

我正在参加「掘金·启航计划」
背景
如果是通过Django或Flask实现WEB应用的话,写起来比较麻烦。偶然发现一个Python第三方库---PyWebIO,可以用来快速构建WEB应用。于是,用它来尝试写一个简易的造数据平台,用于批量造一些业务数据,辅助测试。
一、简介
1.什么是pywebio
PyWebIO是一个可以用来快速构建WEB应用的开源的Python第三方库。以下内容来自官方简介:
PyWebIO提供了一系列命令式的交互函数来在浏览器上获取用户输入和进行输出,将浏览器变成了一个“富文本终端”,可以用于构建简单的Web应用或基于浏览器的GUI应用。 使用PyWebIO,开发者能像编写终端脚本一样(基于input和print进行交互)来编写应用,无需具备HTML和JS的相关知识; PyWebIO还可以方便地整合进现有的Web服务。非常适合快速构建对UI要求不高的应用。
官方教程:pywebio.readthedocs.io/zh_CN/lates…
2.特性
- 使用同步而不是基于回调的方式获取输入,代码编写逻辑更自然
- 非声明式布局,布局方式简单高效
- 代码侵入性小,旧脚本代码仅需修改输入输出逻辑便可改造为Web服务
- 支持整合到现有的Web服务,目前支持与Flask、Django、Tornado、aiohttp、 FastAPI(Starlette)框架集成
- 同时支持基于线程的执行模型和基于协程的执行模型
- 支持结合第三方库实现数据可视化
二、安装及用法示例
1.安装
pip3 install -U pywebio # 安装最新版
pip3 install pywebio==1.4.0 # 安装指定版本
系统要求: PyWebIO要求 Python 版本在 3.5.2 及以上
2.示例
以下示例来自官方教程,这是一个使用PyWebIO计算 BMI指数 的脚本:
from pywebio.input import input, FLOAT
from pywebio.output import put_text
def bmi():
height = input("请输入你的身高(cm):", type=FLOAT)
weight = input("请输入你的体重(kg):", type=FLOAT)
BMI = weight / (height / 100) ** 2
top_status = [(14.9, '极瘦'), (18.4, '偏瘦'),
(22.9, '正常'), (27.5, '过重'),
(40.0, '肥胖'), (float('inf'), '非常肥胖')]
for top, status in top_status:
if BMI <= top:
put_text('你的 BMI 值: %.1f,身体状态:%s' % (BMI, status))
break
if __name__ == '__main__':
bmi()
效果如下:
三、造数平台实战
1.适用场景(目的)
例如:我想测试一个前台页面数据分页是否正常,一个分页默认最大20条数据,需要造20+条数据。常见的造数据方法如下:
- 手工一条条添加:效率太低、数据量大的情况下不推荐,也不现实;
- 编写SQL语句:执行SQL进行批量添加,前提是需要弄清楚表结构信息,掌握SQL语法;
- 请求接口来添加:这也是测试过程中最常用的方式,效率高、无需了解表结构,缺点是依赖较多、链路较长的时候比较难处理;
- 造数据平台:使用简单,无需清楚接口调用、表结构,但其背后仍然是请求接口或直接执行SQL语句;
可见,数据平台的方式能够便于不会编码的同学或其他项目组同事快速批量构造业务数据,辅助测试或系统演示。
2.设计思路
整个前台页面操作流程如下:
- 用户输入账号密码、登录系统,注意这里的系统不是造数据系统,而是要构造数据的业务系统;
- 选择环境,例如:开发环境、测试环境、预发布环境等;
- 选择数据类别,例如:乒乓球、篮球、羽毛球;
- 填写要构造数据的数量,可以是多条;
- 提交,等待构造结果。
其背后的实现逻辑如下:
- 用户登录,请求登录接口,获取到用户信息、企业信息等,供后续接口传参使用;
- 选择环境,选择不同的环境就会读取不同的配置;
- 选择数据类型,获取到数据类型参数,作为判断条件,以决定请求哪个接口;
- 填写数量,拿到数值,作为for循环次数,决定构造多少条数据;
- 最后提交,将各个参数传递给造数据接口,请求接口(接口构造数据背后仍执行的是SQL);
3.用到的pywebio相关的方法
设置网页标题
pywebio.session.set_env(title="RS造数平台")
 输入文本
输入文本
input.input(label="请输入登录手机号:")
设置图片
img = open('E:/RS_OTMS.png', 'rb').read()
output.put_image(img)
设置选择框
select = input.select(label="请选择环境", options=["测试环境", "开发环境"])
输出进度条、指定文本
进度条是以百分比的形式展示,0.4即40%
# 输出进度条为40%
output.set_processbar("当前进度", 0.4)
# 输出指定文本内容
output.put_text(f"登录成功,登录手机号为: {phone_number},当前企业类型为: 车队")
启动服务
- applications:要运行的函数名,注意不要带();
- host:设置的本地地址,不填的话默认0.0.0.0;
- port:本地端口号;
pywebio.start_server(applications=run, host='192.168.1.131', port=8888)
4.编码实现
导入相应库
- faker库用于生成数据,如姓名、手机号、身份证号码、银行卡号、地址等等;
- pywebio的input用于用户输入,output用于输出展示自定义内容到前台;
- MySQL是自定义的一个类,用于构造数据过程中和接口进行配合验证等使用;
- config是一个自定义的用于存放配置的配置文件;
- AuvDataProvider、RsCommon、RSResource、RSPool是业务的接口类;
from faker import Faker
import hashlib
import pywebio
from pywebio import input, output
import config
from execute_mysql import MySQL
from auv_data_provider import AuvDataProvider
from rs_common import RsCommon
