
Title: Learning to Fuse Monocular and Multi-view Cues for Multi-frame Depth Estimation in Dynamic Scenes
Paper: arxiv.org/pdf/2304.08…
Code: github.com/ruili3/dyna…
导读
多帧深度估计依赖静态场景下的多视角一致性获得高精度结果。然而,在室外场景中,由于存在各类违反静态假设的运动区域,导致多帧方法在动态区域的精度显著降低。本文提出了一个适用于动态场景的多帧深度估计网络,其通过提出的跨线索注意力机制Cross-cue attention, 有效结合并进一步提升多帧/单帧深度线索的优势,在无需引入任何动态区域分割情况下, 实现显著优于单/多帧方法动态区域深度估计效果。
动机
以往多帧深度估计方法采用“分割动态区域+单帧估计补偿”的思路解决动态区域深度估计难题。然而
- 方法对动态区域分割结果高度敏感,分割精度引入了额外的不确定性
- 动态区域精度往往受限于单帧估计效果,难以实现基于单帧的显著提升
论文基于此探索了以下问题:
能否在不引入动态区域分割的情况下,实现显著优于多帧/单帧精度的动态深度结果?

单帧/多帧线索的表现(从左至右:深度图,误差图,重建点云)
如上图所示,通过进一步分析单帧/多帧线索在动态场景中的表现,论文发现,单帧线索能更好捕捉动态物体的外形,但静态场景的精度不足;而多帧方法静态精度很高,但动态区域场景结构存在明显变形。两个线索的互补特性展示了相互提升的潜力:
