Python爬虫实战之抖音高清无水印视频爬取:
抖音视频每次下载都有水印,有些博主的视频还不让下载,有了这段代码,告别视频下载限制,可批量下载,真正实现高清无水印下载!
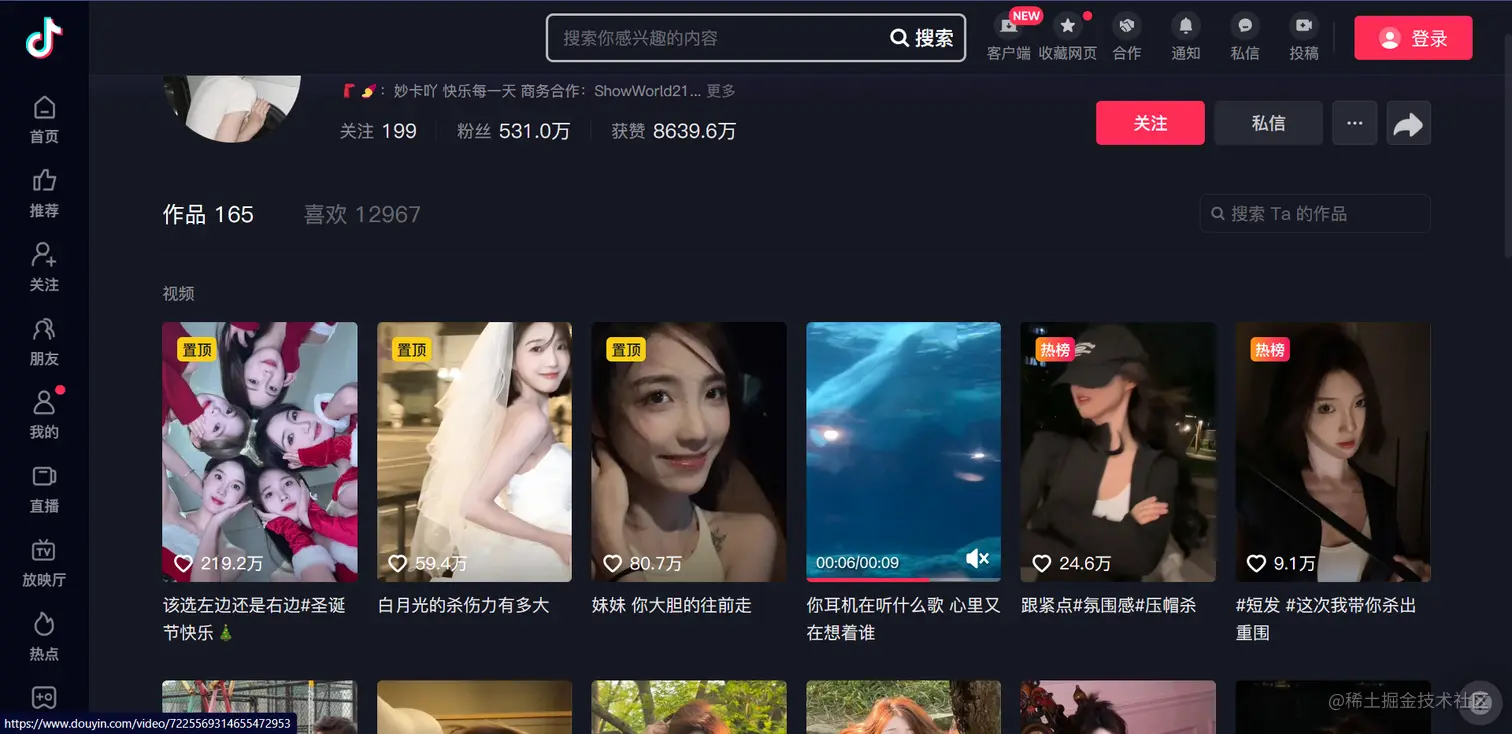
1.视频博主主页:
2.废话不多说直接上代码加分析:
2.1,由于都抖音的视频代码是有加密的,我们要先用 urllib 中的 parse进行解码,然后在进行爬取。
import re
from urllib import parse
from pprint import pprint
import requests
headers = {
'cookie': 'douyin.com; ttwid=1%7CvnHxU4BgJ7-qSRMx_DKS4CnmxKJjiykLIJczlOaNxpU%7C1673319020%7Cc1b17ddd2474cbad334d0b06944f79c556caf4c7af9247ca60582e35e32f20c5; douyin.com; passport_csrf_token=e2eb2207e4278322635124372723d9cd; passport_csrf_token_default=e2eb2207e4278322635124372723d9cd; ttcid=6885433160544141ab3b59ef00541af952; SEARCH_RESULT_LIST_TYPE=%22single%22; csrf_session_id=514efa9803be29aed2049a9da7bd0b0b; download_guide=%223%2F20230110%22; s_v_web_id=verify_lcpy5nx2_YNlIH5Ca_puWk_4yRO_BhYg_EWtnIbaGj4bv; __ac_nonce=063bd25be0073f791c489; __ac_signature=_02B4Z6wo00f01zEGKKAAAIDDsQTS4F5MSN8xJiwAALAHB3lZmp5AXGJ9-i9aO2DbSmexW8mBre3hTAo9ix7-2rWTjQH1y2UpUwtGx7V6.FKatXTb6ipxrgmwsF6zuriwLCElP7wyYBa7sVsi09; msToken=4ao0xwHIX9xGl4tmX7qh4t78bOK0ZYZ9dmgmLA6jxSKFHWjvfEh96NoLDNLh73f7n2MOFFQWnWouuMER0VLQ67FzGiSDdznvBTtC3U2akduYHtw47LK8; home_can_add_dy_2_desktop=%221%22; tt_scid=FjlK0oZvltNlD6hoFhc29EZMeMsMkl0LRTYc60imLt6BcNBP9TqAqQWXOKi0VLwXbabd; msToken=CyWVyFX_-qodaAgHgnUUvrK_g-T9EhN-5OKzFXzmS4HofE26UQ82j8ftSVlRWOVLGVdtHGQSm_xEsgIZBc-prNvVDiVOvV78cMpD5fcC7W5zgGPjWIhGMLKCNEHXGL4=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
data = {
"sec_uid": "MS4wLjABAAAAlwXCzzm7SmBfdZAsqQ_wVVUbpTvUSX1WC_x8HAjMa3gLb88-MwKL7s4OqlYntX4r",