from rs_resource import RSResource
from rs_pool import RSPool
定义获取输入信息的方法
例如:获取手机号、密码,用于登录,从而获取到用户信息,供后续接口传参使用。注意:
- 由于业务系统中有多个类型的企业,登录人属于某个企业下,所以为了实现可以给不同企业添加数据,此处的登录账号不宜写死;
- 每个账号的密码也不一定相同,所以此处也不宜写死;
- 由于前台输入的密码是普通明文字符,但在后台传参时用的是MD5加密后的密文,所以此处需要定义一个函数将密码转换为MD5格式,参数是前台获取到的手动输入的密码;
def get_phone_number():
"""获取手机号"""
phone_number = input.input(label="请输入登录手机号:")
return phone_number
def get_pwd():
"""获取登录密码"""
pwd = input.input(label="请输入登录密码")
return pwd
def get_numbers():
"""获取添加数据的数量"""
numbers = input.input(label="请填写数量:")
return int(numbers)
def transform_pwd_to_md5(pwd: str):
"""将密码转换为MD5格式"""
m = hashlib.md5(pwd.encode(encoding='utf-8'))
pwd_md5 = m.hexdigest()
return pwd_md5
定义添加数据的主函数
实际上就是将上述pywebio常用的方法同各个接口调用、按照上述的设计思路相结合。此处主要以快速实现功能为主,暂不考虑什么性能、代码精简度等,完整代码如下:
def run():
"""添加数据主函数"""
# 声明全局变量
global url, mysql, cpy_id, cpy_user_name, cpy_name, user_id
# 自定义背景图
img = open('E:/RS_OTMS.png', 'rb').read()
output.put_image(img)
# 初始化数据库等
product_id = "2022"
select = input.select(label="请选择环境", options=["测试环境", "开发环境"])
if select == "开发环境":
# 读取配置文件config的内容,不同环境读取不同配置
url = config.URLConf.RS_DEV_URL.value
mysql = MySQL(host=config.DBConfig.db_dev['host'], pwd=config.DBConfig.db_dev['pwd'],
ssh_host=config.DBConfig.db_dev['ssh_host'], ssh_pwd=config.DBConfig.db_dev['ssh_pwd'],
dbname=config.DBConfig.db_dev['dbname_rs'])
elif select == "测试环境":
url = config.URLConf.RS_TEST_URL.value
mysql = MySQL(host=config.DBConfig.db_test['host'], pwd=config.DBConfig.db_test['pwd'],
ssh_host=config.DBConfig.db_test['ssh_host'], ssh_pwd=config.DBConfig.db_test['ssh_pwd'],
dbname=config.DBConfig.db_test['dbname_rs'])
adp = AuvDataProvider()
fake = Faker("zh_CN")
common = RsCommon(product_id=product_id, url=url)
resource = RSResource(product_id=product_id, url=url)
pool = RSPool(product_id=product_id, url=url)
# 设置网页标题
pywebio.session.set_env(title="RS造数平台")
# 输入手机号
output.put_processbar("当前进度")
# 输入密码
phone_number = get_phone_number()
output.set_processbar("当前进度", 0.2)
# 密码转换为MD5
pwd = transform_pwd_to_md5(get_pwd())
output.set_processbar("当前进度", 0.4)
# 业务登录
login = common.login(username=phone_number, password=pwd)
user_id = login["b"]
user_info = common.get_user_info(user_id=user_id)
cpy_id = user_info["d"]["b"] # b节点为企业ID,h节点为企业全称,j节点为登录人手机号
cpy_type = user_info["d"]["l"] # 企业类型: 1-旭阳, 2-客商, 3-车队
output.put_text(login)
# 企业类型为1的企业添加数据
if cpy_type == 1:
output.put_text(f"登录成功,登录手机号为: {phone_number},当前企业类型为: 旭阳")
data_type = input.select("请选择添加数据的类型", ["公共池车辆", "公共池挂车", "公共池司机", "公共池押运员"])
output.set_processbar("当前进度", 0.6)
number = input.input("请输入要添加数据的数量: ")
output.set_processbar("当前进度", 0.8)
# 添加公共池运力数据逻辑
if data_type == "公共池车辆":
for i in range(int(number)):
car_name = adp.create_car()
add_car = pool.add_pool_car(cpy_id, user_id, car_name)
output.put_text("添加车辆成功,车辆id为%s" % (add_car["d"]))
output.put_text(f"新增完成,本次共新增{number}条数据!")
