Transformer 是一种著名的深度学习模型,现已经被广泛应用于自然语言处理、计算机视觉和语音处理等等各个领域。Transformer最初是作为机器翻译的序列到序列模型提出的。后来的工作表明,基于Transformer的预训练模型可以在各种任务上实现最优性能。因此,Transformer已经成为NLP中的主流架构。最近,使用Transformer来完成视觉任务成为一个新的研究方向,ViT(Vision Transformer)使用Transformer进行图像分类,DERT使用Transformer进行物体检测和分割。
Attention
self-Attention在Transformer中扮演者重要的角色。在介绍Transformer之前,我们先简单介绍一下Attention。
在Encoder-Decoder框架中,encoder用来将输入序列x=(x1,⋯,xTx)转换成一个上下文向量(context vector)c,encoder通常会采用RNN实现这一过程,设定时刻t的隐含状态(hidden state)为ht,其中ht=f(xt,ht−1)∈Rn,向量c是从隐含状态序列中生成的c=q({h1,⋯,hTx})。其中f和q都是非线性函数。
在Decoder中,Decoder通常通过c和所有先前预测单词{y1,⋯,yt′−1}预测下一个单词yt′,用公式表示就是p(yt∣{y1,⋯,yt−1},c)=g(yt−1,st,c),其中g是非线性函数,st表示decoder RNN的隐含状态,由st=f(st−1,yt−1,ct)计算得出。
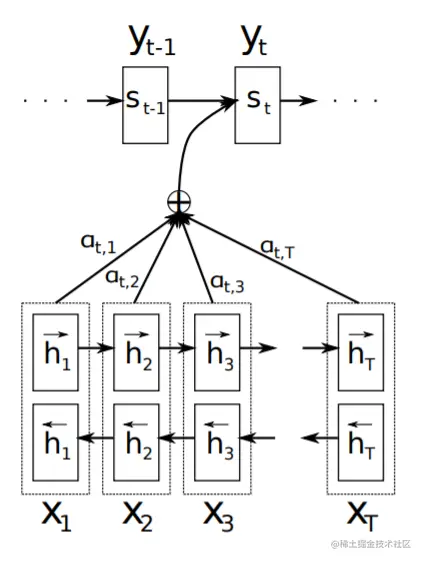
上下文向量ci由RNN的隐含状态hi的权重加权和得出,公式为ci=∑j=1Txαijhj,每个hj的权重αij由softmax函数求出,αij=∑k=1Txexp(eij)exp(eij)。其中eij是对齐模型(Alignment model),建模位置j的输入和在时刻i的输出的匹配分数。匹配分数基于decoder的隐含状态si−1和encoder的隐含状态hj计算,eij=a(si−1,hj)。
上述介绍的Attention是输入对输出的权重,输入序列x=(x1,⋯,xTx)对输出单词单词yt′的权重。显然,self-Attention是Attention机制中的一种。self-Attention则是自己对自己的权重,输入序列x=(x1,⋯,xTx)对x1、xTx的权重,将单个序列的不同位置联系起来,以计算序列的表示。