"count": "21",
"max_cursor": "1111111111",
"aid": "1128",
"_signature": "1rexVRAciIE-bZMoZ46qv9a3sU",
"dytk": "96ad80961288263ad9d1cff2895d0636"
}
url = 'https://www.douyin.com/user/MS4wLjABAAAApKwDi1yiBXlcNrsZtUILmCJdvWR47OoFXu8zb0v-2iU?vid=7218502285100404005'
html = requests.get(url, headers=headers, data=data)
html_data = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script>', html.text, re.S)[0]
true = True
false = False
null = None
html_data = eval(parse.unquote(html_data))
2.2, 第二个麻烦就是视频的命名问题,由于博主每个视频的视频名字都有特殊符号,而文件的命名是不支持的,所以我们要对视频名字进行过滤,这里我用的是正则去过滤的。
video_title = re.findall('[\u4e00-\u9fa5|\d]',video_title1)
num_str = ''.join(str(x) for x in video_title)
3,全部代码展现:
import re
from urllib import parse
from pprint import pprint
import requests
headers = {
'cookie': 'douyin.com; ttwid=1%7CvnHxU4BgJ7-qSRMx_DKS4CnmxKJjiykLIJczlOaNxpU%7C1673319020%7Cc1b17ddd2474cbad334d0b06944f79c556caf4c7af9247ca60582e35e32f20c5; douyin.com; passport_csrf_token=e2eb2207e4278322635124372723d9cd; passport_csrf_token_default=e2eb2207e4278322635124372723d9cd; ttcid=6885433160544141ab3b59ef00541af952; SEARCH_RESULT_LIST_TYPE=%22single%22; csrf_session_id=514efa9803be29aed2049a9da7bd0b0b; download_guide=%223%2F20230110%22; s_v_web_id=verify_lcpy5nx2_YNlIH5Ca_puWk_4yRO_BhYg_EWtnIbaGj4bv; __ac_nonce=063bd25be0073f791c489; __ac_signature=_02B4Z6wo00f01zEGKKAAAIDDsQTS4F5MSN8xJiwAALAHB3lZmp5AXGJ9-i9aO2DbSmexW8mBre3hTAo9ix7-2rWTjQH1y2UpUwtGx7V6.FKatXTb6ipxrgmwsF6zuriwLCElP7