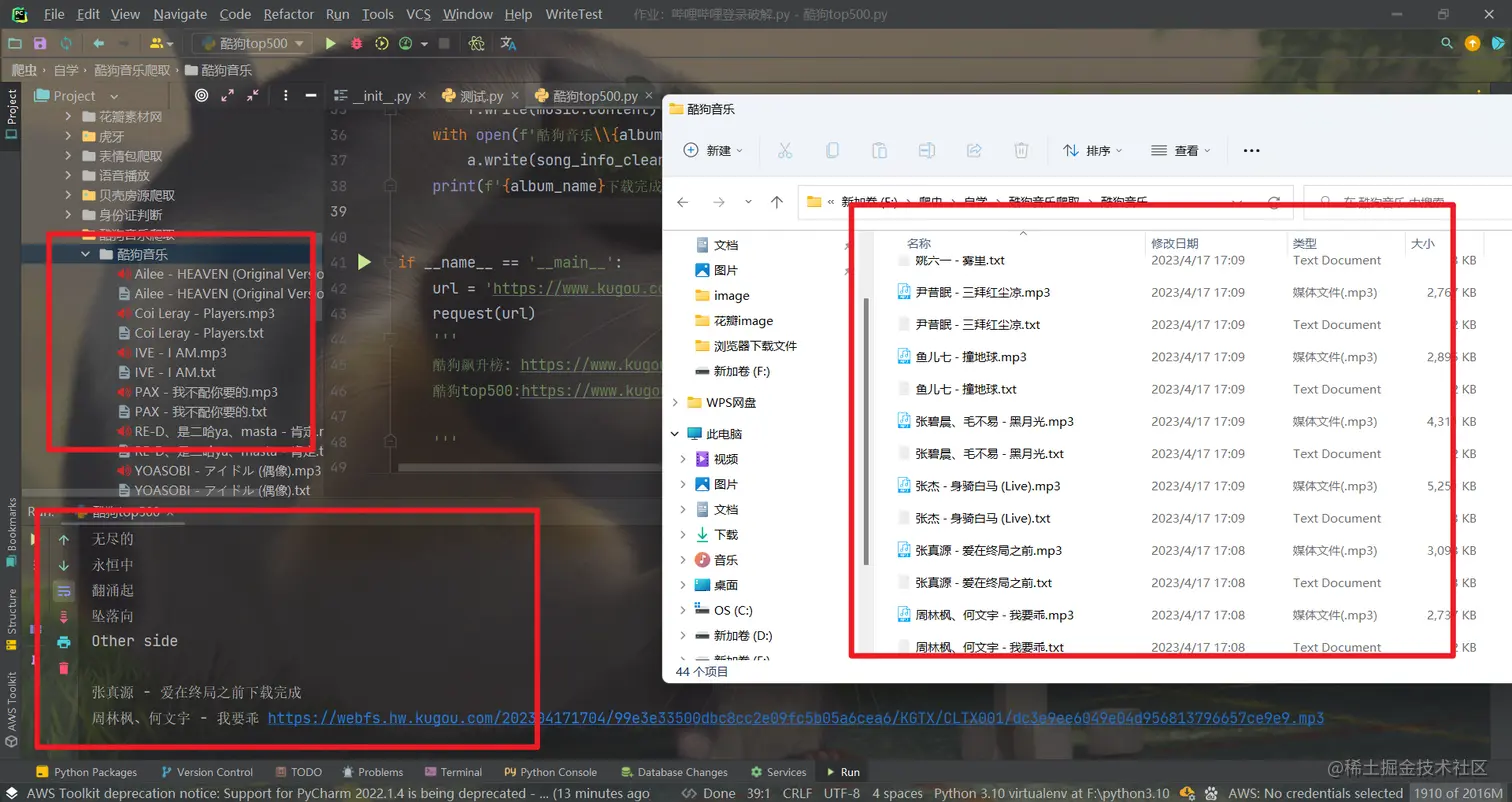
可以替换网址链接来爬取你想要爬取的音乐:
Python爬虫实战之QQ音乐爬取:
4.由于QQ音乐的歌词没有和音乐不在一个链接当中,所以这里就没有爬取到相应的歌词。
代码如下:
import requests
import json
class downloadMusic:
def __init__(self):
self.headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:55.0) Gecko/20100101 Firefox/55.0',
}
self.name='I Want My Tears Back'
def run(self,sn):
self.name=sn
session=requests.session()
firstjsonurl='https://c.y.qq.com/splcloud/fcgi-bin/smartbox_new.fcg?is_xml=0&format=jsonp&key={}&g_tk=5381&jsonpCallback=SmartboxKeysCallbackmod_top_search1467&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0'.format(self.name)
r=session.get(firstjsonurl).text
print(type(r))
print(r[39:-1:])
myjson=json.loads(r[39:-1:])
mid=myjson['data']['song']['itemlist'][0]['mid']
print(mid)
searchurl='''https://u.y.qq.com/cgi-bin/musicu.fcg?callback=getplaysongvkey2236996910208997&g_tk=5381&jsonpCallback=getplaysongvkey2236996910208997&loginUin=0&hostUin=0&format=jsonp&inCharset=utf8&outCharset=utf-8¬ice=0&platform=yqq&needNewCode=0&data={"req":{"module":"CDN.SrfCdnDispatchServer","method":"GetCdnDispatch","param":{"guid":"8665097290","calltype":0,"userip":""}},"req_0":{"module":"vkey.GetVkeyServer","method":"CgiGetVkey","param":{"guid":"8665097290","songmid":["'''+mid+'''"],"songtype":[0],"uin":"0","loginflag":1,"platform":"20"}},"comm":{"uin":0,"format":"json","ct":20,"cv":0}}'''
r=session.get(searchurl).text
print(r)
songjson=json.loads(r[32:-1:])
print(songjson)
header=songjson['req_0']['data']['sip'][0]
two=songjson['req_0']['data']['midurlinfo'][0]['purl']
songurl=header+two
with open("{}.mp3".format(self.name),'wb') as ms:
print(songurl)
raw = session.get(songurl, headers=self.headers)
content=raw.content
if len(content) >500:
ms.write(content)
print("下载成功")
else:
print("下载失败")
App=downloadMusic()
while 1:
songName=input("请输入歌曲名字:")
App.run(songName)


