Step 1: Function set
Target: Pw,b(C1∣x)
- If target >= 0.5, output C1
- Else, output C2
Based on previous knowledge in juejin.cn/post/722520…
- Pw,b(C1∣x)=σ(z)=1+exp(−z)1
- z=wx+b=∑iwixi+b
Function set: {fw,b(x)=Pw,b(C1∣x),∀w,∀b}
Step 2: Goodness of a function
Training data: {(x1,C1),(x2,C1),(x3,C2),…,(xN,C1)}
- Given w & b, its probability of generating the training data
L(w,b)=fw,b(x1)fw,b(x2)(1−fw,b(x3))…fw,b(xN)
- Find the w & b with maximum probability
w∗,b∗=argmaxw,bL(w,b)=argminw,b−lnL(w,b)
- Define y^n: 1 for C1, 0 for C2
−lnL(w,b)=−∑n(y^nlnfw,b(xn)+(1−y^n)lnfw,b(xn)) -- cross entropy between two Bernoulli distributions
Step 3: Find the best function
Gradient descent:
- ∂wi∂−lnL(w,b)=∑n−(y^n−fw,b(xn))xin -- larger difference, larger update
Discussions
Compare with linear regression

Why not square error in loss function?
∂wi∂L=∂wi∂(fw,b(x)−y^)2=2(fw,b(x)−y^)fw,b(x)(1−fw,b(x))xi
When y^n=1, (similar when 0)
- If fw,b(xn)=1, close to target, ∂wi∂L=0
- If fw,b(xn)=0, far from target, ∂wi∂L=0 -- update slow
Cannot tell close to / far from target with small ∂wi∂L
Discrimitive v.s. Generative
See the generative method in juejin.cn/post/722520…

Differnt function because of different assumptions
- in the generative model: distribution assumption, naive bayes, etc.
Usually discrimitive model has a better performance

Limitation of logistic regression
Linear boundary -> feature transformation
How to find a good transformation?
-> cascading logistic regression models -- neural network

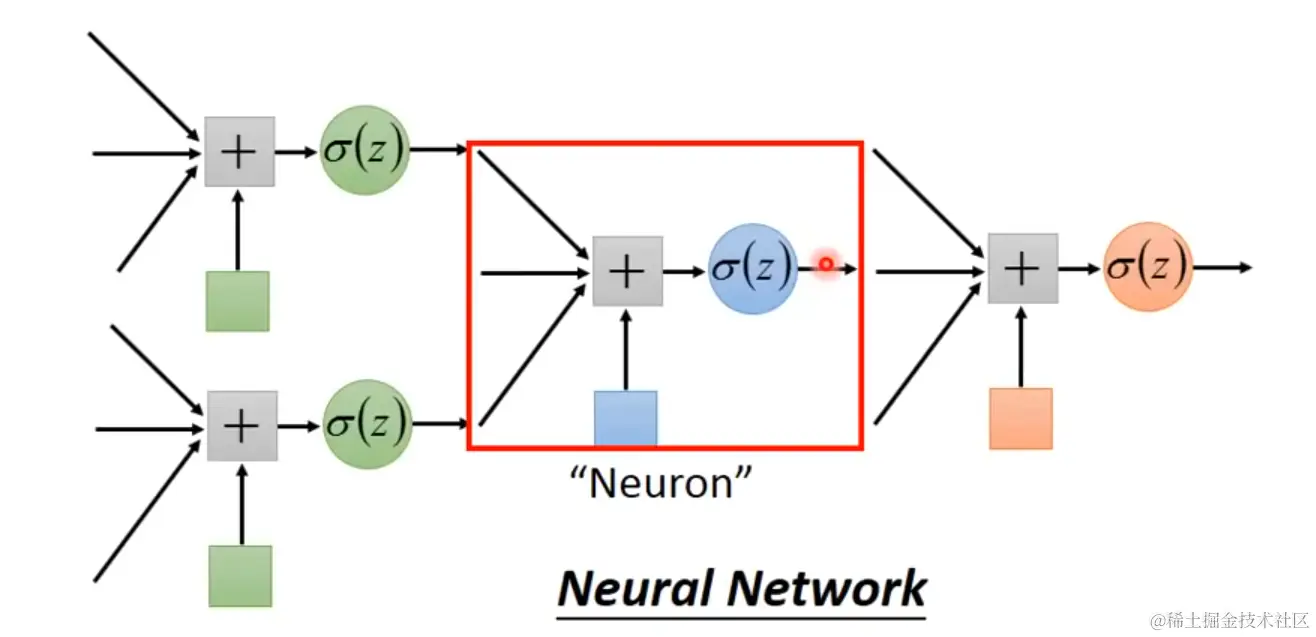
Multi-class classification
Softmax: yi=P(Ci∣x)=ezi/∑jezj, where zi=wix+bi
- 0<yi<1
- ∑iyi=1
Cross entropy: −∑iy^ilnyi
- y^=(y^1,y^2,…) - target
- If x∈C1, y^=(1,0,0,…)