wyYBa7sVsi09; msToken=4ao0xwHIX9xGl4tmX7qh4t78bOK0ZYZ9dmgmLA6jxSKFHWjvfEh96NoLDNLh73f7n2MOFFQWnWouuMER0VLQ67FzGiSDdznvBTtC3U2akduYHtw47LK8; home_can_add_dy_2_desktop=%221%22; tt_scid=FjlK0oZvltNlD6hoFhc29EZMeMsMkl0LRTYc60imLt6BcNBP9TqAqQWXOKi0VLwXbabd; msToken=CyWVyFX_-qodaAgHgnUUvrK_g-T9EhN-5OKzFXzmS4HofE26UQ82j8ftSVlRWOVLGVdtHGQSm_xEsgIZBc-prNvVDiVOvV78cMpD5fcC7W5zgGPjWIhGMLKCNEHXGL4=',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36'
}
data = {
"sec_uid": "MS4wLjABAAAAlwXCzzm7SmBfdZAsqQ_wVVUbpTvUSX1WC_x8HAjMa3gLb88-MwKL7s4OqlYntX4r",
"count": "21",
"max_cursor": "1111111111",
"aid": "1128",
"_signature": "1rexVRAciIE-bZMoZ46qv9a3sU",
"dytk": "96ad80961288263ad9d1cff2895d0636"
}
url = 'https://www.douyin.com/user/MS4wLjABAAAAkbFH1ja4Kou06A8fkc9VSE44qf7jOtAiU3ZC3vhrkWkZuwz1ieu9mjGig_IVAz1Q?vid=7223686394160450853'
html = requests.get(url, headers=headers, data=data)
html_data = re.findall('<script id="RENDER_DATA" type="application/json">(.*?)</script>', html.text, re.S)[0]
true = True
false = False
null = None
html_data = eval(parse.unquote(html_data))
video_data = []
for i in html_data['41']['post']['data']:
title = i['desc']
print(title)
src = None
for j in i['video']['bitRateList']:
src = f"https:{j['playAddr'][0]['src']}"
break
video_data.append((title, src))
print(video_data)
for video_title1, video_url in video_data:
try:
video_stream = requests.get(video_url, stream=True)
except:
pass
file_size1 = int(video_stream.headers['Content-Length']) / 1024 / 1024