- 多帧静态结构信息可增强单帧整体精度,进而引领单帧动态区域精度的进一步提升
- 单帧动态结构信息可用于增强多帧动态区域精度,最终输出高精度的动态场景深度
为实现这一目标,本文提出跨线索的融合模块Cross-cue Fusion module,无需显式分割即可实现两个深度线索的有效融合。
方法
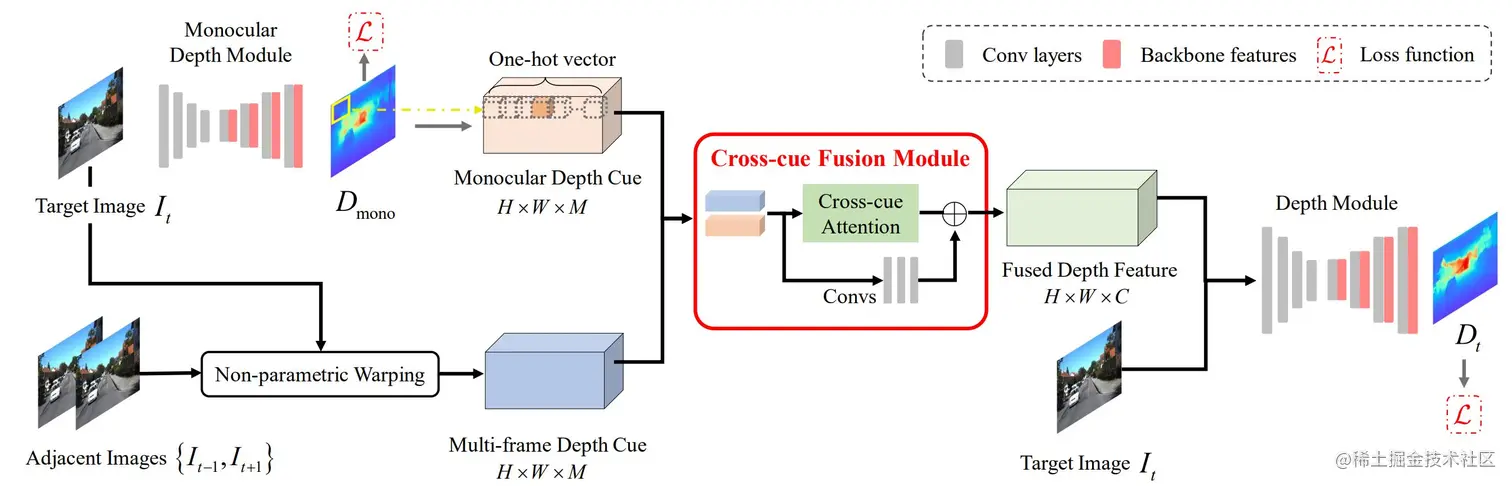
方法整体框架
给定目标图像It∈RH×W,相邻帧(It−1,It+1)以及场景内、外参数K,T,本文目标为利用单/多帧信息的融合,估计目标帧It的深度值Dt∈RH×W. 如上图所示,论文主要模块包括:单/多帧线索(Monocular/Multi-frame Depth Cues)的代价体构造,单/多帧深度信息的跨线索融合模块 (Cross-cue Fusion),以及深度图回归网络(Depth Module)等。
单/多帧代价体构造
单/多帧代价体分别表示了单/多帧信息所传递的深度线索。多帧代价体构造遵循多视图立体匹配代价体的构建方式:给定一系列深度平面假设d∈{dk}k=1M,采用平面扫描(Plane-sweeping)方式,对目标图It中任一像素求取其与相邻帧对应极线上采样点的匹配相似度。
进而获得多帧匹配代价体Cmulti ∈[0,1]H×W×M。对于Cmulti 中每个像素代表的匹配向量Cmulti (i,j)∈RM,其中较大相似度的通道表示其代表的深度值更接近真实深度。