elif data_type == "公共池挂车":
for i in range(int(number)):
gua_name = adp.create_gua_car()
add_gua_car = pool.add_pool_gua_car(cpy_id, user_id, gua_name)
output.put_text("添加挂车成功,挂车id为%s" % (add_gua_car["d"]))
output.put_text(f"新增完成,本次共新增{number}条数据!")
elif data_type == "公共池司机":
for i in range(int(number)):
add_driver = pool.add_pool_driver(cpy_id, user_id)
output.put_text("添加司机成功,司机id为%s" % (add_driver["d"]))
output.put_text(f"新增完成,本次共新增{number}条数据!")
elif data_type == "公共池押运员":
for i in range(int(number)):
escort_driver = pool.add_pool_escort(cpy_id, user_id)
assert escort_driver["a"] == 200
escort_user_id = escort_driver['d']
output.put_text("添加押运员成功,押运员id为%s" % (escort_user_id))
output.put_text(f"新增完成,本次共新增{number}条数据!")
# 企业类型为2的企业添加数据
elif cpy_type == 2:
output.put_text(f"登录成功,登录手机号为: {phone_number},当前企业类型为: 车队")
data_type = input.select("请选择添加数据的类型", ["车辆", "挂车", "司机", "押运员", "运力"])
output.set_processbar("当前进度", 0.6)
number = input.input("请输入要添加数据的数量: ")
output.set_processbar("当前进度", 0.8)
# 添加车队运力数据逻辑
if data_type == "车辆":
for i in range(int(number)):
car_name = adp.create_car()
add_car = resource.add_car_simple_info(cpy_id, user_id, car_name, car_type=1)
output.put_text("添加车辆成功,车辆id为%s" % (add_car["d"]))
output.put_text(f"新增完成,本次共新增{number}条数据!")
elif data_type == "挂车":
for i in range(int(number)):
gua_name = adp.create_gua_car()
add_gua_car = resource.add_gua_simple_info(cpy_id=cpy_id, user_id=user_id, gua_name=gua_name,
gua_type=10, origin=1)
output.put_text("添加挂车成功,挂车id为%s" % (add_gua_car["d"]))
output.put_text(f"新增完成,本次共新增{number}条数据!")
elif data_type == "司机":
for i in range(int(number)):
driver_name = fake.name()
driver_phone = fake.phone_number()
driver_id_card = fake.ssn()
add_driver = resource.add_driver(user_id=user_id, cpy_id=cpy_id, driver_name=driver_name,
driver_phone=driver_phone, driver_id_card=driver_id_card,
driver_type=1)
output.put_text("添加司机成功,司机id为%s" % (add_driver["d"]))
output.put_text(f"新增完成,本次共新增{number}条数据!")
elif data_type == "押运员":
for i in range(int(number)):
escort_name = fake.name()
escort_phone = fake.phone_number()
escort_id_card = fake.ssn()
escort_driver = resource.add_escort(user_id=user_id, cpy_id=cpy_id, escort_name=escort_name,
escort_phone=escort_phone, escort_id_card=escort_id_card,
escort_type=1)
assert escort_driver["a"] == 200
escort_user_id = escort_driver['d']
output.put_text("添加押运员成功,押运员id为%s" % (escort_user_id))
output.put_text(f"新增完成,本次共新增{number}条数据!")
