

计算机视觉是机器学习和人工智能的一个跨学科领域,涉及到自动提取、分析和理解图像中的有用信息。随着最近技术的进步,有关图像和视频的数字内容出现了爆炸性增长。在计算机视觉领域,与人类相比,理解和分析图像是计算机的一个关键问题。
一个图像由最小的不可分割的片段组成,称为像素,每个像素都有一个强度,通常称为像素强度。每当我们研究一幅数字图像时,它通常有三个颜色通道,即红-绿-蓝通道,俗称 "RGB "值。为什么是RGB?因为人们已经看到,这三个通道的组合可以产生所有可能的颜色板块。每当我们处理彩色图像时,图像是由多个像素组成的,每个像素由RGB通道的三个不同数值组成。
这些数据集要求我们进行微妙的区分,因为这些图像在特定类别之间有些密切的联系。例如,"汽车 "类下的一些图像可能被误解为"卡车 " 类下的图像*。* 一个典型的前馈神经网络将无法检测到这些微妙的区别,并会导致相应的模型在数据集上的表现不尽人意。这就是本项目的主要方法;卷积神经网络的作用。
在卷积操作中,与前馈操作不同,我们不对每个像素应用单独的不同权重。另一方面,我们使用一个叫做内核的东西,它基本上是一个3x3的权重矩阵。