针对单帧代价体的构造,首先采用简单的U-Net生成目标帧It的单帧深度图Dmono =fθmono (It), 为了将单帧结果与多帧代价体尺寸对齐以便于融合,我们将单帧深度图转换为深度代价体Cmono ∈{0,1}H×W×M。代价体中每个空间维度上的像素Cmono (i,j)∈RM被编码为one-hot向量
Cmono ,(i,j)[k]={1∣dmono ∈(dk−1,dk]}k=1M.
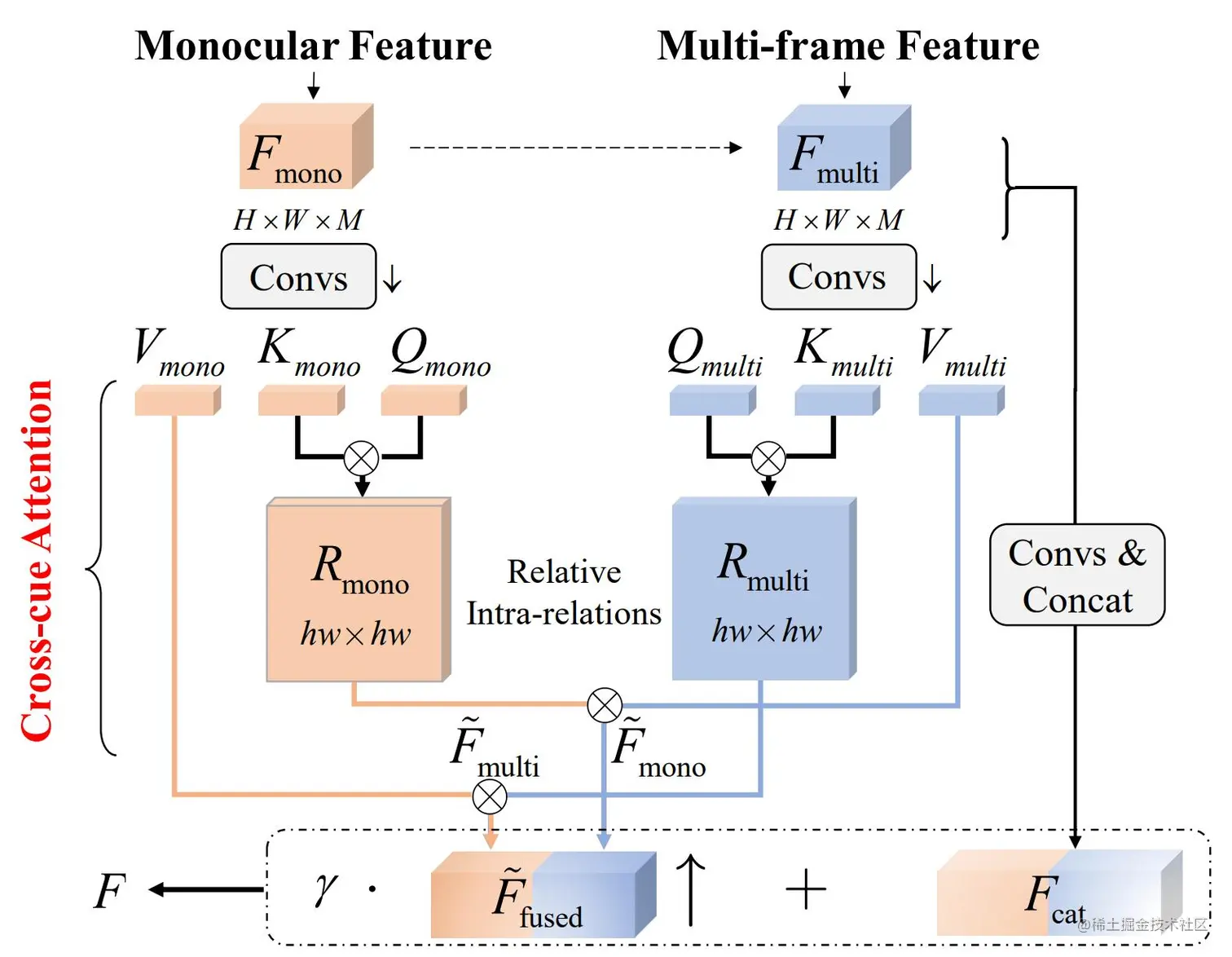
跨线索融合模块
跨线索融合模块
获取单/多帧代价体Cmono,Cmulti后,本文提出跨线索融合模块(Cross-cue Fusion Module,CCF)将两者进行融合并相互提升。如上图所示,其由跨线索注意力机制(Cross-cue attention,CCA)和残差连接构成。
我们首先将Cmono,Cmulti通过浅层CNN处理后获取两者特征Fmono,Fmulti∈Rh×w×M,进而利用跨线索注意力机制(CCA)将两者相互增强
Fmulti =CCAmulti (Fmono ,Fmulti ),Fmono =CCAmono (Fmulti ,Fmono ).
跨线索注意力机制(CCA)编码了各深度线索内部可用于相互增强的结构特性,从而以无显式分割方式获取增强后的特征Fmulti,Fmono。将特征连接后得到融合特征Ffused,并利用残差连接j将Ffused 与原代价体的信息Fcat结合
F=γFfused↑+Fcat.