elif data_type == "运力":
for i in range(int(number)):
# 新增车辆
car_name = adp.create_car()
add_car_simple = resource.add_car_simple_info(cpy_id, user_id, car_name, car_type=1)
assert add_car_simple["a"] == 200
car_id = add_car_simple['d']
# 将车辆状态置为审核通过
mysql.execute_sql(f"UPDATE t_r_car_info SET review_status=1 WHERE id={car_id}")
# 新增司机
driver_name = fake.name()
driver_phone = fake.phone_number()
driver_id_card = fake.ssn()
add_driver = resource.add_driver(user_id=user_id, cpy_id=cpy_id, driver_name=driver_name,
driver_phone=driver_phone, driver_id_card=driver_id_card,
driver_type=1)
assert add_driver["a"] == 200
driver_user_id = add_driver['d']
# 将司机状态置为审核通过
mysql.execute_sql(
f"UPDATE t_r_driver_info SET review_status=1 WHERE user_id={driver_user_id}")
driver_id = mysql.execute_sql(f"SELECT id FROM t_r_driver_info WHERE user_id={driver_user_id}")[
0] # 查询司机user_id
# 新增运力绑定
add_trans = resource.add_transporter(cpy_id=cpy_id, user_id=user_id, car_id=car_id, driver_id=driver_id,
trans_name=car_name + driver_name + str(driver_phone))
assert add_trans["a"] == 200
output.put_text("新增运力成功,运力id为%s" % (add_trans["d"]))
output.put_text(f"新增完成,本次共新增{number}条数据!")
output.set_processbar("当前进度", 1)
if __name__ == '__main__':
pywebio.start_server(applications=run, host='192.168.1.131', port=8888)
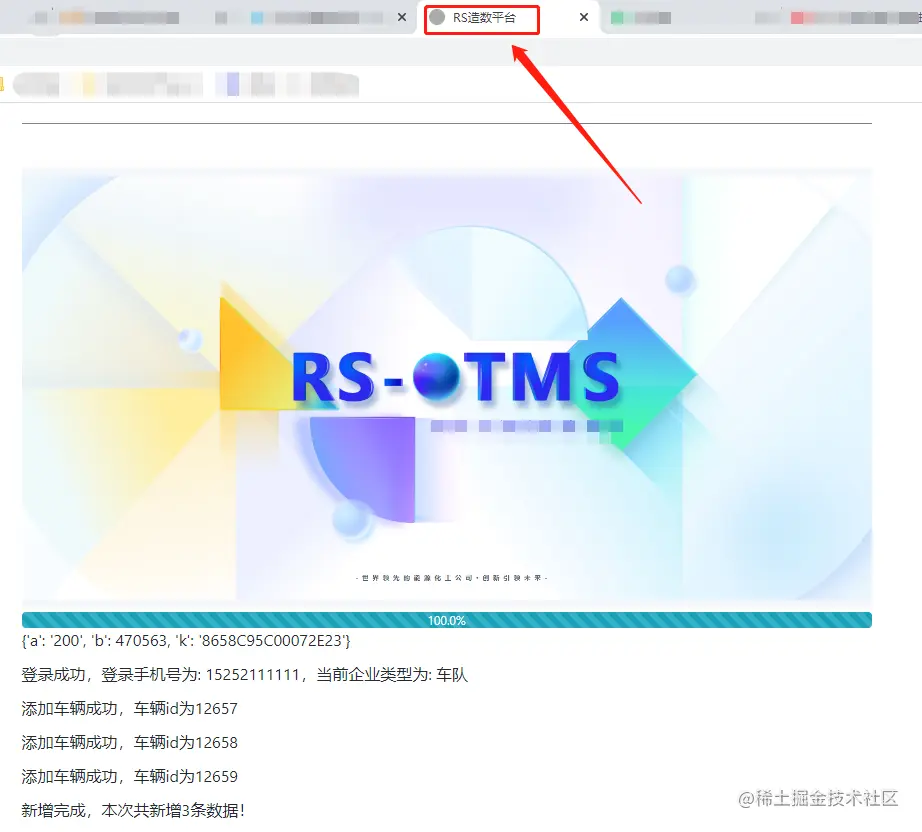
5.使用效果
总体效果如下:
小结
以上就是利用Python+pywebio库实现的一个简易数据构造平台的总体过程,Python语法是基础,再学习一些pywebio常用的方法即可。本次主要是为了快速实现平台并能够添加常用数据,并未过多关注设计模式、代码性能等等,也存在很多可以优化的地方!欢迎批评指正!