video_title = re.findall('[\u4e00-\u9fa5|\d]',video_title1)
num_str = ''.join(str(x) for x in video_title)
print(video_title1, video_url )
s = 0
with open(f"美女视频\{num_str}.mp4", 'wb') as data:
for i in video_stream.iter_content(chunk_size=1024):
s += 1024
value = float('%.2f' % (s / 1024 / 1024))
ratio = value / file_size1 * 100
print("\r{}MB/{}MB {:.2f}%[{}>{}]".format(int(file_size1), int(value), ratio, int(int(ratio) / 5) * '█',
int((100 - int(ratio)) / 5) * "."), end='')
data.write(i)
print(f'{video_title}写入完成')
"""
GET http://api2.主机地址.com/api/video/lists
7153963547314130184
'http://v26-web.douyinvod.com/e809403afd163e97c22089c6d5bf8db2/63496810/video/tos/cn/tos-cn-ve-15c001-alinc2/417055cc3a3c4e80b56b684eb0b30f5c/?a=6383&ch=10010&cr=3&dr=0&lr=all&cd=0%7C0%7C0%7C3&cv=1&br=1446&bt=1446&cs=0&ds=3&ft=rVWEerwwZRfusd~IVYQqYlagrPJneyS.srV3-InG-mgtPni7t&mime_type=video_mp4&qs=0&rc=PDg5ZTY5OjlnZzNpOmczNkBpampqazk6ZnB5ZzMzNGkzM0BiNjZhYmBhNWAxMV5iNTRfYSMubG0ucjRfajBgLS1kLS9zcw%3D%3D&l=2022101420454401020915813347D05A41'
https://v26-web.douyinvod.com/47668617774e7c9b120cf2e8d8403589/63496810/video/tos/cn/tos-cn-ve-15c001-alinc2/b01632bfa77f49cebc1987eb3d43a415/?a=6383&ch=10010&cr=3&dr=0&lr=all&cd=0%7C0%7C0%7C3&cv=1&br=2222&bt=2222&cs=0&ds=4&ft=rVWEerwwZRfusd~IVYQqYlagrPJneyS.srV3-InG-mgtPni7t&mime_type=video_mp4&qs=0&rc=MzU8ZTlmaTM0PDs1aDs8NkBpampqazk6ZnB5ZzMzNGkzM0BjNWEvYTQvX2AxYS41NjYuYSMubG0ucjRfajBgLS1kLS9zcw%3D%3D