其中Fcat代表Cmono,Cmulti连接后经浅层CNN处理的特征,γ为可学习参数。我们将融合后特征F输入深度估计网络(Depth Module),从而得到最终的深度估计Dt。
跨线索注意力机制
作为跨线索融合模块的关键部分,跨线索注意力(CCA)有两个并行分支,分别用以增强多帧和单帧特征。为表达简洁,我们以Fmulti =CCAmulti (Fmono ,Fmulti )为例阐述方法过程。
对于给定的单、多帧特征Fmono,Fmulti∈Rh×w×M,利用卷积将Fmono转换为query特征Qmono和key特征Kmono,同时将Fmulti转换为value特征Vmono。我们利用编码自单帧线索的Qmono和Kmono计算内部相对注意力权重Rmono,其构建了单帧深度线索内部的相对结构关系
Rmono =Softmax(Qmono ⊗Kmono T),
我们进而将单帧线索中相对结构关系信息通过注意力中的矩阵相乘操作传递至Vmulti代表的多帧特征,得到增强后的Fmulti
Fmulti=Rmono⊗Vmulti.
利用多帧特征增强单帧特征也遵循类似的计算方式Fmono=CCAmono(Fmulti,Fmono)。

动态区域(红点)的单帧内部结构信息($R_{\text {mono}}$)和多帧内部结构信息($R_{\text {mono}}$)可视化
CCA在跨线索增强中的区域选择特性
我们发现,跨线索注意力机制(CCA)能通过可学习方式选择性传递单/多帧线索中有助于提升对方的结构信息,从而避免了引入显式的动态物体分割方法。如上图所示,我们对动态区域采样点(第1列红点)进行跨线索注意力图Rmono,Rmulti可视化,其展示了网络所学习到的、各深度线索中有助于提升对方的结构信息分布。其中