二维卷积是一个相当简单的操作:我们从一个内核开始,如前所述,它是一个简单的权重小矩阵。内核在二维输入数据上 "滑动",与当前输入的部分进行元素相乘,然后将结果相加,形成一个单一的输出像素。
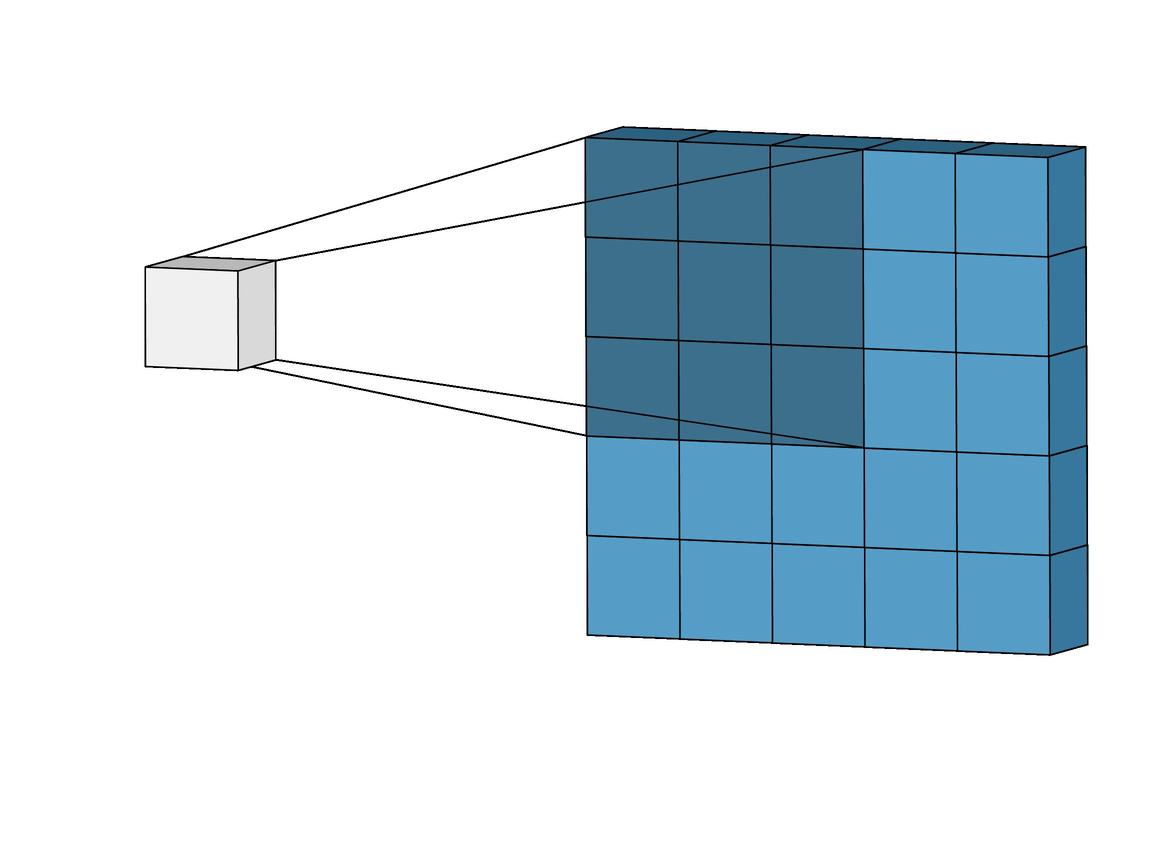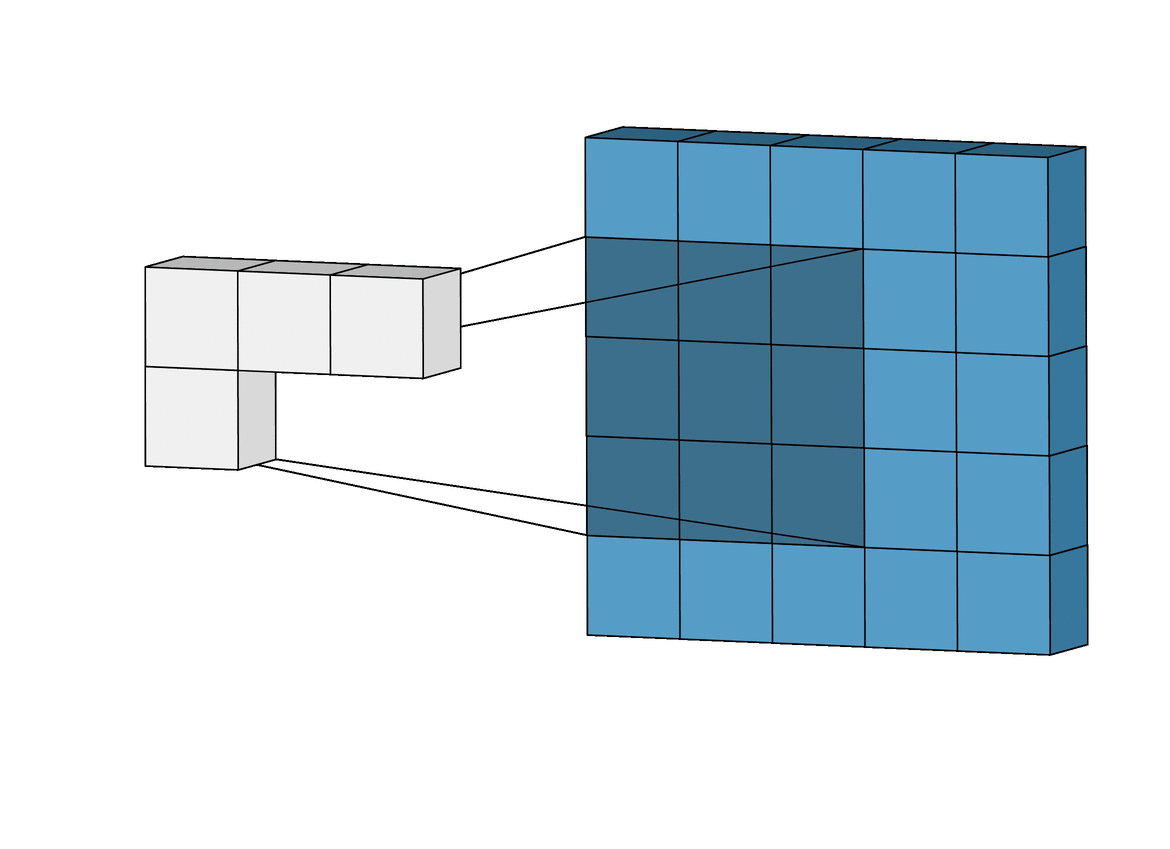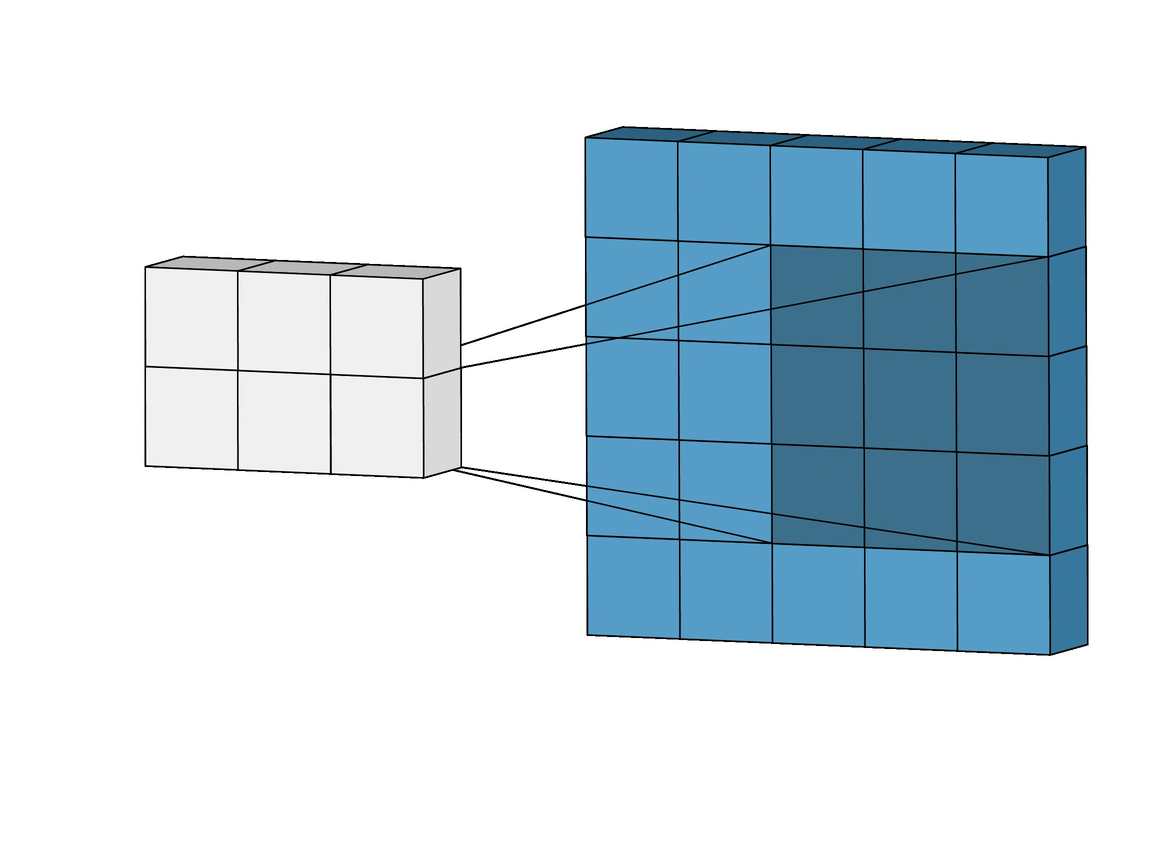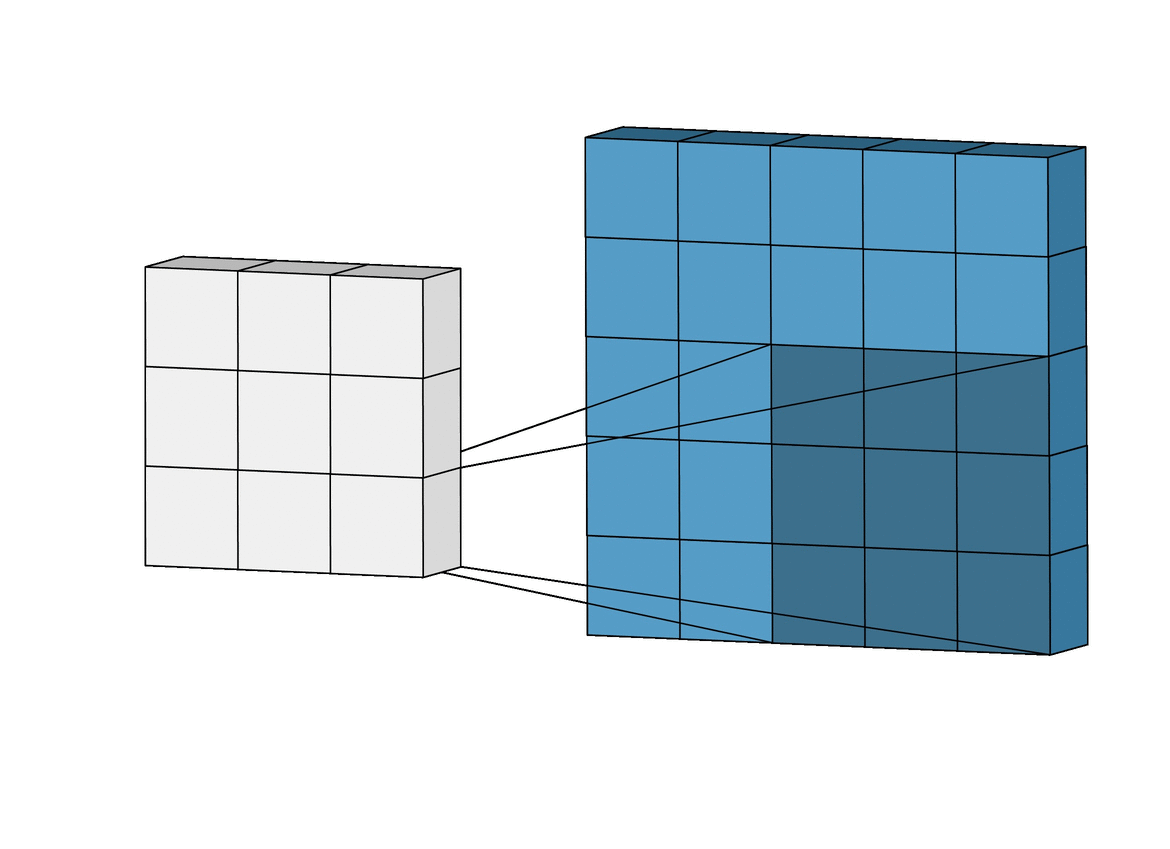
内核对它滑过的每个位置都重复这一过程,将一个二维特征矩阵转换成另一个二维特征矩阵,因此不会丢失空间特征。输出特征本质上是位于输入层上输出像素同一位置的输入特征的加权和(权重是内核本身的值)。这属于 "特征提取"。
一个输入特征是否在这个大致相同的位置,由它是否在产生输出的核的区域内决定。这意味着内核的大小决定了在产生新的输出特征时,有多少(或多少)输入特征被结合起来。卷积层中使用了两种技术:Padding和Strides:
