ORDER BY子句用于按升序或降序对数据进行排序。数据在一列或多列的基础上进行排序
语法
SELECT column-list
FROM table_name
[WHERE condition]
[ORDER BY column1, column2, .. columnN] [ASC | DESC];
参数说明
-
column_list:它指定要检索的列或计算。
-
table_name:它指定要从中检索记录的表。FROM子句中必须至少有一个表。
-
WHERE conditions:可选。 它规定必须满足条件才能检索记录。
-
ASC:也是可选的。它通过表达式按升序排序结果集(默认,如果没有修饰符是提供者)。
-
DESC:也是可选的。 它通过表达式按顺序对结果集进行排序。
例子
升序
SELECT * FROM EMPLOYEES
ORDER BY AGE ASC;
降序
SELECT * FROM EMPLOYEES
ORDER BY name DESC;
多列排序
SELECT * FROM EMPLOYEES
ORDER BY AGE,NAME ASC;
PostgreSQL GROUP BY子句用于将具有相同数据的表中的这些行分组在一起。 它与SELECT语句一起使用
GROUP BY子句通过多个记录收集数据,并将结果分组到一个或多个列。 它也用于减少输出中的冗余
语法
SELECT column-list FROM table_name
WHERE [conditions ]
GROUP BY column1, column2....columnN ORDER BY column1, column2....columnN
例子
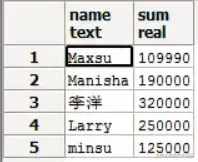
选择姓名与工资,并根据姓名分组
SELECT NAME, SUM(SALARY) FROM EMPLOYEES
GROUP BY NAME;
减少冗余
先插入几条冗余数据
INSERT INTO EMPLOYEES VALUES (6, '李洋', 24, '深圳市福田区中山路', 135000);
INSERT INTO EMPLOYEES VALUES (7, 'Manisha', 19, 'Noida', 125000);
INSERT INTO EMPLOYEES VALUES (8, 'Larry', 45, 'Texas', 165000);
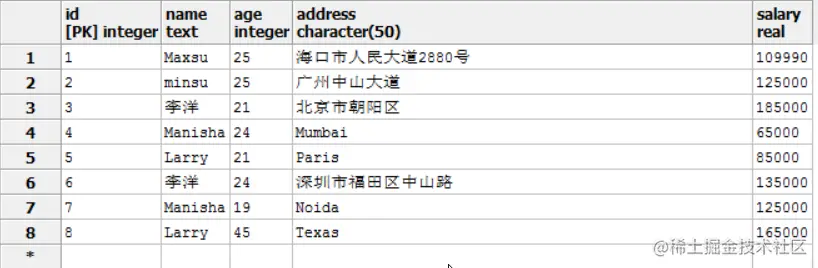
按名字统计薪水总额
SELECT NAME, SUM(SALARY) FROM EMPLOYEES
GROUP BY NAME;
重复记录被合并