- 单帧线索(第2列)所传递的信息集中于动态区域周边,表明网络可学习单帧线索在动态区域的有用信息,进而传递至多帧线索
- 而多帧线索(第3列)所传递的信息分布于较广的静态区域,表明网络可学习多帧线索在静态区域的有用信息,进而传递至单帧线索
CCA在不同深度线索下信息传递的区域选择特性,表明了其在无需动态区域分割条件下进行高精度深度估计的潜力,从而避免了引入额外的分割机制。
实验结果
KITTI结果
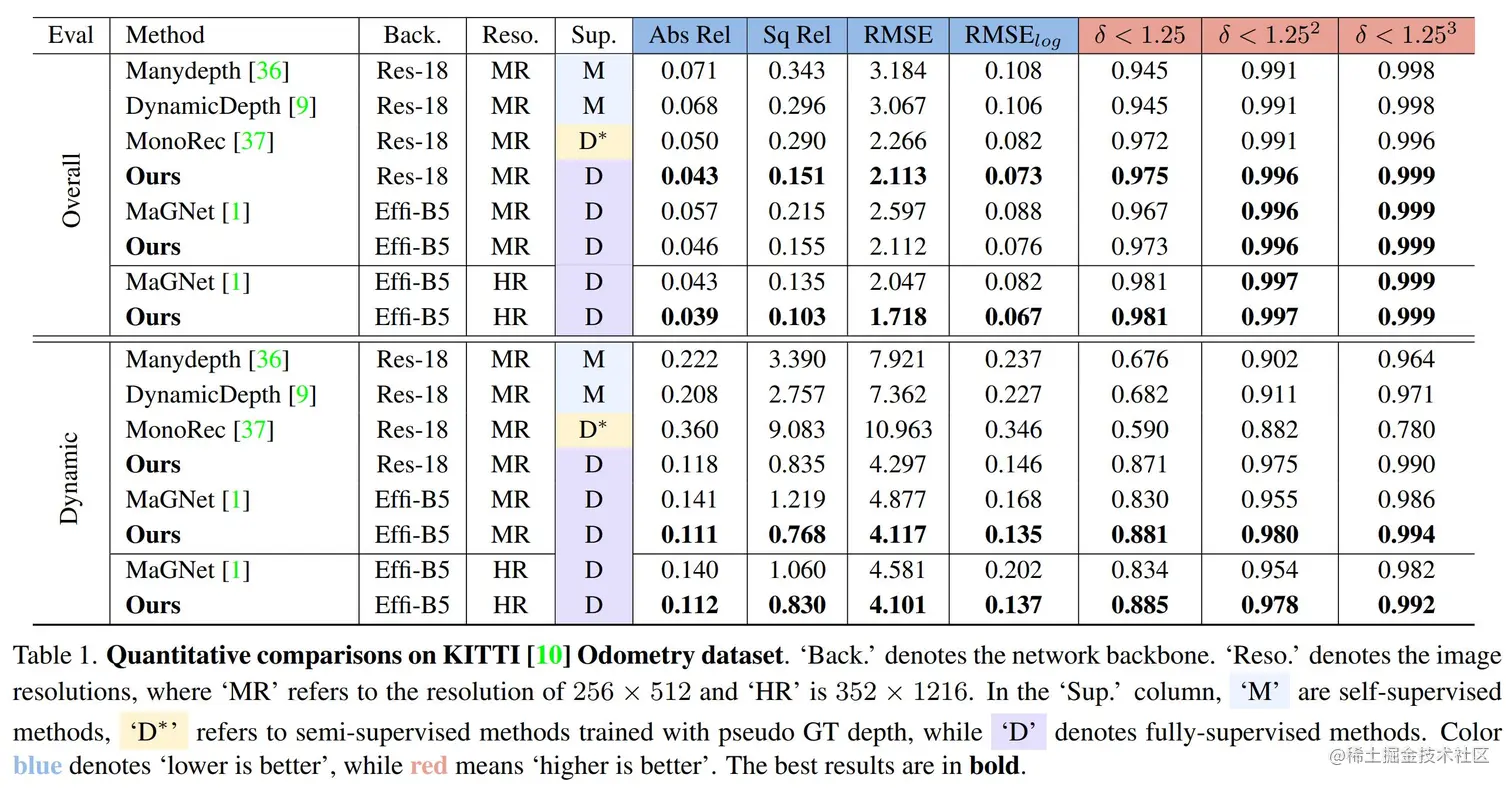
KITTI Odometry数据集评估结果
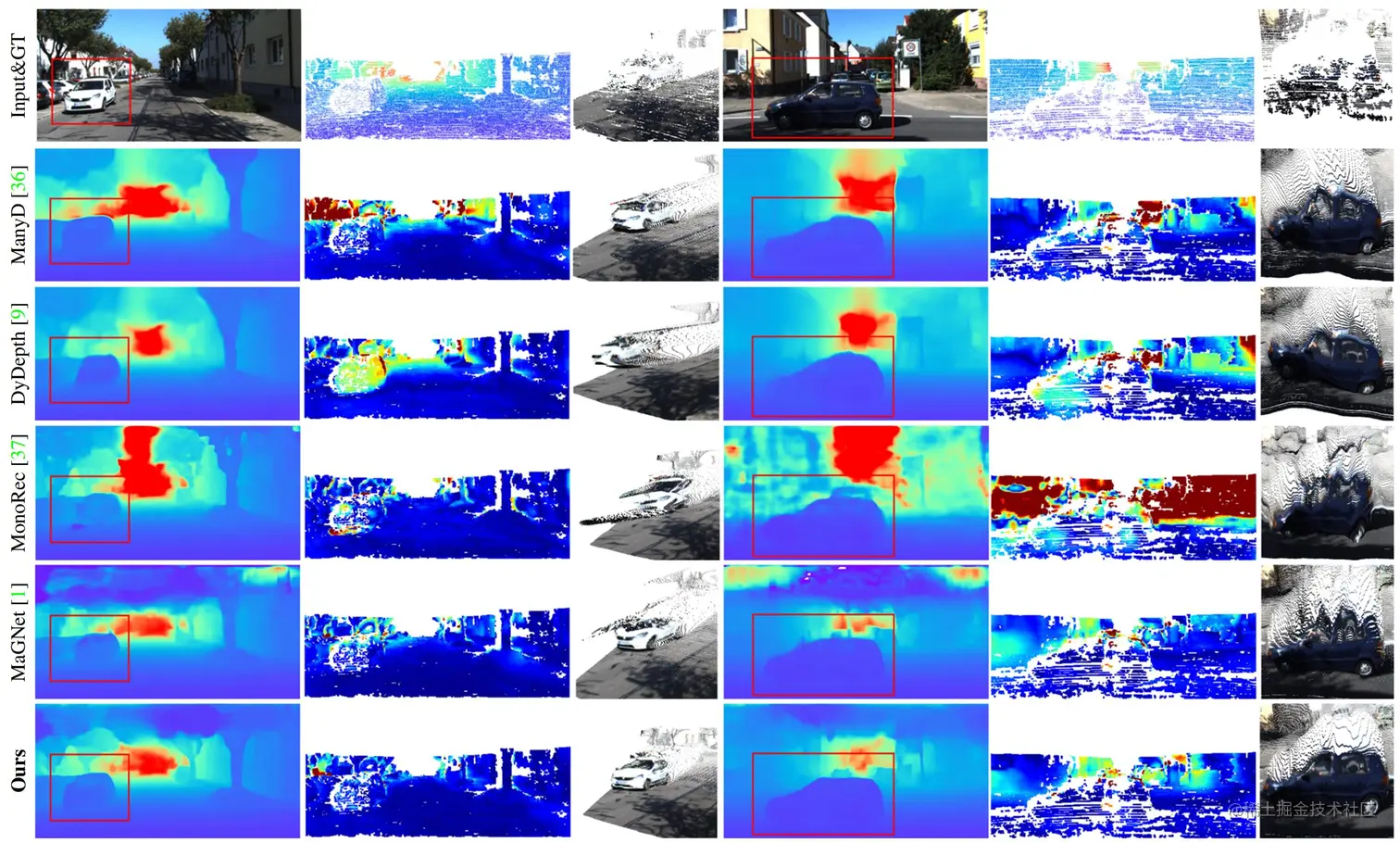
KITTI Odometry数据集可视化结果
如上所示,论文在KITTI Odometry数据集开展比较并分别展示多帧动态场景整体精度和动态区域精度。本方法动态误差相较以往最优方法显著降低超过 21%(Abs.Rel 0.141 → 0.111),同时达到了最优的全局深度估计精度。可视化结果表明,方法可显著降低动态区域深度估计误差,并可重建更符合的动态物体结构的三维点云。
跨数据集泛化性比较
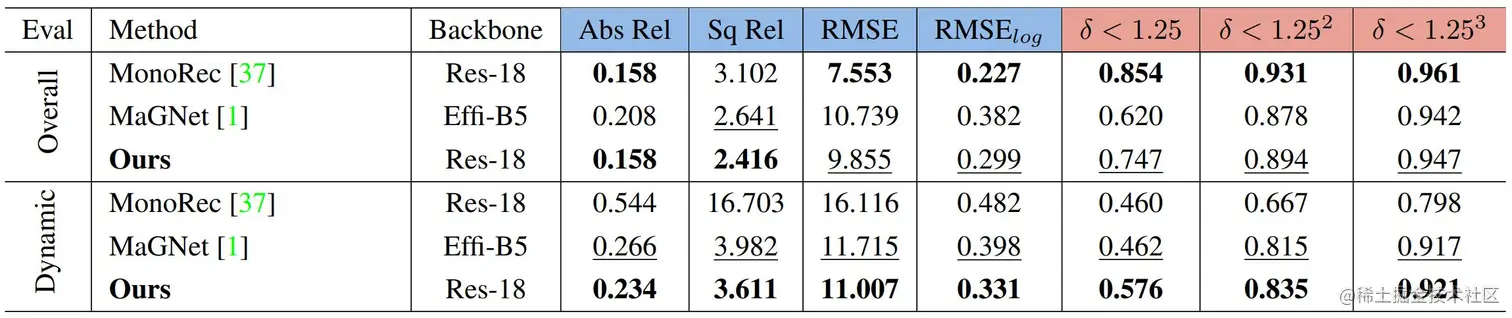
DDAD数据集上的泛化性评估