http://v26-web.douyinvod.com/de70eba64d7d340908cf18a662324bdc/63496c60/video/tos/cn/tos-cn-ve-15c001-alinc2/b01632bfa77f49cebc1987eb3d43a415/?a=6383&ch=0&cr=0&dr=0&cd=0%7C0%7C0%7C0&cv=1&br=2222&bt=2222&cs=0&ds=4&ft=rVWEerwwZRn0seao1PDS6kFgAX1tGzK5eS9eFE.4w2D12ni7t&mime_type=video_mp4&qs=0&rc=MzU8ZTlmaTM0PDs1aDs8NkBpampqazk6ZnB5ZzMzNGkzM0BjNWEvYTQvX2AxYS41NjYuYSMubG0ucjRfajBgLS1kLS9zcw%3D%3D
http://v3-web.douyinvod.com/bf0a8085aa4baba1d98a6f4d4078c2a8/63496810/video/tos/cn/tos-cn-ve-15c001-alinc2/b01632bfa77f49cebc1987eb3d43a415/?a=6383&ch=10010&cr=3&dr=0&lr=all&cd=0%7C0%7C0%7C3&cv=1&br=2222&bt=2222&cs=0&ds=4&ft=rVWEerwwZRfusd~IVYQqYlagrPJneyS.srV3-InG-mgtPni7t&mime_type=video_mp4&qs=0&rc=MzU8ZTlmaTM0PDs1aDs8NkBpampqazk6ZnB5ZzMzNGkzM0BjNWEvYTQvX2AxYS41NjYuYSMubG0ucjRfajBgLS1kLS9zcw%3D%3D&l=2022101420454401020915813347D05A41
http://www.douyin.com/aweme/v1/play/?video_id=v0200fg10000cd3vmmbc77u61hpgog1g&line=0&file_id=1399988e12d849c1b02f7cd62bd982f0&sign=245bc79d27e98999571b7eeff063bbc5&is_play_url=1&source=PackSourceEnum_PUBLISH&aid=6383
http://p9-pc-sign.douyinpic.com/tos-cn-p-0015/4afaeb545fdd42598ab1633e8d952b4a_1665661953~tplv-dy-cropcenter:323:430.jpeg?biz_tag=pcweb_cover&from=3213915784&s=PackSourceEnum_PUBLISH&sc=cover&se=true&sh=323_430&x-expires=1981108800&x-signature=%2FFAvX4LX%2FzMFnBbY0fBAW138c80%3D
/www.douyin.com/aweme/v1/play/?video_id=v0d00fg10000ca76rjjc77u13hu4ppug&line=0&file_id=5b9be12c3d1a462d9caae4896ce57401&sign=0909507d54655cccf91cc0556c692746&is_play_url=1&source=PackSourceEnum_PUBLISH&aid=6383',