Transformer
Attention Is ALL You Need论文第一次提出了Transformer,完全基于注意力机制,在两个机器翻译任务上的实验表明,Transformer具有更高的质量,同时具有更高的并行性,所需的训练时间显著减少。
Transformer遵循encoder-decoder架构,使用encode和decoder的堆叠自我关注和逐点全连接层,结构见下图:
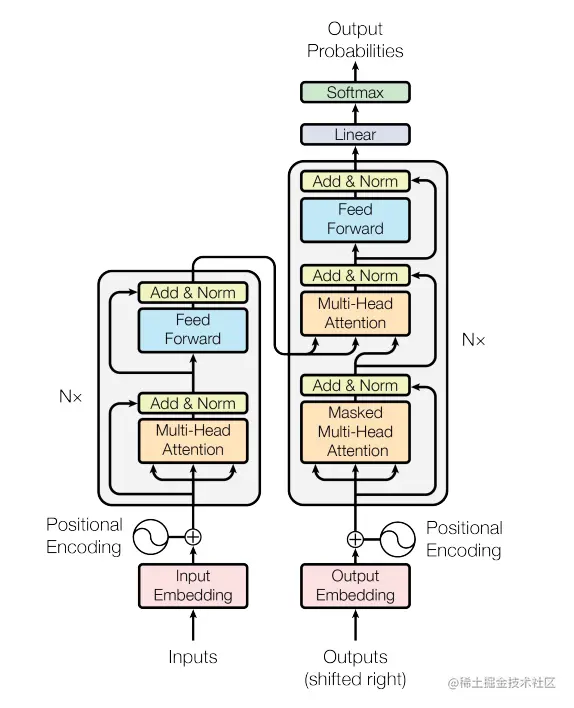
Encoder and Decoder
Encoder:Encoder由N=6个相同层的堆栈组成。每层有两个子层。第一种是多头自我注意机制(multi-head self-attention mechanism),第二种是简单的位置全连接前馈网络(a single, position-wise fully connected feed-forward network)。我们在两个子层的每个层周围使用残差连接(residual connection),然后使用层规范化(layer normalization)。也就是说,每个子层的输出是LayerNorm(x+Sublayer(x)),其中Sublayer(x)是由子层本身实现的功能。为了方便这些残差连接,模型中的所有子层以及嵌入层都会生成维数为512的输出, dmodel=512。
Decoder:Decoder也由N=6个相同层的堆栈组成。除了每个编码器层中的两个子层之外,解码器还插入第三个子层,该子层对编码器堆栈的输出执行多头注意。与编码器类似,我们在每个子层周围使用残差连接,然后进行层规范化。我们还修改了解码器堆栈中的自我注意子层,以防止位置转移到后续位置。这种掩蔽,再加上输出嵌入偏移一个位置的事实,确保位置i的预测只能依赖于位置小于i的已知输出。
Attention
注意函数可以描述为将查询(query)和一组键值对(key-value)映射到输出,其中查询、键、值和输出都是向量。输出可作为这些值的加权和,其中分配给每个值的权重由查询与相应键的兼容函数(compatibility function)计算。
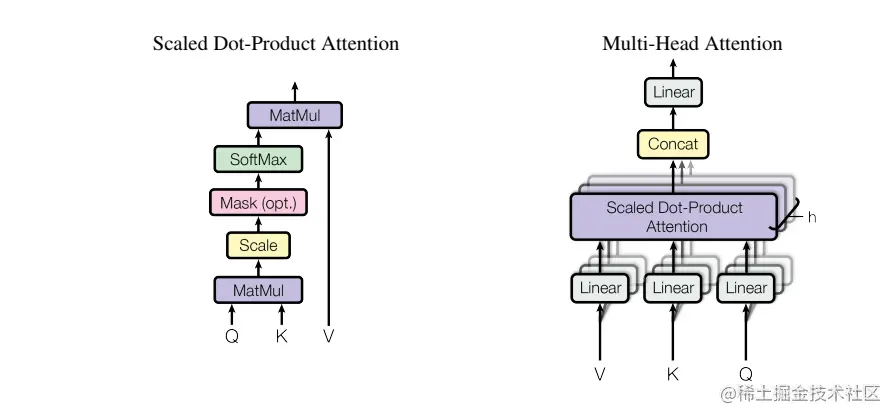
