深度学习-推荐系统 第一章研读笔记(8)
引言
- 本文继续介绍推荐系统研读笔记,紧接上篇文章介绍过的推荐模型,本文将介绍已经具有深度学习雏形的组合模型
GBDT+LR -- 特征工程模型化的开端
- 由于上面FM,FFM模型不断引入交叉特征,会不可避免的产生组合爆炸和计算复杂度高的问题,因此引入了全新的GBDT+LR的组合模型解决方案
- 即:利用GBDT自动进行特征筛选和组合,进而生成新的离散特征向量,再把该特征向量作为LR模型的输入,结构如下
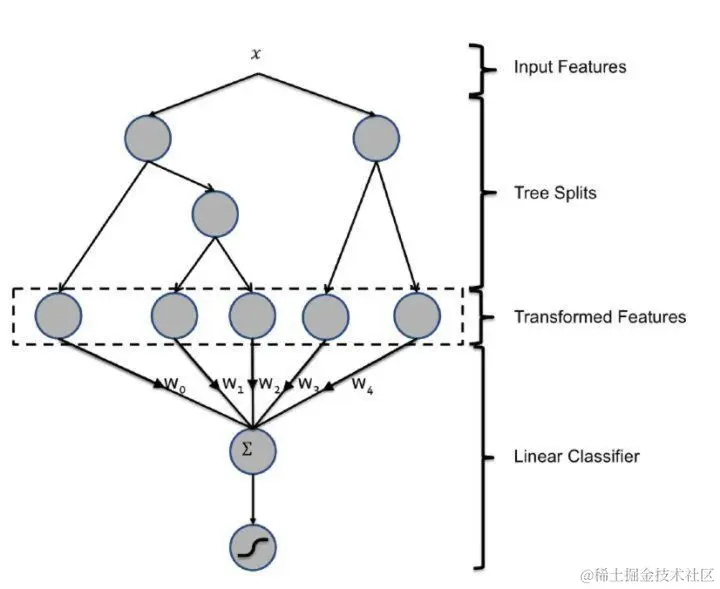
- 如图所示,GBDT与LR两部分是独立开来的
- [ GBDT](集成学习:GBDT(原理篇) - 掘金 (juejin.cn))
- GBDT+LR组合模型开启的特征工程新趋势
- GBDT+LR的提出,实现了真正的端到端训练,之前进行人工或者半人工的特征组合和特征筛选对算法工程师的经验和精力投入要求都比较高,还有就是从根本上改变模型结构,对模型设计能力的要求较高
7 LS-PLM模型 --阿里曾经的主流推荐模型
- LS-PLM模型又称MLR混合逻辑回归模型,从本质来看,其可以看作对逻辑回归的自然推广,它在逻辑回归的基础上采用分而治之的思路,先对样本进行分片,再在样本分片中应用逻辑回归进行CTR预估。(该思路类比于,当进行女装推荐的时候,男装进入数据集就会被影响)
- LS-PLM首先用聚类函数Π对样本进行分类(这里的Π采用了softmax函数对样本进行多分类),再用LR模型计算样本在分片中的具体的CTR,然后将二者相乘后求和。
f(x)=i=1∑mπi(x)∗ηi(x)=i=1∑m∑j=1meμjxeμix∗1+e−wix1(3.0)
- 其中,超参数m为分片数,当m=1的时候模型退化成普通的逻辑回归,m越大,模型的拟合能力越强。同样的,模型参数的规模也同m的增大而线性增长,模型收敛所需要的训练样本也随之增长
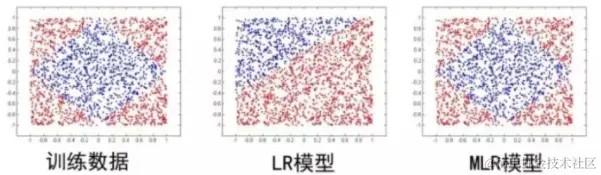
- LS-PLM模型的优点:
- 适用于工业级的推荐,广告等大规模稀疏数据的场景
- 端到端的非线性学习能力,可以自主挖掘出数据中蕴含的非线性关系,便于用一个全局模型对不同应用领域,业务场景进行统一建模
- 模型的稀疏性强,LS-PLM建模时候引入了L1 L2范数,可以使最终训练出来的模型具有较高的稀疏度,从而模型的部署更加轻量级。模型服务的过程中仅需使用权重非零的特征大大提高了在线推断的效率。
- LS-PLM已经有深度学习的大致雏形了。
结尾
- 以上就是个人研读笔记的第一章节全部内容,因为是笔记所以很多带有个人理解可能有错误注意甄别,还是推荐看原书学习
- 传统推荐模型的特征总结