'www.iesdouyin.com/share/user/MS4wLjABAAAA05e5C70xEm5KJ9L8Ol8oTroLVd0JZ21FTmRZ2buarIY?from_ssr=1&did=MS4wLjABAAAAf40PeRMtsSW1S6_WQX_Ot7f_AaCUVvZx9BxfzUtR0vD7l2JiqXIrQt75Z3S3UuLD&iid=MS4wLjABAAAANwkJuWIRFOzg5uCpDRpMj4OX-QryoDgn-yYlXQnRwQQ&with_sec_did=1&sec_uid=MS4wLjABAAAA05e5C70xEm5KJ9L8Ol8oTroLVd0JZ21FTmRZ2buarIY',
//v26-web.douyinvod.com/a272861f408c3258af56fadd9656f116/63bd46dc/video/tos/cn/tos-cn-ve-15c001-alinc2/oIZjBzeEDGw8VtLARgHQuwmt9dhenAg1Ab6onN/?a=6383&ch=10010&cr=3&dr=0&lr=all&cd=0%7C0%7C0%7C3&br=897&bt=897&cs=0&ds=3&ft=bvTKJbQQqU-~fJo0ao0OqY8hFgpi6Fo.~jKJ6mk3v.0P3-A&mime_type=video_mp4&qs=0&rc=Zmg4ZTtpZGg1Zzo7N2g7Z0BpM212dGc6ZmtzaDMzNGkzM0AvLzAtXmA0NmAxLWMvMGNjYSNwaTBgcjRnYnBgLS1kLWFzcw%3D%3D&l=20230110180646D528E0358D989801C155&btag=10000'},
device_platform: webapp
aid: 6383
channel: channel_pc_web
sec_user_id: MS4wLjABAAAA6PA7d7YNDSVxoU_4XTy9m54-cheKcBPEBnkXI6x81NeFNps2a70qJsZH4iHRSRIj
max_cursor: 1643627569000
locate_query: false
show_live_replay_strategy: 1
count: 10
publish_video_strategy_type: 2
0
"""
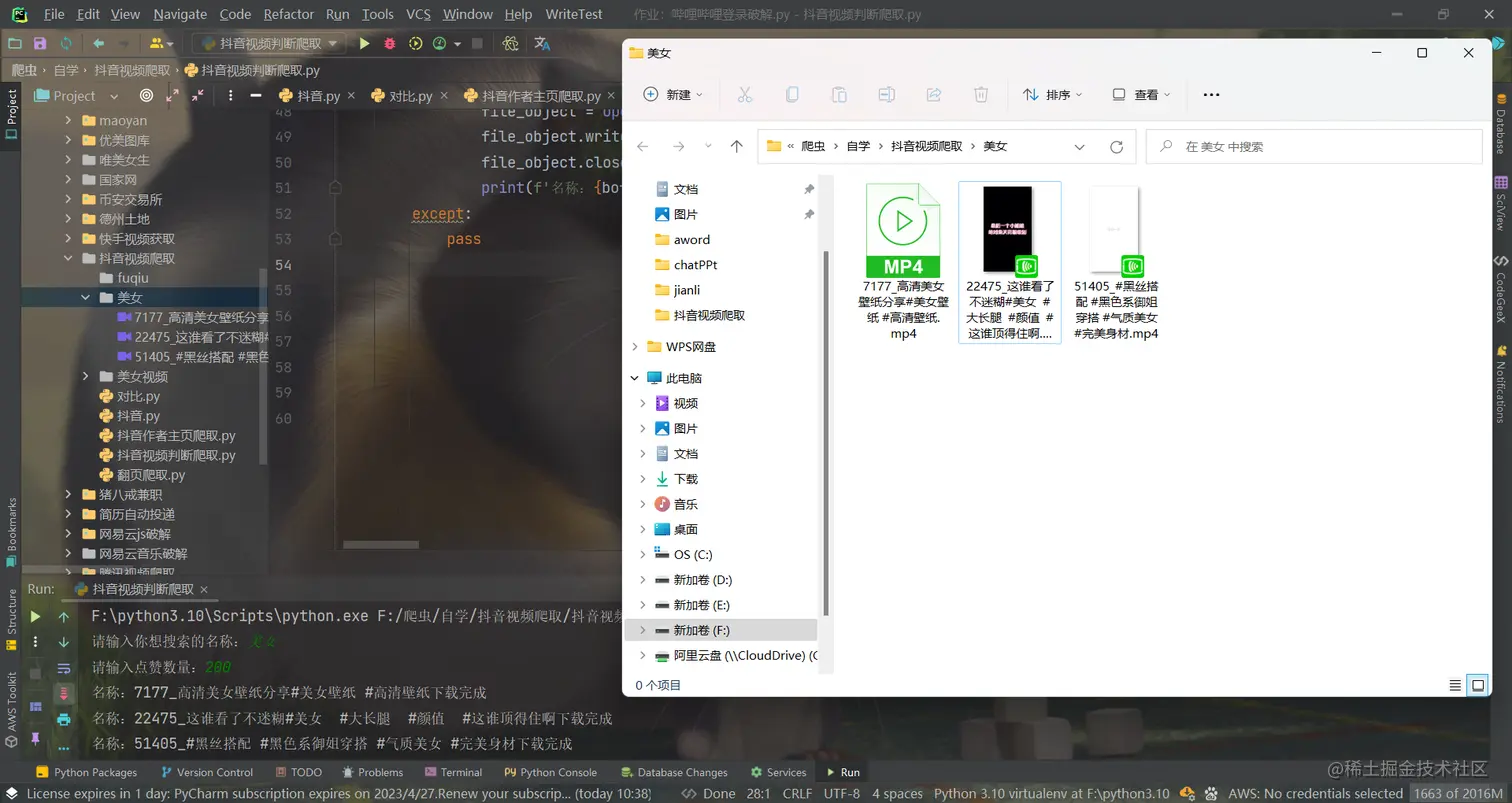
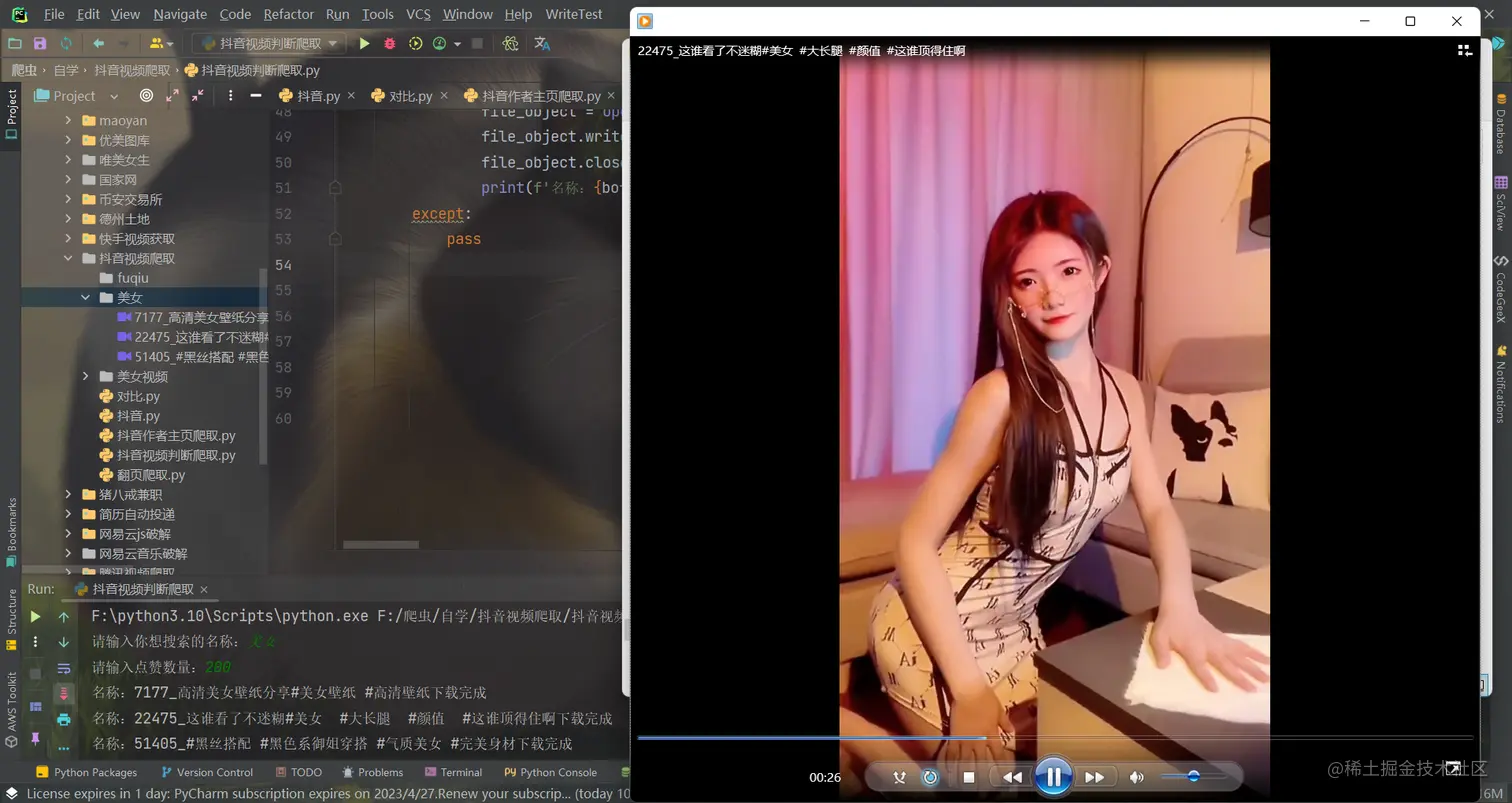
4,爬取展示效果:
2,抖音视频美女判断爬取:
1,这里使用抖音的检索功能,然后爬取符合我们要求的视频,并获取保存下来。
2, 全部代码展现:
import requests
from pprint import pprint
import os
import re
url = 'https://www.douyin.com/aweme/v1/web/general/search/single/'
headers = {