将KITTI训练的模型在DDAD数据集进行测试,实验结果表明,论文可实现与当前最优方法同等的整体泛化精度,同时在动态物体精度上达到优于当前先进方法的泛化性能。
相对单帧的能力提升&可扩展性评估
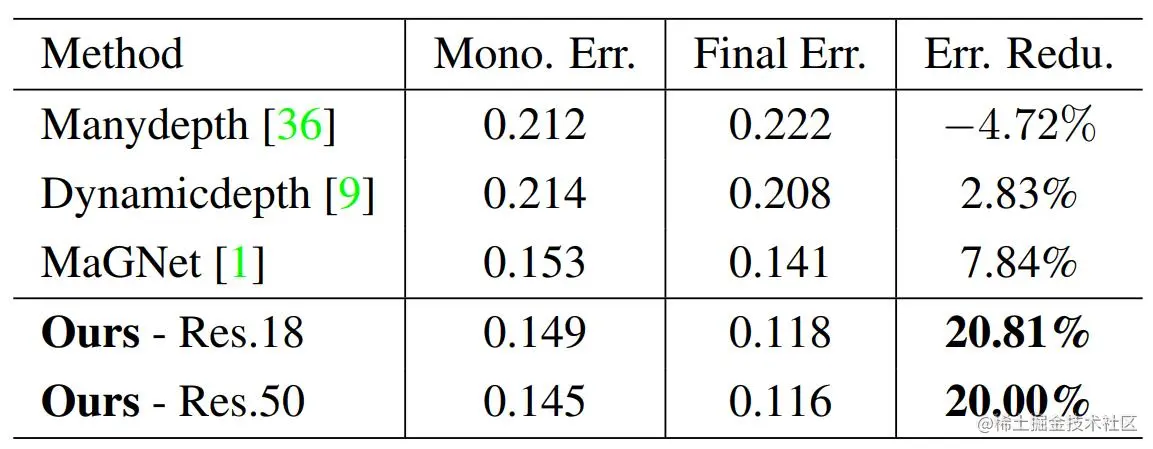
动态物体相对单帧估计提升以及模型可扩展性评估
在以往方法中,单帧估计精度是制约动态区域效果的重要因素。论文展示了不同方法相对于其各自单帧网络在动态物体区域的性能提升。论文在动态区域估计误差比其单帧分支估计误差降低21.81%,显著优于其他方法(上表1~3行)。同时,在应用更优单帧估计网络的情况下,论文实现了基于更优单帧性能的同等幅度提升(上表3-4行),展示了其灵活性及可扩展性。
总结
本论文提出了一种新的动态场景多帧深度估计方法。通过更好对单/多帧深度线索进行融合并相互提升,实现了在无需运动分割情况下的高精度动态区域深度估计。实验证明,方法实现更优整体/动态区域深度估计效果同时,具有良好的泛化性和可扩展性。
CVHub是一家专注于计算机视觉领域的高质量知识分享平台,全站技术文章原创率常年高达99%,每日为您呈献全方位、多领域、有深度的前沿AI论文解决及配套的行业级应用解决方案,提供科研 | 技术 | 就业一站式服务,涵盖有监督/半监督/无监督/自监督的各类2D/3D的检测/分类/分割/跟踪/姿态/超分/重建等全栈领域以及最新的AIGC等生成式模型。欢迎关注微信公众号CVHub或添加小编好友:cv_huber,备注“知乎”,参与实时的学术&技术互动交流,领取CV学习大礼包,及时订阅最新的国内外大厂校招&社招资讯!