在滑动过程中,边缘基本上被修剪掉了,将5x5的特征矩阵转换为3x3的矩阵。边缘上的像素永远不会在核的中心,因为这些边缘之外没有任何东西可以让核延伸到。这就导致了输出与输入的大小不同,这并不理想;因为我们希望输出的大小与输入的大小一致。这个问题可以通过填充的概念来解决。填充的本质是用额外的、假的像素(通常值为0)来填充边缘。这使得原始边缘像素在滑动时位于核的中心,从而产生与输入相同大小的输出。

卷积神经网络的一个普遍现象是,当需要一个比输入尺寸更小的输出时,当增加通道数时,空间维度的尺寸就会减少。做到这一点的一个方法是使用stride。Stride基本上包括跳过内核中的一些滑动位置。一个1的跨度意味着在1个像素之间滑动。跨度为2意味着滑过2个像素,以此类推。这也可以用池子来实现。

上面讨论的方法只处理了图像张量中的单通道输入。然而,当处理多通道即3个通道时,随着我们对卷积网络的深入,通道的数量逐渐增加。对于一个有1个通道的图像张量来说,滤波器和内核这两个词是可以互换的,因为它们在那个特定的环境中指的是同一个概念。在一般情况下,它们是不同的实体。
滤波器指的是内核的集合,一个内核负责每一个输入通道,而且每个内核都是唯一的。在卷积层中,一个滤波器将只产生一个输出。每个内核在各自的输入通道上滑动,产生每个通道的处理版本。一些内核的权重可能比其他的强,表明某个输入通道比其他通道有更大的影响。
每个输入通道的处理版本然后加在一起代表一个通道,因此过滤器作为一个整体产生一个整体输出通道。这适用于任何数量的过滤器的所有情况。一个滤波器将产生一个具有自己独特内核集的输出。然后将它们串联在一起,产生整体输出。
当我们进入一个又一个卷积层时,这个过程不断重复。除了卷积层,我们还使用了一个叫做最大池的层,它逐步减少每个卷积层的输出张量的高度和宽度。我们使用一个2x2的最大池。
当我们不断堆叠内核时,每个内核不断学习它们的输出,它们所包含的信息规格也越来越丰富;这基本上就是卷积神经网络的工作方式。在卷积层之后,我们将输出特征图通过一个函数,该函数将输出特征图平铺成一个向量。
医学图像分析是卷积神经网络(CNN)在医疗领域的最重要应用之一。它涉及使用深度学习算法来分析医疗图像,如X射线、CT扫描、MRI扫描和超声波图像。其目的是协助医疗保健专业人员完成诸如疾病诊断、肿瘤检测、治疗计划和监测疾病进展等任务。以下是CNN如何用于医学图像分析的一些例子:
- 疾病诊断:为了实现疾病诊断的CNN,第一步是获得一个大型的有注释的医学图像数据集,包括有和没有感兴趣的疾病的图像。下一步是对图像进行预处理,使其正常化并准备输入CNN。然后可以使用注释过的图像训练CNN,以学习疾病检测的相关特征。一旦CNN接受了训练,它就可以被用来将新的医疗图像分类为疾病的阳性或阴性。
- 肿瘤检测:为了实现肿瘤检测的CNN,第一步是获得一个大型的有注释的医学图像数据集,包括有肿瘤和无肿瘤的图像。下一步是对图像进行预处理,以提高对比度和减少噪音。然后,可以使用注释过的图像训练CNN,以学习肿瘤检测的相关特征。一旦CNN接受了训练,它就可以被用来识别新的医疗图像中可能表明存在肿瘤的异常组织区域。
在所有这些应用中,重要的是使用验证和测试数据集仔细评估CNN的性能,以确保它是准确和稳健的。同样重要的是,要确保CNN是透明的和可解释的,以便医疗保健专业人士能够理解CNN是如何得出其诊断或建议的。这可以通过使用可解释的人工智能技术来实现,如注意机制或突出显示图像中对CNN的决定最重要的区域。
总之,近年来,CNN已经成为图像处理的一个重要工具,并被用来在广泛的任务中取得最先进的性能。CNN的结构以及训练和正则化技术可以针对不同的应用进行定制,使其成为解决图像处理中复杂问题的多功能工具。