"Cookie": "ttwid=1%7CBK2p53A197CIWEGrDH5gA19A3p84dQjC5acbGGPSphU%7C1678195316%7C301754a19a8b5cf7a87b648d2543aa5ee29b9340023cc0f2582d86288c71ce8a; s_v_web_id=verify_leya5uxw_m8TG03a9_EwOm_4NQU_8cbo_LYlbbp0NkJ7o; passport_csrf_token=4166f3687cc7a7986caa9c325e908a1c; passport_csrf_token_default=4166f3687cc7a7986caa9c325e908a1c; SEARCH_RESULT_LIST_TYPE=%22single%22; download_guide=%222%2F20230307%22; xgplayer_user_id=160327433710; douyin.com; strategyABtestKey=%221678245442.754%22; VIDEO_FILTER_MEMO_SELECT=%7B%22expireTime%22%3A1678850242765%2C%22type%22%3A1%7D; csrf_session_id=3d9e68b36ad5232858f8bcfca516008c; bd_ticket_guard_client_data=eyJiZC10aWNrZXQtZ3VhcmQtdmVyc2lvbiI6MiwiYmQtdGlja2V0LWd1YXJkLWNsaWVudC1jc3IiOiItLS0tLUJFR0lOIENFUlRJRklDQVRFIFJFUVVFU1QtLS0tLVxyXG5NSUlCRGpDQnRRSUJBREFuTVFzd0NRWURWUVFHRXdKRFRqRVlNQllHQTFVRUF3d1BZbVJmZEdsamEyVjBYMmQxXHJcbllYSmtNRmt3RXdZSEtvWkl6ajBDQVFZSUtvWkl6ajBEQVFjRFFnQUUyckNPQXRLd29NYlI0eVN0L04yeFJ4WjFcclxuWWJVOXdYUWFwcG9xT3FUZ29wbTFqbzI3eGwyQmFxVDFFYWdEMnV0ZDNQdXBsNVJxelJqMXZkeWxvRnU5Q3FBc1xyXG5NQ29HQ1NxR1NJYjNEUUVKRGpFZE1Cc3dHUVlEVlIwUkJCSXdFSUlPZDNkM0xtUnZkWGxwYmk1amIyMHdDZ1lJXHJcbktvWkl6ajBFQXdJRFNBQXdSUUloQUtMblB5OENsY2l0a2IxRDBmYzRlcVRWNjNDWnIyb2Rla0lvL1F2aWMrS2RcclxuQWlBa0huSTlIbGtaaGcvOFFORUJDYXFFeHNHandZMzZHMk00dHJZTnluSTJsQT09XHJcbi0tLS0tRU5EIENFUlRJRklDQVRFIFJFUVVFU1QtLS0tLVxyXG4ifQ==; msToken=UP9W0jpOaYm7ycv2EFHyx240HSL1xLc02lOBquYxqrKfW55wgj5H63ZpbUdfDR5IatBf3bMZWC_Nw192B7rGMY4z47OeqBX5S3EeDMOQYiGyEltj-t03yg==; __ac_nonce=06407fe480012e4f532fa; __ac_signature=_02B4Z6wo00f01LI9B-wAAIDBR0LtcE9ytMCyHQNAAEiNcIrqPEC01kmlN7BfJOuHiDZYqPuofWutxf2WPlsCKLH3yk3tAvR7NkRZc54gDeF9y7N1rYXTBy4ZalmbX8pN76-ivVfzJ8sZeUy2dd; tt_scid=-pI0H.3c5NeTmMt1AANbdwdC.g0swd6WhF6kI.1qXIsiTsNv1v9UyyNutg7iqezk0fa1; msToken=1Uj4907rZHA9WavFbdijUUY9v510qtTlKXaI0gL1o5bmRRcBK3Rc2AUygY4KlydTgcrTmStDFsDB24p2FPGQ6h0Q7q77sQUEv3VLGIsB3cMSrDMrPAbkjA==; home_can_add_dy_2_desktop=%220%22",