Scaled Dot-Product Attention
Transformer中的注意力为“缩放点乘注意力”。输入包括维度的查询和维度为dk的键,以及维度为du的值。我们计算带有所有键查询的点积,将每个键除以dk,然后应用softmax函数获这些值的权重。
在实践中,我们同时计算一组查询的注意函数,将它们打包成一个矩阵Q。键和值也打包到矩阵K和V中。我们将输出矩阵计算为:
Attention(Q,K,V)=softmax(dkQKT)V
Multi-Head Attention
将查询Q、键K和值V以不同的、学习到的线性投影h次分别线性投影到dk,dk和du维,在查询、键和值的每个投影版本上,并行执行注意函数,产生du维输出值。这些值被连接并再次投影,从而得到最终值。
多头注意允许模型共同关注来自不同位置的不同表征子空间的信息。
MultiHead(Q,K,V)=Concat(head1,⋯,headh)WOwhereheadi=Attention(QWiQ,KWiK,VWiV)
其中WiQ∈Rdmodel×dk,WiK∈Rdmodel×dk,WiQ∈Rdmodel×du,WiQ∈Rhdu×dmodel,。Transformer采用了h=8个平行的注意层或头部。对于每一个dk=du=dmodel/h=64,我们使用。由于每个头部的维数减小,总计算成本与全维单头部注意力的计算成本相似。
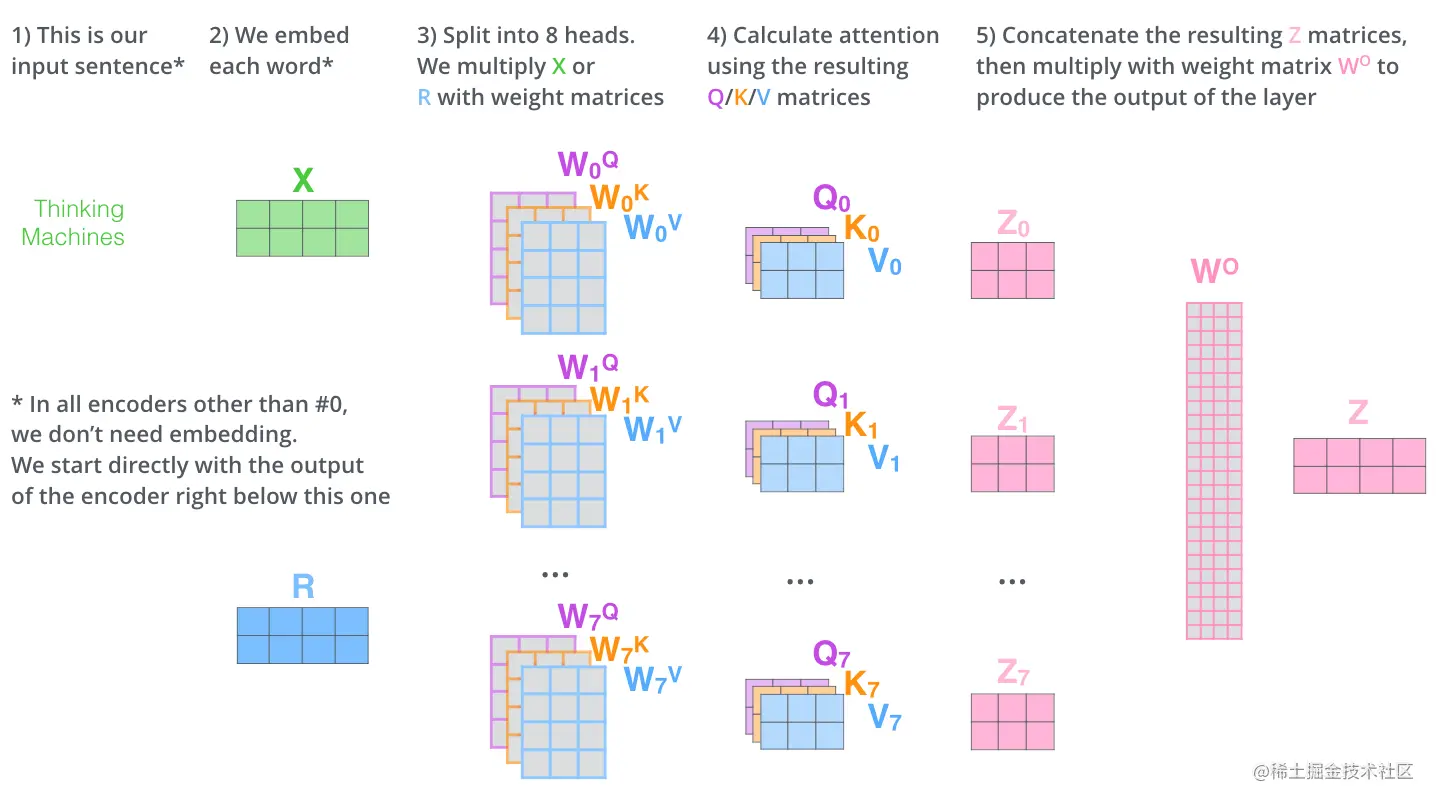
查询Q、键K和值V是通过输入词向量X分别和WQ、WK、WV做乘积得到的,如下图所示。
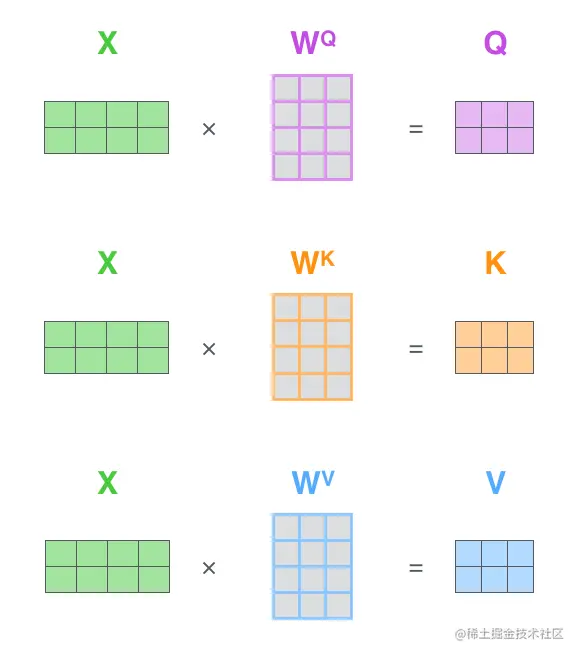
下图展示了Transformer的多头注意机制的计算过程:首先将输入句子进行嵌入化处理得到输入词向量X,然后再分别与WiQ、WiK、WiV并行计算得到Qi,Ki,Vi,紧接着进行Attention计算,得到Zi,最后将Zi连接起来,与权重矩阵WO进行计算得到输出结果Z。
Position-wise Feed-Forward Networks
除了注意子层之外,编码器和解码器中的每一层都包含一个完全连接的前馈网络,该网络分别相同地应用于每个位置。前馈网络包括两个线性变换,中间有一个ReLU激活。
FFN(x)=max(0,xW1+b1)W2+b2
虽然线性变换在不同位置上是相同的,但它们在层与层之间使用不同的参数。另一种描述方法是将其描述为两个核大小为1的卷积。输入和输出的维数为dmodel=512,内层的维数为dff=2048。
Transformer理论解释
在Non-local Neural Network中,定义深度神经网络中的一般非局部运算定义为:
yi=C(x)1∀j∑f(xi,xj)g(xj)
i是要计算其响应的输出位置(在空间、时间或时空中)的索引,j是枚举所有可能位置的索引。x是输入信号(图像、序列、视频;通常它们的特征)和y是输出信号,与x的大小相同。成对函数f计算i和所有j之间的标量(表示关联性等关系)。一元函数g计算位置j处输入信号的表示。响应通过系数C(x)标准化。
为了简单起见,我们只考虑g的线性嵌入的形式g(xj)=Wgxj。高斯函数的一个简单扩展是计算嵌入空间中的相似性,我们定义f函数为嵌入高斯函数:
f(xi,xj)=eθ(xi)Tϕ(xj)
其中θ(xi)=Wθxi和ϕ(xj)=Wϕxj是两个嵌入。设置C(x)=∑∀jf(xi,xj)。
与Transformer中的查询Q、键K和值V相比对,其中θ和ϕ对应于K和Q,其中g对应于K。其中C(x)1∑∀jf(xi,xj)是softmax计算,yi这个公式可以看做是Transformer缩放点乘注意力的理论表示,只不过Transformer在softmax之前将每个键除以dk。
Non-local Neural Network论文中介绍了f和g的几个版本,实验证明非局部模型对f和g的选择不敏感。当f为嵌入高斯分布时,Transformer中的自我注意模块是非局部操作在嵌入式高斯版本下的一个特殊情况。有趣的是:Transformer火爆,Non-Local却趋于平常。
参考
- The Illustrated Transformer
- Visualizing A Neural Machine Translation Model (Mechanics of Seq2seq Models With Attention)
- Neural Machine Translation by Jointly Learning to Align and Translate
- Attention is ALL You Need
- Non-local Neural Networks
- A Survey of transformers