"referer": "https://www.douyin.com/search/%E5%84%BF%E5%AD%90?aid=165d20aa-17b3-4b63-b831-645b2eb7f064&publish_time=0&sort_type=0&source=normal_search&type=general",
"User-Agent": "user-agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36",
}
search = input('请输入你想搜索的名称:')
dian_zhan = int(input('请输入点赞数量:'))
while True:
params = {
'platform': 'PC',
'aid': '6383',
'channel': 'aweme_general',
'type': '4g',
'time': '50',
'keyword': search,
'source': 'normal_search',
'search': '0',
'id': '',
'offset': '0',
'count': '10',
}
html = requests.get(url=url, headers=headers, params=params)
json_url = html.json()
for i in json_url['data'][:-1]:
try:
url = i['aweme_info']['video']['play_addr']['url_list'][0]
name = i['aweme_info']['desc']
aweme_id = i['aweme_info']['aweme_id']
bofangliang = i['aweme_info']['statistics']['digg_count']
if bofangliang > dian_zhan and search in name:
if not os.path.exists(f'./{search}'):
os.mkdir(f'./{search}')
video_name = name
video_name = video_name.replace('\n', ' ')
video_name = re.sub(r'[\/:*?"<>|]', '-', video_name)
resp = requests.get(url)
file_object = open(f'./{search}/{bofangliang}_{video_name}.mp4', mode='wb')
file_object.write(resp.content)
file_object.close()
print(f'名称:{bofangliang}_{video_name}下载完成')
except:
pass
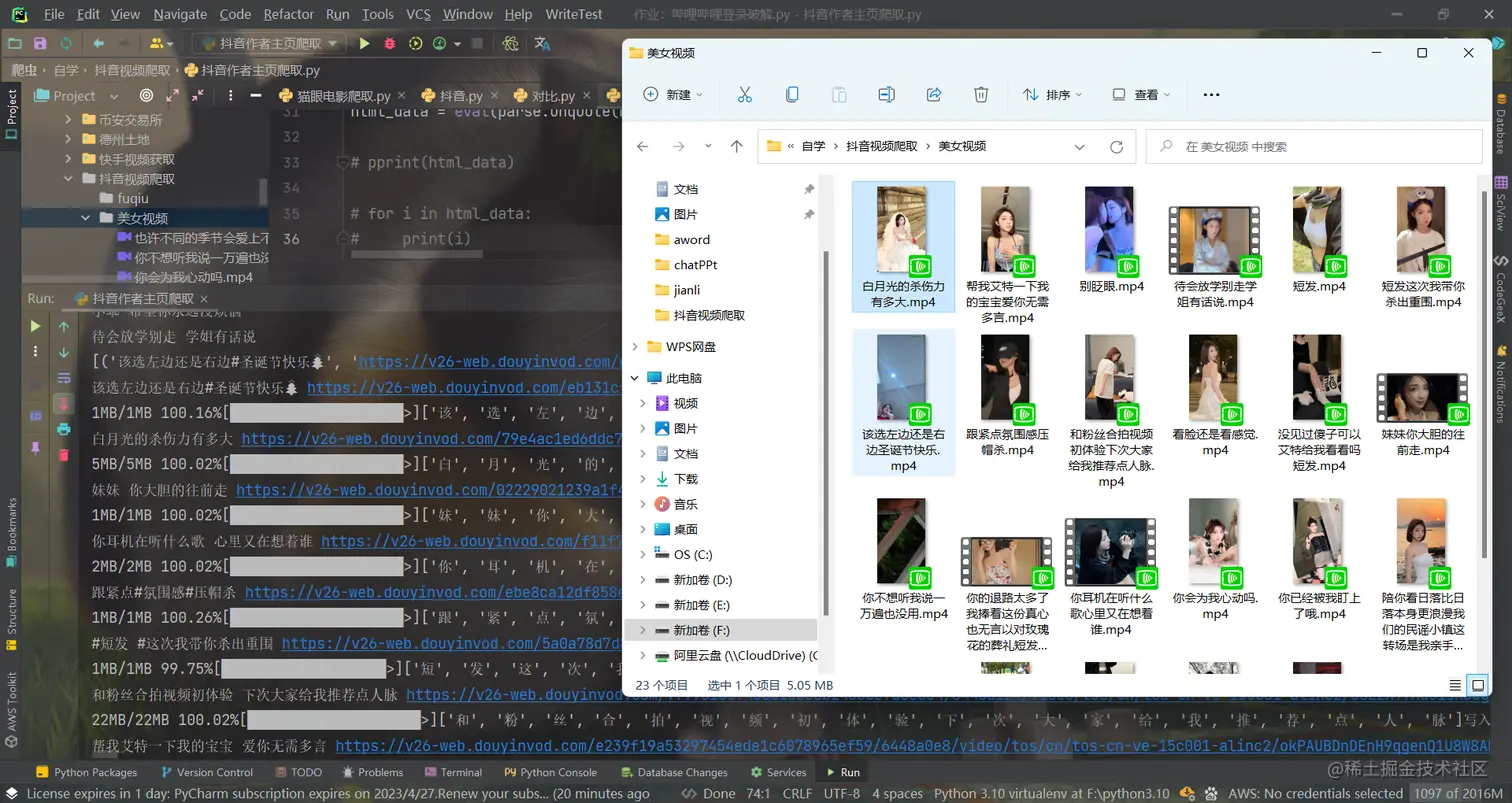
3,爬取视频展示: